Vortrag bei Microsoft Research zum Thema Diffusion-based Sampling
Während seines Forschungsaufenthalts in Cambridge, Massachusetts und im Anschluss an seinen Vortrag am Massachusetts Institute of Technology, präsentierte Dr. Lorenz Richter unsere aktuellen Arbeiten im Bereich Diffusion-based Sampling auch dem Team von Microsoft Research New England (MSR-NE).
Das Seminar mit dem Titel „A non-Markovian approach to diffusion-based sampling“ befasste sich mit den Herausforderungen beim Sampling aus hochdimensionalen, unnormierten Dichten – eine zentrale Aufgabe in wissenschaftlichen Bereichen, in denen häufig keine Ground-Truth-Daten zur Verfügung stehen.
In seinem Vortrag präsentierte Lorenz Einblicke in unsere neueste Forschung und stellte dabei insbesondere den Bridge Matching Sampler (BMS) vor. Dieses Framework generalisiert bisherige Matching-Ziele als spezielle Formen von Fixpunkt-Iterationen, die auf der Nelson-Relation basieren.
Das vollständige Paper wurde vor Kurzem hier veröffentlicht.
Ein herzlicher Dank geht an Carles Domingo-Enrich und das Team von Microsoft Research für die Einladung und den fachlichen Austausch.
Die Gruppe bei MSR-NE konzentriert sich insbesondere auf Generative Modeling und die wachsenden Verbindungen zur Bild-, Video- oder Textgenerierung, aber auch auf Entwicklungen in den Bereichen Fine-tuning, Alignment oder wissenschaftliche Simulationen.
Den aufgezeichneten Vortrag können Sie sich hier ansehen.
Wie immer sind die Erkenntnisse aus dem Paper das Ergebnis einer großartigen Zusammenarbeit. Ein Dank geht daher auch an Denis Blessing, Julius Berner, Egor Malitskiy und Gerhard Neumann.
Präsentation zur diffusionsbasiertem Sampling am MIT
Letzte Woche hatte Dr. Lorenz Richter die Gelegenheit, das Center for Computational Science & Engineering (CCSE) am Massachusetts Institute of Technology zu besuchen, um unsere neuesten Forschungsergebnisse zum Thema diffusionsbasiertes Sampling zu diskutieren.
Die von Youssef Marzouk geleitete Gruppe ist führend in der Entwicklung neuartiger Methoden für die Quantifizierung von Unsicherheiten, inverse Probleme und statistisches Machine Learning - Bereiche, die eng mit unserer Arbeit bei dida verbunden sind.
Im Mittelpunkt der Präsentation und der anschließenden Diskussion stand die Frage, wie kontrollierte Diffusionsprozesse genutzt werden können, um aus komplexen Zielverteilungen zu sampeln.
Wir diskutierten:
Mathematische Ansätze, die diffusionsbasiertes Sampling als ein Problem der stochastischen optimalen Steuerung (Stochastic Optimal Control) beschreibbar machen.
Unsere Forschungserfolge zur Verbesserung der Konvergenz an wissenschaftlichen Anwendungen in hohen Dimensionen.
Synergien zwischen generativer KI und klassischer Physik, um inverse Probleme robuster zu lösen.
Es war eine tolle Erfahrung, die mathematischen Grundlagen der KI mit einer so talentierten Gruppe von Forschenden zu erörtern. Der Ideenaustausch zwischen der europäischen KI-Landschaft und den technologischen Ökosystemen in Cambridge ist weiterhin eine große Inspirationsquelle für unsere eigenen Projekte.
Ein herzlicher Dank gilt Youssef Marzouk für die Einladung sowie Joanna Zou für die exzellente Organisation und den freundlichen Empfang!
Wir freuen uns darauf, den Dialog fortzusetzen.
Über 35.000 monatliche Downloads für unseren RAG-Benchmark-Datensatz T²-RAGBench
Unser neuer Benchmark-Datensatz für RAG-Systeme, T²-RAGBench, erfreut sich in der Machine-Learning-Community großer Beliebtheit und wird derzeit mehr als 35.000 Mal pro Monat heruntergeladen. Der Datensatz wurde in Zusammenarbeit mit dem Hub of Computing and Data Science (HCDS) der Universität Hamburg entwickelt und schließt eine wichtige Lücke bei der Evaluation von KI-Systemen, die mit der Analyse komplexer Finanzdaten beauftragt sind.
Die Lösung für Ambiguität in Retrieval-Schritten
Standard-Datensätze für Frage-Antwort-Systeme betrachten oft Situationen, in denen die KI im Voraus mit dem richtigen Kontext versorgt wird. In diesen Umgebungen sind vage Abfragen wie „Wie hoch war der Netto-Cashflow?“ funktionsfähig, da der Umfang begrenzt ist. In produktionsreifen RAG-Systemen, die Tausende von Dokumenten verwalten, führt eine solche Ambiguität jedoch zu Störungen bei der Informationsgewinnung. Es können mehrere Dokumente als relevant erscheinen, da sie alle Cashflow-Werte angeben, nicht jedoch vom speziell in dieser Situation interessanten Unternehmen, was es für Entwickler unmöglich macht, die Genauigkeit der Suche zu überprüfen.
T²-RAGBench führt kontextunabhängige Fragen ein, die Entitäten, Daten und Metriken spezifizieren und sicherstellen, dass jede Abfrage genau auf ein Ground-Truth-Dokument verweist.
Merkmale des Datensatzes und Methodik
Der im Rahmen des GENIAL4KMU-Projekts entwickelte Datensatz umfasst mehrere technische Attribute, die für die strenge Prüfung moderner KI entwickelt wurden. Seine Grundlage bildet ein umfangreicher Korpus von 23.088 Frage-Antwort-Paaren, die aus mehr als 7.300 realen Finanzberichten stammen und den für ein statistisch signifikantes Benchmarking erforderlichen Umfang bieten.
Um häufige Fehler bei der Informationsgewinnung zu beheben, behandelte das Team die Daten: Mehrdeutige Benutzeranfragen wurden systematisch in in sich geschlossene, präzise Fragen umformuliert. Dadurch wird sichergestellt, dass die Suche anhand eines einzigen, spezifischen Referenzdokuments überprüft werden kann und nicht anhand einer Reihe von oberflächlich relevanten Ergebnissen.
Darüber hinaus führt der Benchmark multimodale Komplexität ein, indem er von den Modellen anspruchsvolle numerische Schlussfolgerungen verlangt. Im Gegensatz zu Datensätzen, die sich ausschließlich auf Prosa konzentrieren, fordert T²-RAGBench die Systeme heraus, Informationen aus unstrukturierten narrativen Texten und komplexen Markdown-Tabellen zu synthetisieren. Erste grundlegende Erkenntnisse des Forschungsteams unterstreichen die Schwierigkeit dieser Aufgabe und identifizieren Hybrid BM25 – eine Kombination aus Stichwort- und semantischer Suche – als die effektivste Suchstrategie für die Navigation in diesem spezifischen Finanzdatenformat.
Zusammenarbeit
Das Projekt stellt eine erfolgreiche Brücke zwischen Industrie und Wissenschaft dar. Zu den wichtigsten Mitwirkenden der Initiative gehören Jan Strich, Enes Kutay İşgörür, Dr. Maximilian Trescher, Dr. Chris Biemann und Dr. Martin Semmann. Das Forschungsteam hat die Ressourcen öffentlich zugänglich gemacht, um weitere Innovationen im Bereich von LLMs und der Informationsgewinnung zu fördern.
Technische Ressourcen:
Zugriff auf Datensätze: Verfügbar über Hugging Face
Leistungsüberwachung: Eine interaktive Rangliste steht Forschern zum Vergleich von Modell-Benchmarks zur Verfügung.
Neues Paper über Diffusion-Modelle im Journal Transactions on Machine Learning Research (TMLR) veröffentlicht
Wir freuen uns, die Veröffentlichung unseres neuesten Research-Papers „From discrete-time policies to continuous-time diffusion samplers: Asymptotic equivalences and faster training“ im Journal Transactions on Machine Learning Research (TMLR) bekannt zu geben.
Das Paper befasst sich mit einer zentralen Herausforderung im Bereich generativer KI: dem Training von Diffusion-Modellen, um komplexe Verteilungen (wie Boltzmann-Verteilungen) zu sampeln, ohne auf bereits existierende Ziel-Samples angewiesen zu sein.
Zentraler Beitrag
Unsere Forschung liefert mehrere Fortschritte für den Bereich der generativen Modellierung:
Theoretischer Rahmen: Wir etablieren eine formale mathematische Brücke zwischen zeitdiskretem Reinforcement Learning (speziell GFlowNets) und zeitkontinuierlichen Objekten, einschließlich stochastischer Differentialgleichungen (SDEs) und partieller Differentialgleichungen (PDEs).
Optimierung des Trainings: Das Paper zeigt auf, dass Entwickelnde durch die Wahl einer geeigneten groben Zeitdiskretisierung die Sample-Effizienz erheblich steigern können.
Performance-Benchmarking: Unsere Methodik ermöglicht außerdem kürzere Trainingszeiten und eine wettbewerbsfähige Performance bei Standard-Sampling-Benchmarks, während gleichzeitig der gesamte Rechenaufwand reduziert wird.
Diese Arbeit spiegelt das kontinuierliche Engagement von dida wider, die ML-Theorie voranzutreiben, um effizientere und skalierbare Anwendungen für die Praxis zu schaffen.
Danksagung
Diese Forschungsarbeit war eine Gemeinschaftsleistung. Wir möchten allen Co-Autoren unseren Dank aussprechen: Julius Berner, Lorenz Richter, Marcin Sendera, Jarrid Rector-Brooks und Nikolay Malkin.
Ebenso danken wir den beteiligten Organisationen für ihre Unterstützung und die bereitgestellten Ressourcen: Caltech, NVIDIA, die Jagiellonen-Universität, Mila – Quebec Artificial Intelligence Institute, die Université de Montréal, Dreamfold, die University of Edinburgh, CIFAR und das Zuse-Institut Berlin.
Ressourcen
Hier finden Sie die Links zum Paper und zur Fachzeitschrift:
Vollständiges Paper: https://arxiv.org/pdf/2501.06148?
Informationen zum Journal: https://jmlr.org/tmlr/
dida gewinnt öffentlichen Rahmenvertrag für KI in Oberösterreich
Wir freuen uns, Ihnen mitteilen zu können, dass dida zusammen mit unserem Partner Consileon erfolgreich einen Rahmenvertrag über KI mit dem Land Oberösterreich abgeschlossen hat. Der Vertrag hat eine Laufzeit von vier Jahren (mit einer Option auf zwei weitere Jahre).
Diese langfristige Perspektive ist eine tolle Gelegenheit, über kurzfristige Pilotprojekte hinauszugehen und nachhaltige KI-Lösungen für die öffentliche Verwaltung zu implementieren, die einer kohärenten Strategie und Vision folgen.
Die Partnerschaft ist eine klassische „Best of both worlds“-Konstellation: Während Consileon sein umfangreiches Know-how in der Beratung und Strategie für den öffentlichen Sektor einbringt, wird dida für die technische Umsetzung und die Entwicklung der KI-Software verantwortlich sein. Durch die Kombination dieser beiden Kompetenzbereiche werden wir in der Lage sein, Lösungen zu implementieren, die innovativ sind und im Kontext der öffentlichen Verwaltung tatsächlich funktionieren.
Wir freuen uns auf die Zusammenarbeit in den nächsten Jahren und darauf, die digitale Transformation in Oberösterreich voranzutreiben.
From Theory to Practice: Erfolgreicher Start unserer Workshop-Reihe
Letzte Woche haben wir unsere Workshop-Reihe „BLISS x dida” gestartet. Was als Idee begann, um die Lücke zwischen KI-Forschung und KI in Industrieprojekten zu schließen, entwickelte sich schon in der ersten Session zu einem vollbesetzten Raum mit über 90 neugierigen Köpfen an der TU Berlin.
Ein großes Dankeschön an Reduan Achtibat vom Fraunhofer HHI für die Leitung unseres ersten Workshops: „Opening the Black Box with LRP”. Reduan gab uns einen tiefen Einblick in Explainable AI (XAI) für LLMs. In einer Welt, in der LLMs oft als Black Boxes angesehen werden, sind Workshops wie dieser entscheidend für den Aufbau sicherer, zuverlässiger und steuerbarer KI-Systeme.
Zentrale Erkenntnisse für die Teilnehmenden unserer Live-Coding-Session:
Rückverfolgung der Argumentationskette von den Tokens bis zur Vorhersage mittels LRP
Identifizierung, wie bestimmte Aufmerksamkeitsköpfe Informationen während des kontextbezogenen Lernens abrufen
Eingreifen in latente Repräsentationen, um die Generierung zu steuern
Zu verstehen, warum ein LLM eine Entscheidung trifft, ist genauso wichtig wie die Entscheidung selbst.
Das war eine tolle erste Sitzung unserer Workshop-Reihe. Sie dürfen auf die nächste Sitzung gespannt sein, die bereits in den nächsten Wochen folgen wird!
2025
Digital Justice Award 2025
Anfang dieser Woche wurden wir für unsere Arbeit an xJuRAG, unserem gemeinsamen Projekt mit dem Fraunhofer Heinrich Hertz Institut (HHI), ausgezeichnet.
Unsere Kollegen Emilius Richter, Julius Lauenstein und Manu Keiper stellten dem Publikum des Digital Justice Summits xJuRAG vor und erklärten, wie wir das Black-Box-Problem von KI-Generierungen für den Rechts- und Justizsektor lösen.
In diesen Bereichen reicht es nicht aus, dass ein KI-System komplexe rechtliche Fragen beantwortet - es muss aufzeigen, wie es tatsächlich zu einer Antwort gekommen ist. Deshalb arbeiten wir mit xJuRAG an folgenden Schwerpunkten:
Transparenz: Quellenangaben und Offenlegung der Entscheidungsgrundlagen.
Vertrauen: Nutzung von Attention-aware Layer-wise Relevance Propagation (AttnLRP), um zu zeigen, wie das Modell zu seinen Schlussfolgerungen gelangt.
Effizienz: Beschleunigung der juristischen Recherche ohne Einbußen bei der Nachvollziehbarkeit.
Der Konsens auf dem Digital Justice Summit war eindeutig:
Die Digitalisierung der Justiz ist dringend. Um mit dem erhöhten Tempo modernisierter Arbeitsabläufe in Kanzleien Schritt zu halten, muss auch der Justizsektor an Geschwindigkeit zulegen - insbesondere angesichts von Faktoren wie dem durch den demografischen Wandel verursachten Fachkräftemangel. Dies ist notwendig, um die sogenannte „Waffengleichheit“ zu gewährleisten.
Die entscheidende Bedingung bleibt jedoch: KI in der Justiz muss souverän, rechtskonform und vor allem erklärbar sein.
Deshalb sind wir bei dida unglaublich stolz darauf, den Digital Justice Award gewonnen zu haben!
Presenting GENIAL4KMU at Mittelstandsforum 2025
Letzte Woche stellte unser Kollege Dr. Maximilian Trescher unsere Arbeit an GENIAL4KMU auf dem Mittelstandsforum 2025 in Berlin vor.
Das Projekt konzentriert sich auf die Optimierung von RAG-Ansätzen und LLM-Generierungen für deutsche KMU, die mit spezifischer Branchenterminologie arbeiten. Zusammen mit dem Hub of Computing and Data Science (HCDS) Hamburg präsentierten wir ein Poster und beantworteten viele Fragen von interessierten Besuchern.
Das Mittelstandsforum, das im November stattfand, konzentrierte sich auf die Megatrends KI und Nachhaltigkeit in der Bauindustrie. Ziel war es, Entscheidungsträgern Einblicke in nachhaltigere Baupraktiken und den Einsatz von KI zu vermitteln.
Wir möchten uns bei den Organisatoren für die Möglichkeit bedanken, unser Projekt vorstellen zu dürfen, und freuen uns auf weitere Veranstaltungen dieser Art in der Zukunft.
IPAI Experience Day 2025
Am Dienstag hatten Markus Düttmann und David Berscheid die Gelegenheit, am Experience Day von IPAI teilzunehmen. Die Veranstaltung brachte die IPAI-Community zusammen, um ihre neuesten Arbeiten im Bereich KI vorzustellen und ihre Erkenntnisse mit anderen IPAI-Mitgliedern zu teilen.
Wir hatten viele interessante Gespräche, aber einige unserer Highlights waren:
Der Vortrag von Aleph Alpha zum Thema „Spezialisten gestalten die Welt, Generalisten reden darüber”, in dem Yasser Jadidi die Forschungsarbeiten von Aleph Alpha vorstellte, beispielsweise das Tracing in LLMs – Konzepte, die wir in einigen unserer eigenen LLM-fokussierten Forschungsprojekte berücksichtigen könnten;
Tolle Demos vom MANN+HUMMEL-Team über ihre KI in der Fertigung und ihre Plattform für den Datenaustausch;
Erfahrungen der AUDI AG mit ihrer MLOps-Plattform zur Optimierung von Maschinen in Fertigungswerken;
Gespräche mit dem ebm-papst-Team über Themen wie Bedarfsprognosen und Architekturentscheidungen.
Insgesamt war der Experience Day voller interessanter Präsentationen.
Diese Veranstaltung war ein großartiges Beispiel dafür, dass die typische Erzählung, europäische Unternehmen seien bei der Einführung von KI nicht ambitioniert genug, oft zu kurz greift. Was wir hier gesehen haben, war eine große Dynamik, ambitionierte KI-Agendas und realistische Ansätze zu deren Umsetzung.
Vielen Dank an das IPAI-Team für die Einladung und die großartige Organisation!
xJuRAG: Explainable AI für juristische RAG-Anwendungen
Wir freuen uns, den Start unseres xJuRAG-Projekts bekannt zu geben, kurz für „Explainable AI für juristische RAG-Anwendungen” (Erklärbare KI für juristische RAG-Anwendungen), einer neuen gemeinsamen Forschungsinitiative. Als Projektkoordinator arbeitet dida mit dem renommierten Fraunhofer Heinrich-Hertz-Institut (HHI) zusammen, um eine der größten Herausforderungen der künstlichen Intelligenz anzugehen: das „Black-Box”-Problem.
LLMs zeigen zwar großes Potenzial, aber ihre Neigung zu „Halluzinationen” oder zur Erfindung von Fakten macht sie für sensible Bereiche wie den Rechtssektor zu einem Risiko. Dieser Mangel an Vertrauen ist ein großes Hindernis für die breite Einführung von KI in professionellen Rechtsumgebungen.
Das Ziel: Ein vollständig transparenter Rechtsassistent
Das Hauptziel von xJuRAG ist es, ein Rechtsassistenzsystem zu entwickeln, das nicht nur intelligent, sondern auch vollständig transparent ist.
Wir entwickeln eine Anwendung auf Basis von Retrieval Augmented Generation (RAG), die speziell für den Rechtsbereich konzipiert ist. Das System wird in der Lage sein:
komplexe Rechtsfragen zu beantworten,
seine Quellen zuverlässig zu zitieren,
klar zu erklären, wie es zu seinen Schlussfolgerungen gelangt ist.
Das Projekt wird sich zunächst auf Entscheidungen im Verkehrs- und Mietrecht konzentrieren.
Die Innovation: Erklärung der Black-Box-Logiken
Die Innovation von xJuRAG liegt in der tiefen Integration von fortschrittlicher Explainable AI (XAI). Wir werden eine leistungsstarke Methode anpassen, die am Fraunhofer HHI entwickelt wurde: Attention-aware Layer-wise Relevance Propagation (AttnLRP).
Dieser Ansatz geht weit über herkömmliche RAG-Systeme hinaus. Er ermöglicht es uns, einen detaillierten „Prüfpfad“ zu erstellen, der genau quantifiziert, welche Wörter in einem Quelldokument für die endgültige Antwort am relevantesten waren.
Das Justizsystem basiert auf Klarheit und Überprüfbarkeit – Prinzipien, die Standard-KI nicht garantieren kann. xJuRAG zielt darauf ab, diese Prinzipien direkt zu erfüllen. Durch die Bereitstellung eines zuverlässigen und transparenten Tools helfen wir Juristen, zeitaufwändige Recherchen zu automatisieren und Vertrauen in KI-gestützte Entscheidungen aufzubauen. Dadurch können sich Experten auf übergeordnete Strategien und Argumentationen konzentrieren.
Durch den Nachweis der Funktionsfähigkeit erklärbarer KI in einem sensiblen Bereich wird xJuRAG auch dazu beitragen, das Vertrauen der Öffentlichkeit zu fördern und die verantwortungsvolle Einführung von KI in anderen kritischen Bereichen wie der Medizin und der öffentlichen Verwaltung zu beschleunigen.
Das Projekt ist in drei Phasen gegliedert und soll 36 Monate dauern.
Kontakt
Wenn Sie eine Anwaltskanzlei oder ein Legal-Tech-Unternehmen vertreten und daran interessiert sind, mehr zu erfahren oder mögliche Anwendungen zu erkunden, wenden Sie sich bitte an uns.
STAC Summit London
Vergangene Woche folgte Dr. Lorenz Richter der Einladung von STAC, auf dem STAC Summit in London über die Lösung partieller Differentialgleichungen (PDEs) in hochdimensionalen Räumen zu sprechen.
Die Konferenz, die sich an technische Entscheider im Finanzbereich richtete, bot eine hervorragende Gelegenheit, einige unserer eher technischen Erkenntnisse über physikalisch informierte neuronale Netze (physics-informed neural networks, kurz: PINNs) und Methoden auf der Grundlage von rückwärtsgerichteten stochastischen Differentialgleichungen (backward stochastic differential equations, kurz: BSDEs) zu teilen.
In der computergestützten Finanzwissenschaft ist die Überwindung des „Curse of Dimensionality” eine ständige Herausforderung. Entsprechend präsentierte Lorenz die Zusammenhänge zwischen PINNs und BSDE in Bezug auf stochastische optimale Steuerung und Reinforcement Learning und zeigte auf, wie diese Ansätze neue Möglichkeiten für die Lösung komplexer Probleme in der Finanzwissenschaft eröffnen.
Der Summit war eine zweitägige Veranstaltung mit großartigen Referenten und hochkomplexen Themen rund um KI in der Finanzwissenschaft. Es war uns eine große Freude, so viele Experten auf ihrem Gebiet kennenzulernen.
Wir haben uns gefreut, einen Beitrag leisten zu können, und freuen uns schon auf die nächste Veranstaltung. Ein großes Dankeschön an das STAC-Team für die tolle Organisation!
Unser NeurIPS-Beitrag wurde angenommen und mit einer Spotlight-Erwähnung ausgezeichnet
Wir freuen uns sehr, Ihnen mitteilen zu können, dass unser Paper über stochastische optimale Steuerung, das wir in Zusammenarbeit mit Kollegen vom Karlsruher Institut für Technologie (KIT), NVIDIA, Microsoft Research und der Cornell University verfasst haben, für die NeurIPS 2025 angenommen wurde.
Das Paper mit dem Titel „Trust Region Constrained Measure Transport in Path Space for Stochastic Optimal Control and Inference” untersucht, wie sich ein Optimierungsalgorithmus, der auf sogenannten "Trust Regions" basiert, für Anwendungen der stochastischen optimalen Steuerung im Vergleich zu bestehenden Methoden bewährt.
Wir konnten zeigen, dass unsere neuartige Methode Aufgaben wie das Finetuning von Diffusionsmodellen, diffusionsbasiertes Sampling oder Transition Path Sampling verbessern kann.
Ein großes Dankeschön an alle Mitwirkenden (Denis Blessing, Julius Berner, Lorenz Richter, Carles Domingo-Enrich, Yuanqi Du, Arash Vahdat, Gerhard Neumann) und herzlichen Glückwunsch an das Team zur Spotlight-Erwähnung!
Die Veröffentlichung finden Sie hier: https://arxiv.org/pdf/2508.12511
dida tritt dem IPAI-Netzwerk bei, um die Entwicklung verantwortungsvoller KI zu fördern
Wir freuen uns bekannt zu geben, dass dida dem IPAI – dem „Innovation Park Artificial Intelligence“ – beigetreten ist.
Die Innovationsplattform aus Heilbronn mit Partnern und Mitgliedern wie Schwarz Digits, Aleph Alpha, Telekom, Porsche, Audi oder der Würth-Gruppe, verbindet Akteure aus Forschung, Industrie und Politik, um gemeinsam an der Entwicklung verantwortungsvoller KI zu arbeiten.
Mit dieser Partnerschaft wird dida insbesondere seine Expertise in Natural Language Processing, Computer Vision und MLOps einbringen, um IPAI-Mitglieder bei ihren KI-Projekten zu unterstützen und individuelle KI-Lösungen zu entwickeln, die auf Sicherheit und Erklärbarkeit optimiert sind.
Wie Dr. Markus Düttmann (Geschäftsführer von dida) erklärt: „In unserer täglichen Arbeit mit deutschen und europäischen Unternehmen sehen wir viele vielversprechende KI-Entwicklungen, auf denen aufgebaut werden kann. Netzwerke wie IPAI spielen eine zentrale Rolle dabei, dieses Potenzial in die Realität umzusetzen, indem sie eine Plattform für die Zusammenarbeit zwischen den Mitgliedern schaffen und Fachwissen sowie Ressourcen teilen.
Wir sind dem IPAI beigetreten, weil wir motiviert sind, unser tiefes technisches Wissen in solche Kooperationen einzubringen, um anspruchsvolle KI-Strategien für europäische Organisationen Realität werden zu lassen. Bringen wir erstklassige KI-Wissenschaftler mit erstklassigem Domänenwissen zusammen.“
In diesem Sinne freut sich dida auf den zukünftigen Austausch, Initiativen und Veranstaltungen innerhalb des IPAI-Ökosystems.
Wenn Sie mit uns oder dem IPAI über die Implementierung verantwortungsvoller KI sprechen möchten, zögern Sie bitte nicht, uns zu kontaktieren.
Rückblick auf die ICML 2025
Lassen Sie uns einen Rückblick auf die diesjährige International Conference on Machine Learning (ICML) werfen, die in Vancouver, Kanada, stattfand.
Wir freuen uns, erneut Teil der ICML gewesen zu sein und sind stolz darauf, unseren ersten Beitrag zum Thema Reinforcement Learning (RL) vorgestellt zu haben. In Zusammenarbeit mit Enric Ribera Borrell und Christof Schütte diskutierten wir unseren Beitrag „Reinforcement Learning with Random Time Horizons”.
In unserer Arbeit konnten wir RL auf Settings mit zufälligen, richtlinienabhängigen Zeithorizonten ausweiten, indem wir rigoros neue Richtliniengradientenformeln – sowohl stochastische als auch deterministische – abgeleitet haben und zeigen konnten, dass diese die Optimierungskonvergenz verbessern.
Neben unserer Präsentation haben wir uns mit anderen internationalen Forschern ausgetauscht. Die wichtigsten Themen der diesjährigen Konferenz lassen sich in folgende Kategorien einteilen:
(1) LLMs & Agenten, (2) Diffusionsmodelle, (3) Interpretierbarkeit & Alignment, (4) Optimierung & Skalierungsgesetze und (5) Fairness.
Es war wieder einmal eine wirklich großartige Atmosphäre – ein weiterer Grund, warum wir unsere Forschungsergebnisse gerne auf internationaler Ebene vorstellen.
Link zu unserem Paper: https://arxiv.org/pdf/2506.00962
dida hält KI-Masterclass beim Big Bang KI Festival
Am 11. September hielt Dr. Lorenz Richter auf Grundlage des Solarplanungsprojekts von dida mit Enpal einen Vortrag beim BIG BANG KI FESTIVAL über die Lösung komplexer geometrischer Probleme im Rahmen von KI-Projekten und darüber, wie man 2D-Informationen in 3D umwandelt.
Das Big Bang KI Festival 2025 war eine zweitägige Veranstaltung mit Schwerpunkt auf KI und digitalen Trends, die als „Europas größte KI-Veranstaltung” bezeichnet wurde und mit 8.500 verkauften Tickets ausverkauft war.
Wir freuen uns, zu dieser großen Konferenz mit Referenten aus öffentlichen Einrichtungen, verschiedenen Branchen und Technologieanbietern beigetragen zu haben.
Vielen Dank für die Einladung und insbesondere an das Publikum unserer Masterclass für die spannende Sitzung und die rege Teilnahme, die zu einer großartigen Diskussion geführt hat.
Vortrag zum Thema Reinforcement Learning am KIT
Letzte Woche hatte unser Geschäftsführer und CTO, Dr. Lorenz Richter, die Gelegenheit, sich mit einer der führenden Reinforcement-Learning-Gruppen Deutschlands, dem Autonomous Learning Robots Lab am Karlsruher Institut für Technologie (KIT), zu treffen und seinen neuesten ICML-Artikel „Reinforcement Learning with Random Time Horizons” vorzustellen.
Das ALR Lab unter der Leitung von Professor Dr. Gerhard Neumann hat sich zum Ziel gesetzt, neuartige Methoden des maschinellen Lernens für die Robotik zu entwickeln, die für komplexe Roboteranwendungen wie Greifen und Manipulieren oder dynamische motorische Aufgaben geeignet sind.
In seinem Vortrag stellte Lorenz den Ansatz vor, Konzepte aus der stochastischen optimalen Steuerung auf das Reinforcement Learning zu übertragen – zwei scheinbar getrennte Forschungsbereiche mit interessanten Parallelen. Anschließend folgte eine technische Diskussion mit den Forschern der Gruppe.
Wir möchten uns für die Einladung und die Möglichkeit bedanken, unsere neuesten Forschungsergebnisse mit den ExpertInnen des KITs zu diskutieren!
Ein spannender Tag bei nVent SCHROFF
Eine Delegation des dida-Teams (Dr. Marty Oelschläger, Jakob Scharlau, Dr. Konrad Schultka und Dr. Sebastian Thomas) hatte das Vergnügen, zum ersten Mal die Einrichtungen von nVent Schroff hier in Deutschland zu besuchen.
Wir haben nicht nur den Fortschritt unseres gemeinsamen Projekts besprochen, sondern hatten auch die einmalige Gelegenheit, mehr über die reichhaltige Unternehmensgeschichte von Schroff zu erfahren, einem seit über 65 Jahren führenden Anbieter von Elektronikgehäusen und Infrastrukturlösungen.
Besonders inspirierend ist die kontinuierliche Innovationskraft von nVent Schroff. Das Know-how des Unternehmens trägt dazu bei, kritische Systeme widerstandsfähig zu machen und wichtige Infrastrukturen für Bereiche wie Energiespeicherung und hochmoderne Rechenzentren bereitzustellen.
Wir freuen uns auf das, was wir gemeinsam erreichen werden!
dida mit Beitrag zum Anwendertag von publicplan in Düsseldorf
Letzte Woche folgten Julius Lauenstein und Lorenz Richter der Einladung von publicplan, an ihrem jährlichen „Anwendertag” in der Unternehmenszentrale in Düsseldorf teilzunehmen und einen KI-Beitrag beizusteuern.
Die Veranstaltung ist eine spezielle Veranstaltung von publicplan, um digitale Verwaltung in der Praxis zu präsentieren, mit einem Schwerpunkt auf KI und Open-Source-Lösungen für die öffentliche Verwaltung. Mit Vertretern von Behörden, öffentlicher Verwaltung und Ministerien war es ein großartiger Tag, um das 15-jährige Jubiläum von publicplan zu feiern.
Lorenz hielt einen Vortrag zum Thema „Informationsextraktion mit KI und LLMs: von komplexen Formularen bis zur Handschrifterkennung”, in dem er Randfälle von Informationsextraktionsszenarien zeigte, die nicht trivial zu lösen sind.
Wir möchten uns gerne bei Christian Knebel, Fabian Nagel und Moritz-Maximilian Katzer für die Einladung bedanken und gratulieren noch einmal zur Organisation dieser großartigen Veranstaltung.
Wir freuen uns auf viele weitere gemeinsame Entwicklungen für den öffentlichen Sektor in der Zukunft!
dida hält Vortrag bei IPAI über individuelle Optimierungen innerhalb von KI-Projekten
Letzte Woche hatten wir die Gelegenheit, IPAI zum ersten Mal zu besuchen. Unser Kollege David Berscheid hielt vor den Mitgliedern der IPAI-Community einen Vortrag zum Thema „Produktionsreife KI-Projekte: Warum viele Projekte ohne individuelle Optimierungen scheitern“.
IPAI, kurz für Innovation Park Artificial Intelligence, ist ein sehr ambitioniertes Projekt in Heilbronn, dessen Ziel es ist, eines der führenden Ökosysteme für angewandte KI-Technologie in Europa aufzubauen. Dabei werden Unternehmen, Start-ups, Forscher und Akteure des öffentlichen Sektors zusammengebracht, um KI-Lösungen mit Schwerpunkt auf ethischer und verantwortungsvoller Nutzung zu entwickeln und zu betreiben.
Es war wirklich toll, die Räumlichkeiten von IPAI zu sehen, das IPAI-Team kennenzulernen und mehr über die Vision für diese gesamte Region zu erfahren. Vielen Dank an die Veranstaltungs- und Partnermanagement-Teams für die Einladung und die Möglichkeit, Einblicke in unsere Arbeit zu geben und zu zeigen, wie wir unsere Projekte durch mathematische Optimierungen verbessern.
Wir freuen uns auf weitere IPAI-Veranstaltungen in der Zukunft!
dida auf dem Zukunftsforum Kunststoffkreislauf der DECHEMA
Vor einer Woche hatten wir das Vergnügen, am Zukunftsforum Kunststoffkreislauf teilzunehmen, das von der DECHEMA Gesellschaft für Chemische Technik und Biotechnologie veranstaltet wurde.
Unsere Kollegen Dr. William Clemens und Dr. Eva Höning vertraten dida und stellten unsere Arbeit an KIOptiPack vor – einem Projekt, das sich darauf konzentriert, mithilfe von KI die geeignete Recyclingmethode für Kunststoffprodukte zu ermitteln.
Auf der Veranstaltung präsentierten sie ein Poster zu unseren neuesten technologischen Entwicklungen: „Probabilistische Modellierung unbekannter Kunststoffeigenschaften mit Denoising Diffusion”.
Dieser Ansatz zielt darauf ab, die Genauigkeit der Materialklassifizierung zu verbessern, wenn Produktinformationen unvollständig sind, und so intelligentere und nachhaltigere Recyclingentscheidungen zu unterstützen.
Vielen Dank an die DECHEMA für die Organisation dieser inspirierenden Veranstaltung und an alle Teilnehmer für die wertvollen Gespräche!
smartextract und on-geo starten exklusive Zusammenarbeit bei Grundbuchdaten-Extraktion
Die Software für KI-gestützte Dokumentenverarbeitung smartextract von dida und die on-geo GmbH geben offiziell ihre exklusive Partnerschaft im Bereich der Grundbuchdatenextraktion für die Finanz- und Immobilienwirtschaft bekannt.
On-geo ist Marktführer im Bereich softwaregestützter Markt- und Beleihungswertermittlung sowie Lösungsanbieter für Sachverständige, Gutachter und Dienstleister der Immobilienwirtschaft.
Durch die Integration der KI-Lösung smartextract in bestehende Softwareprodukte wie LORA von on-geo, ermöglicht das Unternehmen eine schnelle und digitale Extraktion von Grundbuchdaten für Banken, Sparkassen, Finanzmakler, Gutachter, Immobilienmakler und Versicherer. Damit wird unter anderem das manuelle Übertragen der Grundbuchinformationen in die Bewertungssoftware ersetzt, sodass die KI den notwendigen Arbeitsaufwand der Nutzer deutlich reduziert und die Datenqualität erhöht.
Darüber hinaus wird durch den Einsatz von smartextract die über den Webshop geoport angebotene Digitalisierung von Grundbuchinhalten wesentlich optimiert, so dass die Datenbereitstellung erheblich schneller möglich ist als bisher. Dies gilt auch für das Angebot der on-geo zur Bearbeitung ganzer Portfolien. Auch die Möglichkeit, smartextract in Drittsysteme zu integrieren ist künftig im Leistungsumfang vorgesehen. Der gesamte Immobilienbewertungsprozess wird damit effizienter und wirtschaftlicher gestaltet.
Matthias Knabe, Geschäftsführer bei on-geo, sagt zur Partnerschaft:
Mit der Integration von smartextract in unsere Softwarelösungen gehen wir einen weiteren Schritt in der digitalen Transformation der Immobilien- und Finanzbranche. Durch unsere Zusammenarbeit mit smartextract können wir unseren Kunden nun eine noch effizientere Lösung zur Grundbuchdaten-Extraktion bieten und die Zukunft der Immobilienbranche aktiv mitgestalten.
Axel Besinger, VP Product & Growth bei smartextract, kommentiert die Kollaboration folgendermaßen:
Mit on-geo verbindet uns die Überzeugung, dass KI-Technologie Arbeitsabläufe nicht nur beschleunigt, sondern neue Effizienzstandards setzen kann. Die Partnerschaft ist ein logischer und konsequenter Schritt, um die Digitalisierung der Immobilien- und Finanzwirtschaft mit intelligenten Dokumentenprozessen nachhaltig zu unterstützen.
Über smartextract
smartextract ist eine Marke von dida, einer der führenden KI-Agenturen in Deutschland. smartextract bietet spezialisierte KI-Lösungen zur automatisierten Dokumentenverarbeitung und ermöglicht die Extraktion, Klassifizierung und den Abgleich von Daten aus Geschäftsdokumenten und E-Mails - flexibel als API- oder White-Label-Lösung für Plattformanbieter und Softwarehersteller.
Mehr Informationen unter: smartextract.ai
Über on-geo
80.000 Kunden, 1,6 Millionen erstellte Wertgutachten, 1,9 Millionen Daten- und Unterlagenabrufe sowie 250.000 Objektbesichtigungen pro Jahr. Das ist die Statistik von on-geo. Das Erfurter Unternehmen entwickelt Softwarelösungen für mehr Transparenz und Effizienz in der Immobilienbewertung. Dazu zählen etwa das digitale Baufinanzierungstool baufi.me, LORA - die marktführende Prozesslösung für Beleihungswertermittlung und accumate, ein KI-basiertes Automated Valuation Model. Ergänzt wird das Portfolio durch den Research Datenshop geoport.
Mehr Informationen unter: on-geo.de
Pressekontakt
on-geo GmbH
Andy Dietrich
andy@strategiekollegen.de
Mobil: 0170 2283299
Creative Bureaucracy Festival: Viel Energie, Kreativität und Entschlossenheit im öffentlichen Sektor
Letzten Donnerstag besuchte unser Kollege Julius Lauenstein das Creative Bureaucracy Festival in Berlin. Das Creative Bureaucracy Festival ist eine jährliche Veranstaltung, die Innovatoren des öffentlichen Sektors, kreative Köpfe und Changemaker aus Deutschland und der DACH-Region zusammenbringt. Hauptziel ist es, die Prinzipien, Prozesse und Praktiken öffentlicher Einrichtungen zu überdenken und zu erforschen, wie eine bessere Bürokratie entstehen kann.
Die Veranstaltung bot interessante Präsentationen wie die Sitzung von Dr. Iliya Nickelt vom Data Lab des Bundesministeriums für wirtschaftliche Zusammenarbeit und Entwicklung (BMZ) über den Spagat zwischen agilem, cloudbasiertem Prototyping und den langfristigen Anforderungen an sichere öffentliche Dienstleistungen oder die beeindruckenden KI-gesteuerten Tools, die vom Bundesministerium für Arbeit und Soziales und der Deutschen Rentenversicherung vorgestellt wurden, um groß angelegte Prüfprozesse zu unterstützen, welche zuvor sehr arbeitsintensiv waren.
Es war schön zu sehen, wie all diese Initiativen das gemeinsame Ziel von digitalisierten und öffentlichen Verwaltungen fördern.
Wir freuen uns, Teil dieser stetigen Digitalisierungsdynamik in deutschen und europäischen Behörden zu sein und mitzuhelfen, KI-basierte Prozessautomatisierungen für mehr Effizienz zu entwickeln.
Wenn Sie mit uns über KI-basierte Initiativen im öffentlichen Sektor sprechen möchten, kontaktieren Sie uns gerne.
dida conference 2025
Letzten Freitag hatten wir die Ehre rund 300 Developer, Führungskräfte und Interessierte aus den Bereichen KI und Machine Learning im fizzforum in Berlin begrüßen zu dürfen. Mit unserer jährlichen Konferenz wollen wir eine Plattform bieten, auf der führende Wissenschaftler und Ingenieure ihre theoretischen und angewandten Arbeiten rund um KI und Machine Learning präsentieren können.
Das diesjährige Programm umfasste eine Mischung aus allen Themen, die uns wichtig sind:
Unser Frühstück vor der Konferenz brachte Akteure des öffentlichen Sektors zusammen, die hart daran arbeiten, deutsche und europäische Regierungen KI-fähig zu machen.
Einblicke von führenden KI-Organisationen in die aktuell spannendsten Themen, wie z.B. von Dr. Julian Risch (deepset) mit seinem Workshop zu KI-Agenten oder von Andrey Vasnetsov (Qdrant) mit miniCOIL.
Ganzheitliche Betrachtung von KI-Entwicklungen, wie z.B. im Responsible-AI-Workshop (Florian Dohmann, Dina Dürkop, Dr. Liel Glaser), mit Dr. Sebastian Lapuschkins Vortrag zu Explainable AI, oder durch den Einsatz von "Confidential Computing" (Thomas Strottner, Edgeless Systems).
Eine Bühne für viele großartige Forscher bot unsere Postersession, bei der sich die Gäste über KI-Projekte der Technischen Universität München, der Universität Hamburg, BalkonSonne.App, des Zuse-Instituts Berlin, des Fraunhofer Heinrich-Hertz-Instituts HHI, der Humboldt-Universität zu Berlin oder der Universität zu Lübeck informieren konnten.
Und last but not least:
KI in die Produktion bringen - mit NVIDIAs Triton Inference Servern (Dr. Marty Oelschläger, Fabian Dechent), in eingebetteten Plattformen (Edwin Fung, Dr. Tassilo Glander) oder in KI-getriebenen Produkten wie Mirelo AI (Dr. Florian Wenzel) oder smartextract (Axel Besinger, Dr. Augusto Stoffel).
Wir möchten uns bei allen bedanken, die zu diesem besonderen Tag beigetragen haben! Wir bedanken uns bei allen Mitwirkenden, langjährigen Partnern, Gästen und dem gesamten dida-Team für die Teilnahme an der dida conference 2025!
LLM4Anamnese-Projekttreffen in Frankfurt
Ende April reisten unsere Machine Learning Scientists Fabian Dechent, Dr. Marty Oelschläger und Dr. Liel Glaser nach Frankfurt am Main, wo das LLM4Anamnese-Team zusammenkam, um den Fortschritt bei dem gemeinsamen Forschungsprojekt zur Nutzung von Large Language Models zur Verbesserung der Analyse unstrukturierter medizinischer Texte zu diskutieren.
LLM4Anamnese ist Teil des Forschungsprogramms „Interaktive Technologien für Gesundheit und Lebensqualität“, das vom Bundesministerium für Bildung und Forschung (BMBF) mit einem Budget von 1,02 Millionen Euro gefördert wird. Über 36 Monate untersucht das Projekt die Anwendung von LLMs für die Klassifizierung von Anamnesen und deren Verknüpfung mit standardisierten medizinischen Terminologien, unter Erfüllung strikter Datenschutz-Anforderungen.
Das Treffen fand in der Universitätsmedizin Frankfurt statt und umfasste Stakeholders aus beteiligten Organisationen wie AWS und VDI VDE IT. AWS hat zugesagt, das Projekt mit europäischen souveränen Cloud-Credits zu unterstützen und so eine zuverlässige und sichere Cloud-Infrastruktur zu gewährleisten.
In unserem Gespräch mit der IMI (Innovative Medicines Initiative) haben wir viel über die praktische Anwendung von LLM4Anamnese erfahren, insbesondere wie LLM4Anamnese automatisierte medizinische Dokumentationsprozesse wie Entlassungsbriefe ermöglichen und somit eine erhebliche Prozessoptimierung bieten kann.
Wir möchten allen Teilnehmern für dieses anregende Zwischentreffen danken und freuen uns auf die Fortschritte, die wir in den nächsten Monaten machen werden.
Rückblick auf die ICLR 2025 in Singapur
Die International Conference on Learning Representations (ICLR) 2025 in Singapur hat erneut führende Forscher zusammengebracht, um neue Erkenntnisse im Machine Learning zu diskutieren.
Dr. Lorenz Richter, Geschäftsführer und CTO von dida, nahm an der Veranstaltung teil, stellte didas gemeinsame Forschung zu Diffusionsmodellen vor und diskutierte die neuesten Machine-Learning-Fortschritte mit anderen Forschenden.
dida präsentierte zwei Arbeiten, die in Zusammenarbeit mit Partnern des California Institute of Technology (Caltech), der Universität Cambridge, dem Karlsruher Institut für Technologie (KIT) und NVIDIA entstanden sind.
Das erste Paper, "Underdamped Diffusion Bridges with Applications to Sampling", führte einen neuen Ansatz für diffusionsbasiertes generatives Modellieren ein, welcher theoretische Physik nutzt, um Simulationsmethoden für spezifische Sampling-Herausforderungen zu verbessern.
Das zweite Paper, "Sequential Controlled Langevin Diffusions" (SCLD), untersuchte eine Methode, die Sequential Monte Carlo (SMC) mit diffusionsbasierten Sampling-Techniken integriert. Dieser Ansatz zeigte eine Reduzierung des Bedarfs an Trainingsressourcen für Sampling-Modelle.
Diese Beiträge unterstreichen didas Engagement für die Weiterentwicklung der KI-Forschung und die Entwicklung von Lösungen für komplexe Probleme. Es ist didas Mission, aktiv zur neuesten KI-Forschung beizutragen und die Lücke zwischen erstklassiger Forschung und industrieller Anwendung zu schließen.
Für weitere Informationen über diese Forschungsarbeiten oder didas Projekte besuchen Sie bitte unsere Unternehmenswebsite oder kontaktieren Sie uns direkt.
dida veröffentlicht Paper über Datensatz zur Few-Shot-Klassifizierung von Pflanzenarten in Nature Scientific Data
Heute freuen wir uns, Ihnen mitteilen zu können, dass wir unseren neuesten Artikel im Journal Nature Scientific Data veröffentlicht haben.
Dr. Jan MacDonald und Dr. Lorenz Richter von dida haben in Zusammenarbeit mit den externen Partnern Joana Reuss und Dr. Marco Körner (beide Technische Universität München, Lehrstuhls für Methodik der Fernerkundung) und Dr. Simon Becker (ETH Zürich, Lehrstuhl Mathematik) EuroCropsML entwickelt - einen Zeitreihen-Benchmark-Datensatz für die Klassifizierung von Pflanzenarten in Europa.
Es handelt sich dabei um den ersten zeitaufgelösten Fernerkundungsdatensatz, der für das Benchmarking transnationaler Algorithmen zur Klassifizierung von Kulturpflanzen entwickelt wurde und Fortschritte bei der Entwicklung von Algorithmen und der Vergleichbarkeit in der Forschung unterstützt. Der Datensatz umfasst mehr als 700.000 gelabelte, mehrklassige Datenpunkte für mehr als 100 Kulturpflanzenarten.
Wenn Sie im Bereich der Analyse von Fernerkundungsdaten tätig sind, empfehlen wir Ihnen einen Blick auf die Publikation und den entsprechenden Code zu werfen.
Sie können sich gerne mit Anmerkungen, Fragen oder Remote-Sensing-Projektinitiativen an uns wenden.
dida bei der Eröffnung des KI-Park-Satelliten in Lingen
In der vergangenen Woche nahm dida an der Eröffnung eines neuen KI-Park-Satelliten in Lingen (Niedersachsen) teil, organisiert vom KI Park und CORNEXION.
Mit 250 Gästen war die Veranstaltung ein großer Erfolg für den Start von KI-bezogenen Initiativen in dieser starken Industrieregion, die Unternehmen des deutschen Mittelstands und einige globale Nischenmarktführer beheimatet.
Unser Kollege David Berscheid vertrat dida und hatte die Gelegenheit, dida in einem kurzen Pitch vorzustellen, gefolgt von interessanten Diskussionen über spezifische KI-Anwendungsfälle, die Teilnehmende gerne in Angriff nehmen wollten.
Die Veranstaltung markierte den Startschuss für eine umfassendere Vision zum Aufbau eines KI-Campus in Lingen, einschließlich Büroflächen, mit grüner Energie betriebenen Rechenzentren und einer kohärenten Strategie mit Interessenvertretern aus Wissenschaft und Politik.
Mehrere Keynote-Vorträge gaben wertvolle Einblicke in die praktische Anwendung von KI in regional ansässigen Unternehmen:
Prof. Dr. Goy Hinrich Korn (CDO, KRONE GROUP) präsentierte, wie KRONE unter anderem KI-basierte Umsatzprognosemodelle mit einem Zeithorizont von bis zu drei Jahren einsetzt.
Benjamin Wolters (Head of AI, ROSEN Group) erläuterte, wie sein Unternehmen die Entwicklung von sicheren und vertrauenswürdigen KI-Systemen vorrantreibt.
Dr. Henning Krüp (Head of AI, LIST Gruppe) erklärte, wie man den Hype um das Thema ignorieren und produktiv zur Tat schreiten kann.
Wir danken dem KI-Park für die Einladung und die hervorragende Organisation der Veranstaltung. dida ist stolz darauf, Mitglied des KI-Park-Ökosystems zu sein und freut sich, einen Beitrag zur verantwortungsvollen und effektiven Integration von KI in Europa leisten zu können.
dida mit zwei akzeptierten Forschungsarbeiten bei der ICLR 2025
Wir freuen uns, bekannt geben zu können, dass dida zwei Forschungsbeiträge auf der International Conference on Learning Representations (ICLR) 2025, einer der weltweit führenden Konferenzen im Bereich des Machine Learnings, die im April in Singapur stattfindet, vorstellen wird. Beide Arbeiten sind in Zusammenarbeit mit dem California Institute of Technology (Caltech), NVIDIA und dem Karlsruher Institut für Technologie (KIT) entstanden.
Die erste Forschungsarbeit, „Underdamped Diffusion Bridges with Applications to Sampling“, stellt ein neuartiges Rahmenwerk für diffusionsbasierte generative Modellierung in sogenannten 'underdamped settings' vor. Die Idee ist durch Konzepte aus der theoretischen Physik motiviert und gipfelt in fortgeschritteneren Simulationsmethoden für generative Prozesse. Angewandt auf verschiedene Sampling-Probleme, erreichen diese Methoden den Stand der Technik und übertreffen alternative Methoden, während sie weniger Diskretisierungsschritte sowie keine Hyperparameter-Optimierung erfordern.
Die zweite Forschungsarbeit, „Sequential Controlled Langevin Diffusions“ (SCLD), stellt eine neue Methode vor, die Sequential Monte Carlo (SMC) mit diffusionsbasierten Sampling-Methoden integriert. Durch die Kombination der Stärken beider Methoden zeigt SCLD eine verbesserte Leistung bei Benchmark-Aufgaben und benötigt oft nur 10% der Trainingsressourcen, im Vergleich zu früheren diffusionsbasierten Methoden.
Mit diesen Veröffentlichungen leistet dida einen weiteren Beitrag zum aktuellen Stand der KI-Forschung. Wir freuen uns darauf, diese neu gewonnenen Erkenntnisse in unseren Projekten zu integrieren.
Wenn Sie mehr über diese spezifischen Themen oder die Forschungsaktivitäten der dida im Allgemeinen erfahren möchten, melden Sie sich gerne bei uns.
dida bei „AI Operators Talk“ von Circula
Am 16. Januar nahm dida am „AI Operators Talk“ von Circula teil, wo unser CTO und Geschäftsführer Dr. Lorenz Richter an einer Podiumsdiskussion über die Rolle von KI in modernen Unternehmen und SaaS-Lösungen teilnahm. Die Veranstaltung bot großartige Einblicke, wie KI Arbeitsabläufe optimieren und einen echten Mehrwert schaffen kann, insbesondere in Bereichen wie dem Kostenmanagement.
Circula hat sich auf die Optimierung von Finanzabläufen spezialisiert und bietet Automatisierung für Spesenmanagement, Reisekosten und Sozialleistungen. Mit Funktionen wie einer DATEV-Schnittstelle, die Belegbilder und vorerfasste Daten integriert, hilft das Unternehmen, Finanzprozesse zu vereinfachen und die Effizienz zu steigern.
Es war eine interessante Podiumsdiskussion, bei der wir unsere Erfahrungen über die Entwicklung individueller ML-Projekte beisteuern konnten.
Vielen Dank an das Circula-Team für die Einladung - wir freuen uns auf weitere Diskussionen dieser Art in der Zukunft!
Die Anmeldung zur dida conference 2025 ist geöffnet!
Wir freuen uns, Ihnen mitteilen zu können, dass unsere dritte dida conference am 23. Mai 2025 im frizzforum in Berlin stattfinden wird. Was im Jahr 2023 als Experiment begann, hat sich zu einer mit Spannung erwarteten Veranstaltung entwickelt. Dieses Jahr ziehen wir in einen größeren Veranstaltungsort um, um der großen Nachfrage der vergangenen Jahre gerecht zu werden.
Die Konferenz wird wieder eine Mischung aus technischen und angewandten Vorträgen zu KI und Machine Learning bieten. In den vergangenen Jahren hatten wir Referenten und Panelisten von Unternehmen wie Google, der Bundesdruckerei-Gruppe, idealo internet GmbH, Enpal und APCOA Group GmbH. Für 2025 arbeiten wir daran, ein ebenso beeindruckendes Programm auf die Beine zu stellen.
Da die Plätze begrenzt sind, empfehlen wir Ihnen, sich frühzeitig anzumelden, um sich Ihren Platz zu sichern. Die Anmeldung ist kostenlos!
Sie können sich jetzt auf unserer offiziellen Konferenzseite für die Konferenz anmelden.
Um einen Einblick in die letztjährige Veranstaltung zu bekommen, sehen Sie sich hier das Highlight-Video an.
dida auf dem idealo Collaboration Day
Ende letzten Jahres folgte unser Machine Learning Scientist Marty Oelschläger einer Einladung der idealo internet GmbH und Jan Anderssen, um über „Automatische Produktgenerierung: Auf dem Weg zum Preisvergleich für den Gesamtkatalog“.
In der gemeinsamen Präsentation auf dem idealo Collaboration Day stellten Jan und Marty ihre Entity-Matching-Lösung vor, die mit einer Kombination aus schnellem Retrieval und hochpräzisem Matching Angebote aus dem riesigen idealo-Katalog automatisch zu Produkten und Varianten gruppiert.
Wir haben die Veranstaltung sehr genossen, bei der verschiedene idealo-Teams zusammenkommen und sich gegenseitig über relevante Entwicklungen innerhalb ihrer Abteilungen informieren.
Nochmals vielen Dank, Jan Anderssen, für die Einladung und die Möglichkeit, unser Projekt vorzustellen - es ist immer eine lohnende Herausforderung, mit den großen Datenmengen von idealo zu arbeiten.
(Fotograf: Stefan Hähnel)
2024
dida auf dem PyData Berlin Meetup: Anomalieerkennung in Gleisszenen
Am 20. November präsentierte Maximilian Trescher auf der PyData Berlin 2024 unsere Arbeit zum Thema „Anomaly Detection in Track Scenes“.
In Zusammenarbeit mit der Deutschen Bahn im Rahmen der Initiative Digitale Schiene Deutschland haben wir eine Machine-Learning-Lösung entwickelt, um gefährliche und anomale Objekte auf Bahngleisen mit Hilfe von Onboard-RGB-Kameras zu erkennen. Das System identifiziert nicht nur vordefinierte Klassen, sondern ordnet die Objekte nach dem Grad der Anomalie ein.
Maximilian sprach über Entwicklungsaspekte wie die Verwendung des OSDAR23-Datensatzes und selbstüberwachtes Lernen sowie Herausforderungen, wie die Entwicklung unserer Multikomponenten-Pipeline inkl. mit Tiefenschätzung, Segmentierung und Anomalieerkennung.
Wir sind der PyData Berlin dankbar für die Möglichkeit, dieses Projekt mit der Community zu teilen. Wir bedanken uns bei allen, die den Vortrag besucht und sich an den anschließenden Diskussionen beteiligt haben.
dida entwickelt In-terra-gate: neue Ansätze zur Satellitendatenanalyse mit natürlicher Sprache
dida freut sich, „In-terra-gate“ anzukündigen, unser neuestes Projekt zur Analyse von Satellitendaten anhand natürlicher Sprache. Diese Initiative nutzt Fortschritte in den Bereichen Large Language Models (LLMs), Natural Language Processing (NLP) und Bildverarbeitungsmodellen, um ein intuitives Werkzeug zu schaffen, das komplexe Satellitendaten anhand eines Chatbots in verwertbare Erkenntnisse umwandelt. Das Projekt ist ein Kickstart-Projekt der ESA und ermöglicht es den Nutzenden, Geodaten in natürlicher Sprache abzufragen und genaue Antworten auf geologische und geografische Merkmale in Satellitenbildern zu erhalten.
In-terra-gate verwendet Text-Bild-Einbettungen, die auf hochauflösenden Sentinel-2-Satellitendaten trainiert wurden, um Einblicke in städtische Gebiete, Wohngebiete und Regionen, die Naturgefahren ausgesetzt sind, zu geben. Dieses Tool wurde mit Blick auf Versicherungsunternehmen entwickelt, da diese genaue Echtzeitdaten benötigen, um individuelle Eigentumsrisiken zu bewerten und Schadensfälle, z. B. für Hausbesitzer und Landwirte, zu beschleunigen. Mit In-terra-gate entwickelt dida eine neue Methode bzgl. der Zugänglichkeit von Satellitendaten und bietet auch technisch nicht-versierten Nutzenden die Möglichkeit, das Potenzial komplexer Satellitendatenanalysen in verschiedenen Szenarien und Branchen intuitiv zu nutzen.
dida auf der “data2day-Konferenz"
Jakob Scharlau, ML Scientist bei dida, hielt auf der data2day-Konferenz einen Vortrag zum Thema „Semantische Suche und maschinelles Lernen“: Finden Sie das richtige Dokument“. Sein Vortrag führte die Zuhörer in die Verwendung von maschinellem Lernen und vortrainierten Sprachmodellen ein, um semantische Suchsysteme zu entwickeln, die Texte kontextuell verstehen.
Er hob die jüngsten Fortschritte bei Texteinbettungen und großen Sprachmodellen (LLMs) hervor und gab einen technischen Überblick über moderne Ansätze zum Aufbau maßgeschneiderter Suchlösungen. Anhand von Beispielen aus realen Projekten zeigte er, wie diese Techniken implementiert werden, um die Suchgenauigkeit und Relevanz zu verbessern.
Sein Ziel war es, eine umfassende und dennoch zugängliche Einführung zu geben, die es den Teilnehmern mit jeglichem technischen Fachwissen ermöglicht, ein Verständnis für Einbettungstechniken, ihre Entwicklung und praktische Anwendungen der domänenspezifischen semantischen Suche zu erlangen.
Wir danken data2day für die Gelegenheit, einen Beitrag zur Weiterentwicklung der Daten- und KI-Expertise in der Branche leisten zu können.
dida bei der Generative AI Exchange
dida freute sich, an der Generative AI Exchange in der Celonis-Zentrale in München teilzunehmen, wo über 130 KI-Entwickler, Spezialisten und Führungskräfte zusammenkamen, um die neuesten Fortschritte in der KI zu erkunden.Fabian Dechent,ML Scientist bei dida, leitete einen praktischen Workshop, in dem er Erkenntnisse aus dem Einsatz eines Echtzeit-Kennzeichenabgleichsdienstes für unseren Kunden APCOA vermittelte.
Fabians Vortrag konzentrierte sich auf die Optimierung der Leistung eines TrOCR-basierten OCR-Systems, das auf die Verarbeitung von Bildern mit schlechter Qualität oder teilweise abgeschnittenen Nummernschildern zugeschnitten ist. Er behandelte Techniken zur Verbesserung der Genauigkeit durch metrisches Lernen und überwachtes Lernen sowie Einsatzstrategien unter Verwendung von Nvidia Triton als Microservice.
Wir möchten uns bei Celonis, NVIDIA und KI Park für die inspirierende Atmosphäre und bei den Teilnehmern für ihren Enthusiasmus und ihr Engagement bedanken. Vielen Dank an das Generative AI Exchange Team für die Möglichkeit, zu dieser interessanten Veranstaltung beizutragen!
dida leistet mit dem Projekt KAMI einen Beitrag zum X-KIT Cluster Computer Vision White Paper
Wir freuen uns, Ihnen mitteilen zu können, dass dida einen Beitrag zum kürzlich veröffentlichten Whitepaper des X-KIT Clusters Computer Vision geleistet hat. Das Whitepaper wurde im Rahmen des vom Bundesministerium für Ernährung und Landwirtschaft (BMEL) geförderten und von der Bundesanstalt für Landwirtschaft und Ernährung (BLE) unterstützten X-KIT-Projekts entwickelt und stellt acht innovative Projekte vor, die Computer Vision zur Bewältigung von Herausforderungen in der Land- und Viehwirtschaft einsetzen. Das X-KIT-Projekt fördert die Zusammenarbeit zwischen KI-Initiativen in diesen Sektoren, um Synergien zu maximieren und redundante Anstrengungen zu minimieren.
Unser Beitrag stammt aus dem KAMI-Projekt, in dem wir einen Prototyp entwickelt haben, der bildbasierte Technologie zur automatischen und genauen Messung der Atemfrequenz einzelner Milchkühe einsetzt. Dieses System hilft den Landwirten, den Gesundheitszustand ihrer Tiere effizienter und nicht-invasiv zu überwachen.
Wir freuen uns, dass wir gemeinsam mit anderen Teilnehmern erforschen konnten, wie Computer Vision praktische, wirkungsvolle Lösungen in diesen Bereichen schaffen kann.
Fast Forward Future an der Eberhard Karls University of Tübingen
Letzte Woche hielt unser Forscher für maschinelles Lernen, Dr. Jan Macdonald, einen Vortrag auf der Interdisziplinären Fachtagung mit dem Titel Fast Forward Future an der Eberhard Karls Universität Tübingen.
Jan stellte unser Forschungsprojekt PretrainAppEO vor, das Transfer-Learning- und Meta-Learning-Techniken für die Erdbeobachtung erforscht. Sein Vortrag konzentrierte sich auf die Klassifizierung von Kulturpflanzen anhand von Satellitenbildern, einer Schlüsselanwendung in der Landwirtschaft und der Umweltüberwachung.
Der Vortrag war als „Impulsvortrag“ konzipiert, mit dem Ziel, den Zuhörern verschiedene Transfer-Learning-Methoden vorzustellen. Jan hob die Relevanz dieser Methoden bei der Anpassung von Modellen an neue Aufgaben mit begrenzten Daten hervor, ebenso wie den Wert des Meta-Lernens, das es Modellen ermöglicht, schnell aus neuen Umgebungen zu lernen, was besonders wichtig für die Analyse von Satellitendaten unter wechselnden Bedingungen ist.
Die Veranstaltung brachte Experten aus verschiedenen Bereichen wie maschinelles Lernen, Umweltwissenschaften und Datenanalyse zusammen. Wir sind dankbar für die Gelegenheit, unsere Arbeit vorzustellen und zu Diskussionen darüber beizutragen, wie KI Herausforderungen in der Erdbeobachtung, insbesondere in der Landwirtschaft und der Landnutzung, angehen kann.
Wir danken der Eberhard Karls Universität Tübingen für die Ausrichtung dieser Veranstaltung und freuen uns auf eine weitere Zusammenarbeit.
Projektstart von LLM4Anamnese: Automatisierung und Standardisierung von Anamnesetexten
Das Projekt LLM4Anamnese zielt darauf ab, Large Language Models (LLMs) zu nutzen, um die häufig in Freitextform erfassten Anamnesen automatisch zu klassifizieren und mit standardisierten medizinischen Fachterminologien zu verknüpfen. Diese Automatisierung erleichtert nicht nur die Weiterverarbeitung der Texte in digitalen Systemen, sondern verbessert auch die Datenqualität, ohne die individuellen Aspekte der Patientengeschichten zu verlieren.
Ein besonderer Fokus des Projekts liegt darauf, zu erforschen, wie ressourceneffizient und robust LLMs in der Praxis arbeiten können. Die Anwendung im klinischen Alltag wird unter realen Bedingungen getestet, um sicherzustellen, dass die Technologie die hohen Anforderungen des Gesundheitswesens erfüllt. Die Anpassung der LLMs an medizinische Daten ist dabei ein zentraler Schritt, um die Klassifizierung von Texten zu optimieren und die Ergebnisse für weitere medizinische Anwendungen nutzbar zu machen.
Langfristig soll das Projekt dazu beitragen, das medizinische Personal zu entlasten und die Qualität der Patientenversorgung zu verbessern.
dida besuchte AI & Data Summit und Quantum Summit des Bitkom
dida hatte die Gelegenheit, am AI & Data Summit und Quantum Summit teilzunehmen, die kürzlich vom Bitkom veranstaltet wurden. Die Veranstaltung brachte bedeutende Unternehmen aus dem KI- und Technologiesektor zusammen, die ihre innovativen KI-Lösungen vorstellten und sich mit aktuellen Herausforderungen und Zukunftsperspektiven in diesem Bereich befassten.
Ein wesentlicher Schwerpunkt des Summits lag auf den lokalen deutschen Entwicklungen, wobei die Beiträge zu den globalen Fortschritten hervorgehoben wurden. Themen wie Large Language Models (LLMs), generative KI, verantwortungsbewusste KI und modernste Tools wurden ausführlich diskutiert, mit wichtigen Einblicken in ihre Auswirkungen auf Industrie und Gesellschaft.
Wir freuen uns darauf, die gewonnenen Erkenntnisse anzuwenden und auch in den kommenden Jahren an der Spitze des Fortschritts in der KI zu stehen.
Vorträge der dida conference 2024 jetzt online verfügbar
Wir freuen uns, Ihnen mitteilen zu können, dass alle Vorträge der dida conference 2024 nun auf unserer Website und unserem Youtube-Kanal abrufbar sind. Die diesjährige Konferenz bot ein, wie wir finden, beeindruckendes Aufgebot an BranchenexpertInnen und WissenschaftlerInnen, die tiefe Einblicke in die neuesten Fortschritte in den Bereichen Data Science und KI gaben. Unabhängig davon, ob Sie an der Veranstaltung teilgenommen haben oder nicht, können Sie jetzt auf die gesamte Bandbreite der Präsentationen und Diskussionen zugreifen, wenn Sie möchten.
Besuchen Sie unseren Kanal, um die Präsentationen zu erkunden. Hier haben Sie die Möglichkeit, die wichtigsten Momente der Konferenz noch einmal anzusehen und die Sitzungen nachzuholen, die Sie vielleicht verpasst haben.
Durchbrüche bei Diffusionsmodellen auf der ICML vorgestellt
Unser CTO, Lorenz Richter, nahm kürzlich an der International Conference on Machine Learning (ICML) in Wien teil.
Auf der Konferenz präsentierte Lorenz unser Papier "Bridging Discrete and Continuous State Spaces: Exploring the Ehrenfest Process in Time-Continuous Diffusion Models" vor.
Das Papier machte bedeutende Fortschritte im Verständnis der generativen KI, indem es zeitkontinuierliche Diffusionsmodelle im diskreten Raum untersuchte. Es stellt eine Verbindung zwischen diesen Modellen und der weit verbreiteten score-based generativen Modellierung her, die vor allem bei der Bilderzeugung eingesetzt wird.
Sie können das Papier [hier] lesen (https://arxiv.org/pdf/2405.03549).
Start des Projekts GENIAL4KMU: Fortschrittliche KI-Lösungen für KMU
Wir freuen uns, den offiziellen Beginn unseres Projekts GENIAL4KMU bekanntzugeben. Dieses Projekt zielt darauf ab, ein fortschrittliches Retrieval-Augmented-Generation-System (RAG-System) zu entwickeln, das unstrukturierte Datenbestände in Unternehmen effektiv nutzbar macht.
GENIAL4KMU nutzt die neuesten Fortschritte im Bereich der Künstlichen Intelligenz, insbesondere große Sprachmodelle (LLMs), um Unternehmen eine präzise und kontextualisierte Datenverarbeitung zu ermöglichen.Das Projekt ist in Zusammenarbeit mit unserem Partner, der Universität Hamburg Hub of Computing & Data Science, organisiert und in zwei Phasen unterteilt:
Erste Phase: Strukturierte Daten
Hier wird zunächst ein parametereffizientes Fine-Tuning von LLMs durchgeführt, gefolgt von der Entwicklung eines RAG-Systems zur Verarbeitung strukturierter Daten.
Zweite Phase: Unstrukturierte Daten
In dieser Phase wird das System auf unstrukturierte Unternehmensdaten ausgeweitet, einschließlich weiterem Fine-Tuning und Integration in das RAG-System.
Die entwickelten Lösungen werden kontinuierlich evaluiert und in Demonstratoren überführt, um sicherzustellen, dass sie den höchsten Standards entsprechen und den Bedürfnissen der KMU gerecht werden.
Zusammenfassend GENIAL4KMU stellt einen bedeutenden Schritt in der Anwendung von KI-Technologien dar, mit dem Ziel, die Effizienz und Wettbewerbsfähigkeit kleiner und mittlerer Unternehmen nachhaltig zu steigern.
dida Sommerworkshop 2024
Wir freuen uns, auf einen weiteren großartigen dida-Sommerworkshop zurückblicken zu können, der am 4. und 5. Juli 2024 stattfand. Zwei Tage lang traf sich unser Team zu einer Reihe von spannenden und kooperativen Sitzungen, die die Teamarbeit verbessern, die Kreativität anregen und die Beziehungen zwischen den Kollegen stärken sollten.
Der Workshop umfasste eine Vielzahl von Aktivitäten, darunter ein Survival Camp, strategische Workshops und die Möglichkeit, einige unserer neuen Kollegen besser kennenzulernen. Die Teilnehmer konnten Ideen austauschen, Branchentrends diskutieren und neue Strategien für künftige Projekte erkunden. Wir danken allen, die teilgenommen und dazu beigetragen haben, dass dieser Workshop zu einem unvergesslichen und produktiven Erlebnis wurde. Die in diesen zwei Tagen gewonnenen Erkenntnisse und Verbindungen werden unserer künftigen Arbeit zweifellos zugute kommen.
Bleiben Sie dran für weitere Aktualisierungen und spannende Veranstaltungen in der Zukunft!
Teilnahme am Branchen-Blick 2024 in der Berliner Volksbank
Am 10. Juli fand der Branchen-Blick Digital- und Kreativwirtschaft in der Berliner Volksbank statt. Branchenführer, Innovatoren und Fachleute aus der Digital- und Kreativwirtschaft kamen zusammen, um die neuesten Trends, Herausforderungen und Möglichkeiten der Branche zu diskutieren.
Die Teilnehmer genossen einen Abend, der dem Networking, dem Austausch von Ideen und der Suche nach Inspiration gewidmet war. Die Veranstaltung bot eine wertvolle Gelegenheit, während der Get-together-Sitzung mit anderen Branchenexperten in Kontakt zu treten, neue Ideen zu entwickeln und innovative Wege zum Wachstum ihrer Unternehmen zu erkunden.
Die Veranstaltung, die für ihre aufschlussreichen Sitzungen und Networking-Möglichkeiten bekannt ist, erwies sich erneut als wichtige Plattform zur Förderung von Zusammenarbeit und Innovation. Die Teilnehmer hatten die Möglichkeit, sich mit Vordenkern auszutauschen und an Diskussionen teilzunehmen, die die Zukunft der Digital- und Kreativbranche prägen werden.
dida veröffentlicht neue Forschung im Journal of Machine Learning Research (JMLR)
Wir freuen uns, dass unsere Forschungsergebnisse im Journal of Machine Learning Research (JMLR), einer der angesehensten Fachzeitschriften auf diesem Gebiet, veröffentlicht worden sind. Sie finden den Artikel hier.
Diese neue Arbeit baut auf einem früheren Forschungspapier von uns auf, das für seinen Beitrag zur generativen Modellierung und zum optimalen Transport bereits auf der ICML’21 mit einem ‘Outstanding Paper’-Award ausgezeichnet wurde. In dieser Folgearbeit werden die zugrunde liegenden mathematischen Konzepte näher beleuchtet und praktische Methoden für die Arbeit mit hochdimensionalen und komplexen Daten vorgestellt. Außerdem werden neue Wege zur Lösung verwandter Optimierungsprobleme erforscht und es wird gezeigt, wie diese Ansätze in der Praxis angewendet werden können.
Wir freuen uns, dass sich unsere Forschung weiterentwickelt und wir einen weiteren Beitrag zu diesem Thema leisten können. Vielen Dank an JMLR für die Veröffentlichung unserer Arbeit und an alle, die uns auf unserem Weg unterstützt haben.
Teilnahme an Tangere24
Letzte Woche hatten wir das Vergnügen, an der Tangere24 teilzunehmen, die von Siemens Global Marketing Services (GMS) in Berlin veranstaltet wurde. Siemens GMS ist bekannt für seine Expertise in den Bereichen Marketing, Vertrieb und Kommunikation und möchte KI-Nutzung innerhalb ihrer Services ausbauen.
Unser Geschäftsführer Philipp Jackmuth und Jan Macdonald, Machine Learning Scientist, vertraten uns bei der Veranstaltung. Sie hatten die Gelegenheit, wertvolle Einblicke in die umfassenden KI-Strategien von Siemens zu gewinnen und zu erkunden, wie KI die globalen Prozesse des Unternehmens verändert.
Die Veranstaltung umfasste gemeinsame Workshops, die sich auf die Entwicklung praktischer Lösungen für reale Herausforderungen in Marketing, Vertrieb und Kommunikation konzentrierten. Sie bot eine dynamische Plattform für eine sinnvolle Interaktion mit KI-Experten, die die neuesten Fortschritte und Best Practices diskutierten. Wir hatten die Gelegenheit, uns direkt mit dem Siemens GMS-Team auszutauschen, wertvolle Kontakte zu knüpfen und das Potenzial für gemeinsame Initiativen auszuloten.
Wir danken dem Siemens-Team für diese aufschlussreiche Veranstaltung und freuen uns auf zukünftige Kooperationen.
Lorenz Richter hält Vortrag am Fields Institute in Kanada
Am Montag, den 8. Juli 2024, hielt Lorenz Richter, CTO der dida, einen Vortrag auf dem Fourth Symposium on Machine Learning and Dynamical Systems, das vom Fields Institute in Kanada, einem führenden Zentrum für mathematische Forschung, ausgerichtet wurde.
Sein Vortrag untersuchte die generative Modellierung durch die Linse des Maßtransports und beschrieb sie als ein dynamisches System, das sich von einer Anfangsverteilung zu einem Zielmaß entwickelt. Lorenz zeigte auf, wie dieser Prozess, der durch Differentialgleichungen wie gewöhnliche Differentialgleichungen (ODEs) oder stochastische Differentialgleichungen (SDEs) gesteuert wird, mit partiellen Differentialgleichungen (PDEs) zusammenhängt, und demonstrierte praktische Berechnungsansätze. Er erörterte rückwärts gerichtete stochastische Differentialgleichungen (BSDEs), die eine Verbindung zur optimalen Steuerung herstellen, und PINNs, die das Training vereinfachen, indem sie die Simulation von Trajektorien vermeiden.
Wir danken dem Fields Institute für die Ausrichtung dieser anregenden Veranstaltung und den Zuhörern für ihre aufmerksamen Fragen und ihr Interesse.
Unsere Erfolgsgeschichte mit Enpal wurde von Google veröffentlicht
Wir freuen uns, bekannt zu geben, dass unsere Erfolgsgeschichte mit Enpal, einem führenden Solarunternehmen, von Google veröffentlicht wurde.
Enpal, bekannt für ihre innovativen Solarlösungen, sah sich aufgrund des umfangreichen manuellen Arbeitsaufwands in ihren Abläufen erheblichen Herausforderungen gegenüber. Die manuelle Erstellung individueller Angebote dauerte in der Regel 120 Minuten pro Person und Verkaufsangebot, was zu Ineffizienz und Ressourcenbeschränkungen führte.
Als Antwort auf diese Herausforderungen haben wir ein speziell auf die Bedürfnisse von Enpal zugeschnittenen Machine-Learning-Service entwickelt. Unsere Lösung hat ihren Arbeitsablauf revolutioniert und einen erheblichen Teil der manuellen Aufgaben automatisiert. Infolgedessen dauert das, was früher 120 Minuten in Anspruch nahm, jetzt nur noch 15 Minuten pro Person – eine erstaunliche Zeitersparnis von 87,5 %.
Unser ML-Produkt spart nicht nur Zeit, sondern erhöht auch die Genauigkeit der Schätzungen für Solarmodule auf etwa 93 %. Als wir die Software 2019 erstmals einführten, nutzten 13 Mitarbeiter bei Enpal sie. Heute, vier Jahre später, ist diese Zahl auf 150 Mitarbeiter gestiegen. Jeder dieser Mitarbeiter kann nun 87,5 % seiner Zeit sparen und sich auf spezialisierte und wirkungsvollere Aufgaben konzentrieren.
Wir danken Google herzlich dafür, dass sie unsere Geschichte geteilt haben. Ihre Unterstützung hilft uns, die transformative Kraft unserer Machine-Learning-Lösungen zu zeigen.
Die vollständige Geschichte können Sie hier im Google Cloud Blog lesen.
Konferenz zur digitalen Landwirtschaft 2024
Wir freuen uns, Einblicke von der Digital Farming Conference 2024 zu geben, die vom Bitkom ausgerichtet wurde. Vertreten durch Julius Lauenstein beteiligte sich dida aktiv an den Diskussionen auf dieser wichtigen Veranstaltung, die sich mit der digitalen Transformation der Land- und Ernährungswirtschaft befasste. Zu den wichtigsten Themen gehörten Fortschritte in der Präzisionslandwirtschaft, Smart Farming und die Nutzung von KI und IoT für das Management von Nutztieren, die Verbesserung des Tierschutzes und die Förderung nachhaltiger Praktiken.
Die Konferenz beleuchtete Fortschritte in der Präzisionslandwirtschaft und konzentrierte sich auf KI-gesteuerte Anwendungen zur Ressourcenoptimierung und sensorbasierte Technologien. Bei dida arbeiten wir regelmäßig an verschiedenen Projekten im Bereich der Fernerkundung, wie z. B. der Klassifizierung von Nutzpflanzen, was unser Engagement für die Verbesserung der landwirtschaftlichen Effizienz und Nachhaltigkeit unterstreicht.
Ein weiterer Schwerpunkt der Veranstaltung war unser Projekt KAMI, das sich der Verbesserung der Tiergesundheit und des Wohlbefindens von Tieren widmet und sich mit der "Transformation der Tierhaltung" beschäftigt. Damit wurden die Bemühungen der dida zur Förderung tiergerechterer und nachhaltigerer landwirtschaftlicher Praktiken unterstrichen.
Als aktives Mitglied der Innovations-Community, die das Panel organisiert hat, setzen wir uns gemeinsam mit Partnern wie der DLR-Gruppe und Space2Agriculture für innovative Lösungen ein, die die Zukunft der Landwirtschaft gestalten.
AMoKI-Projekt: Innovationen für nachhaltiges Abgrabungsmonitoring in Deutschland
Das AMoKI-Projekt (Autonomes Abgrabungsmonitoring im Locker- und Festgestein auf Basis von Fernerkundungsdaten für ein nachhaltiges Flächenmanagement) hat offiziell begonnen und strebt eine wegweisende Lösung für das Flächenmanagement in Deutschland in Bezug auf Abgrabungsmonitoring an. Angesichts der hohen Anforderungen an ein nachhaltiges Flächenmanagement und der Sicherstellung der Versorgung mit Steine- und Erden-Rohstoffen (S&E-Rohstoffe) ist die Entwicklung eines (teil-)automatisierten Systems von entscheidender Bedeutung.
Die aktuellen Methoden zur Erfassung der Abgrabungsflächen und -statistiken in vielen Bundesländern erweisen sich als unzureichend für ein zeitgemäßes Flächenmanagement. Mangelnde Transparenz und Nachvollziehbarkeit sowie ein hohes Digitalisierungspotenzial kennzeichnen diese Verfahren.
Das AMoKI-Projekt hat es sich zum Ziel gesetzt, diese Lücken zu schließen. Durch die industrielle Erforschung eines Machine Learning (ML)-basierten Systems werden Behörden- und Satellitenbilddaten genutzt, um ein Abgrabungsmonitoring von S&E-Gewinnungsbetrieben durchzuführen. Das KI-System ermöglicht die Erfassung, Mustererkennung und Nachverfolgung der Landnutzung sowie Landnutzungsänderungen durch S&E-Betriebe, wobei auch 3D-Volumina berücksichtigt werden.
Das AMoKI-Projekt setzt somit einen wichtigen Meilenstein auf dem Weg zu einem nachhaltigen Flächenmanagement in Deutschland und trägt dazu bei, die heimische Rohstoffversorgung langfristig zu sichern.
FewTuRe: KI für KMU-Dokumentenautomatisierung
Unser neues Projekt, "FewTuRe", adressiert die Automatisierung und Digitalisierung von Prozessen in kleinen und mittleren Unternehmen (KMU), insbesondere im Bereich der Dokumentenverarbeitung.
Durch die Anwendung von Künstlicher Intelligenz (KI) und Natural Language Processing (NLP) können manuelle, repetitive und fehleranfällige Arbeiten, wie die automatisierte Informationsextraktion (IE) aus semi-strukturierten Dokumenten, optimiert werden.
Im Rahmen des Vorhabens wird ein KI-Modell entwickelt, das relevante Informationen zuverlässig extrahiert und eine dateneffiziente Lernmethode namens Few-Shot-Learning angewendet. Ziel ist es, das Ausgangsmodell mit nur wenigen Datenbeispielen an unternehmensspezifische Aufgaben anzupassen. Dabei werden vortrainierte Text-Layout-Modelle für die Zielanwendung optimiert und ein mehrsprachiger Datensatz verwendet, um die Modelle für verschiedene Sprachen anzupassen.
dida übernimmt die Projektleitung und ist für die Modellimplementierung sowie die Entwicklung des Prototyps verantwortlich. Der Lehrstuhl für Machine Learning der HU Berlin unterstützt das Projekt mit Grundlagenforschung zu Text-Layout-Modellen und der Few-Shot-Methode.
Vortrag auf der data2Day Konferenz
Unser ML-Scientist Jakob Scharlau wird einen Vortrag auf der data2day-Konferenz zum Thema "Semantische Suche und ML: Das passende Dokument finden" halten.
Der Vortrag findet am 18. und 19. September 2024 in Heidelberg statt und gibt eine Einführung, wie Machine Learning und vortrainierte Sprachmodelle helfen, Suchsysteme mit semantischem Textverständnis zu entwickeln.
Er wird einen Überblick über die technischen Entwicklungen der letzten Jahre, wie z.B. Text-Embeddings und die Verwendung von LLMs geben sowie die verschiedenen Möglichkeiten zur Implementierung von maßgeschneiderten Suchalgorithmen anhand konkreter Kundenprojekte diskutieren.
dida conference 2024
Am 31. Mai 2024 veranstalteten wir unsere zweite dida conference.
Die Konferenz brachte rund 250 KI-Enthusiasten und Fachleute zusammen, die ihr Wissen über Machine Learning, MLOps und govTech erweitern wollten.
Mit Beiträgen von dida, aber auch der Bundesdruckerei, Eversheds Sutherland, appliedAI oder Deutschlands führenden Forschungsinstituten, bekamen Gäste einen ausgewogenen Mix aus theoretischen und angewandten KI-Themen geboten.
Wissenschaftler, Ingenieure und Führungskräfte hatten die Möglichkeit, Keynote-Vorträge zu besuchen, an interaktiven Workshops teilzunehmen oder in der Postersession neueste KI-Forschung zu diskutieren.
Um nur einige Highlights zu nennen:
Holger Pannhorst, Head of Data & Analytics bei der Bundesdruckerei, hielt einen Vortrag zum Thema „New Opportunities: applications of machine learning technologies in the public sector“. Er zeigte auf, wie ML-Anwendungen Einzug in öffentliche Prozesse gehalten haben und wie sie bereits Effizienzen erhöhen und Transparenz verbessern.
Christian Dürschmied, Rechtsanwalt bei Eversheds Sutherland, gab Einblicke in die rechtlichen Implikationen von generativer KI und großen Sprachmodellen, welche rechtlichen Rahmenbedingungen bereits bestehen und wo die EU-Gesetzgebung in Zukunft wahrscheinlich weitere Richtlinien entwickeln wird.
Julius Richter von der Universität Hamburg sprach darüber, wie generative Modelle Audio- und Sprachdaten verbessern können. Im Rahmen seiner Forschung präsentierte er eine Methode zum Erlernen von Verteilungen sauberer Sprach- und Audioinhalte bei unsauberem Input und erläuterte, wie ein kombinierter Ansatz aus Vorhersagemodellen und generativer KI die Audio- und Sprachverarbeitungstechnologien erheblich verbessern könnte.
Da es bei der dida-Konferenz nicht ausschließlich ums Lernen ging, war es auch großartig den regen Austausch und die neu geknüpften Bekanntschaften zu sehen sowie den langen Tag mit Live-Musik und einem Cocktail ausklingen zu lassen.
Wir freuen uns sehr über die vielen positiven Rückmeldungen, die wir bereits erhalten haben und möchten uns bei allen Teilnehmer/innen bedanken, die unsere zweite dida conference wieder zu einem echten Erfolg gemacht haben.
Aufzeichnungen der Vorträge und weitere Eindrücke des Tages folgen in Kürze.
Gastgeber für die KAMI-Projektpartner bei dida
Vor zwei Wochen hatten wir die Freude, unsere Partner aus dem KAMI Projekt bei dida zu begrüßen.
Vertreter des Leibniz-Instituts für Agrartechnik und Bioökonomie (ATB), der Universität Hildesheim, der Lehr- und Versuchsanstalt für Tierhaltung (LVAT) und von Wille Engineering waren bei uns zu Gast, um den Fortschritt und die nächsten Schritte unseres gemeinsamen Forschungsprojekts zur Überwachung der Atemfrequenz von Milchkühen zu besprechen.
Ziel dieser Initiative ist es, den Tierschutz durch den Einsatz fortschrittlicher KI- und Sensortechnologie zu verbessern.
Da sich das Projekt seinem Ende nähert, konzentrierten sich unsere Diskussionen aktuell darauf, einen erfolgreichen Abschluss sicherzustellen und die Auswirkungen des Projekts auf die Milchviehhaltung zu maximieren. Das KAMI Projekt zielt darauf ab, die Gesundheit und das Wohlbefinden der Tiere zu verbessern und ein Frühwarnsystem zur Erkennung von Stress und Krankheiten bereitzustellen.
Wir sind stolz auf unsere Zusammenarbeit und darauf, gemeinsam die Präzisionslandwirtschaft und den Tierschutz voranzubringen.
Forschungspapier im Journal "Transactions on Machine Learning Research" veröffentlicht
Unser Papier „An optimal control perspective on diffusion-based generative modeling“ wurde von dem Journal Transactions on Machine Learning Research (TMLR), einem der führenden Journale im Bereich Machine Learning, angenommen.
Die Arbeit stellt eine Verbindung zwischen stochastischer optimaler Steuerung und diffusionsbasierten generativen Modellen her. Diese Perspektive erlaubt es, Methoden aus der optimalen Kontrolltheorie auf die generative Modellierung zu übertragen und z.B. eine untere Schranke der Evidenz als direkte Folge des bekannten Verifikationssatzes aus der Kontrolltheorie abzuleiten.
Darüber hinaus wird eine neuartige diffusionsbasierte Methode für das Sampling aus unnormalisierten Dichten entwickelt - ein Problem, das in der Statistik und den Computerwissenschaften häufig auftritt.
Zwei akzeptierte Paper auf der ICLR
Wir freuen uns, ankündigen zu können, dass zwei Papers mit dida-Beteiligung in den Proceedings der diesjährigen International Conference on Learning Representations (ICLR) erscheinen werden, die Anfang Mai in Wien stattfinden wird. Die ICLR ist neben der NeurIPS und der ICML eine der drei wichtigsten Konferenzen für Machine Learning.
In dem Paper Improved sampling via learned diffusions wird untersucht, wie das Sampling aus bestimmten Wahrscheinlichkeitsdichten über Diffusionsprozesse angegangen werden kann, bei denen die Drift über neuronale Netze gelernt wird. Es wird die Perspektive der Pfadraum-Maße vorgeschlagen, die es erlaubt, bestehende Methoden wie Schrödinger-Bridges oder „diffusion based generative modeling“ zu verallgemeinern. Diese neue Perspektive erlaubt es, effizientere Loss-Funktionen zu entwerfen, welche zu erheblichen Verbesserungen in numerischen Experimenten führen können.
Das Paper Fast and unified path gradient estimators for normalizing flows schlägt effizientere Algorithmen für das varianzreduzierte Training von Normalizing Flows für das Sampling aus komplexen Wahrscheinlichkeitsverteilungen vor, die zum Beispiel in der Physik oder der Molekulardynamik auftreten. Weiterhin wird gezeigt, wie Methoden zur Varianzreduktion auf das Likelihood-Training angewandt werden können, was relevant ist, wenn Samples auf der Zielverteilung verfügbar sind.
Wir freuen uns sehr, dass wir unseren Anspruch, bei dida Spitzenforschung zu betreiben und Beiträge für die ML-Community zu leisten, fortsetzen können.
dida-Konferenzprogramm jetzt verfügbar!
Wir freuen uns, Ihnen mitteilen zu können, dass das Programm für die kommende dida conference veröffentlicht wurde hier.
Die diesjährige Veranstaltung bietet eine Vielzahl von Workshops und Vorträgen, die sich auf LLMs und MLOps konzentrieren, darunter spannende Sessions wie Fabian Dechents Vortrag über "Decision Process Automation with Large Language Models" und Anton Shemyakovs Vortrag zu "Flexible training pipelines with Pytorch Lightning and Hydra".
Darüber hinaus finden Sie interessante Programmpunkte, die sich mit ML-Anwendungen, der Forschung zum Meta- und Transferlernen auf der Basis von Computer Vision oder den rechtlichen Implikationen generativer KI beschäftigen.
Schauen Sie sich das vollständige Programm an und erleben Sie einen großartigen Tag des Wissensaustauschs im B-Part in Berlin.
dida besucht Institut für Kunststoffverarbeitung an der RWTH Aachen
Vor kurzem besuchten wir das Institut für Kunststoffverarbeitung in Industrie und Handwerk an der RWTH Aachen.
Gemeinsam mit unseren Partnern diskutierten wir unser gemeinsames Forschungsprojekt "KIOptipack", das darauf abzielt, KI-gestützte Werkzeuge zu entwickeln, um Produktdesign und Produktionsverfahren für Kunststoffverpackungen im Hinblick auf Nachhaltigkeit zu optimieren.
Während unseres Besuchs nahmen wir an einer Führung durch die Labore teil. So konnten wir die komplexen Geräte und Datensätze, die für unsere Arbeit unerlässlich sind, aus erster Hand kennenlernen und besser verstehen.
Wir sprachen über die verschiedenen Techniken zur Datenerweiterung, die speziell für verschiedene Messmodalitäten entwickelt wurden. Im Gegensatz zur intuitiven Anwendung von Augmentierungsmethoden bei visuellen Datensätzen, wie z. B. Bildern, wo Techniken wie Drehungen und Zooms üblich sind, haben wir eine gründliche Analyse durchgeführt, um maßgeschneiderte Strategien für eine optimale Augmentierung in unserem spezifischen Forschungskontext zu entwickeln.
Wir möchten dem Team des IKVs unseren Dank für die wertvollen Beiträge zu unserem Diskurs aussprechen und freuen uns, diese Erkenntnisse in unsere laufenden Forschungsbemühungen einfließen zu lassen.
Unser Fazit der Konferenz "Digitaler Staat 2024"
Wir freuen uns, unsere wichtigsten Erkenntnisse von der Konferenz "2024 Digitaler Staat" mit Ihnen zu teilen.
An zwei bereichernden Tagen hatten wir die Gelegenheit, faszinierende Anwendungen zu erkunden, uns an Diskussionen zum Thema KI zu beteiligen und wertvolle neue Perspektiven zu gewinnen.
Zwei herausragende Themen haben dabei besonders unsere Aufmerksamkeit erregt:
Ein Projekt von Nortal, in dem das Risiko der Langzeitarbeitslosigkeit von Bewerbern im estnischen Staat während der Corona-Periode vorhergesagt wurde, um die Berater im Arbeitslosenfonds zu unterstützen. Das Projekt ist ein technischer Erfolg und eine visionäre Anwendung. Wir freuen uns darauf, in naher Zukunft mit den Projektmitgliedern die Auswirkungen des AI-Gesetzes zu diskutieren.
Maßgeblich für die Softwareentwicklung im Rahmen des Onlinezugangsgesetzes (mit dem aktuellen Änderungsgesetz) wird der Servicestandard sein, der den Rahmen für Standards in der Softwareentwicklung und -beauftragung durch die öffentliche Hand bildet und vom DigitalService des Bundes in Abstimmung mit dem Nationalen Normenkontrollrat (NKR) entwickelt wurde. Der Servicestandard wird uns zunehmend bei unseren öffentlichen Aufgaben begleiten.
Wir freuen uns auf den Digitalen Staat 2025 und werden in diesem Jahr auf weiteren Konferenzen vertreten sein!
Die Anmeldung für unsere dida-Konferenz ist derzeit geöffnet!
Die dida-Konferenz im letzten Jahr war ein großer Erfolg mit Vorträgen zum Thema maschinelles Lernen, spannenden Panels und aufschlussreichen Workshops von Unternehmen wie Google, der TU München und codecentric. Wir waren begeistert von dem positiven Feedback und freuen uns, die Highlights der letztjährigen Veranstaltung mit Ihnen zu teilen. Klicken Sie unten zum Anschauen:
Sehen Sie sich die Highlights der letztjährigen Konferenz hier an.
Auf der diesjährigen dida-Konferenz haben Sie wieder die Möglichkeit, sich über die neuesten Entwicklungen im Bereich des maschinellen Lernens zu informieren. Hier ist, was Sie erwarten können:
◾ Vorträge zu wichtigen ML-Bereichen wie LLMs und MLOps
◾ Hands-on-Workshops zur aktiven Diskussion technischer ML-Aspekte im Detail
◾ Zeit für Networking mit anderen Enthusiasten und Branchenexperten
◾ Köstliche Küche zur Stärkung der geistigen Leistungsfähigkeit
◾ Außerdem gibt es Live-Musik und erfrischende Cocktails, um den Tag stilvoll ausklingen zu lassen.
Und das Beste daran? Wir haben noch einige freie Plätze für die Anmeldung, aber die sind schnell ausgebucht. Sie können sich Ihren Platz jetzt kostenlos sichern:
Melden Sie sich hier für die Konferenz an: https://dida.do/conference
𝐃𝐚𝐭𝐞: 31. Mai
𝐋𝐨𝐜𝐚𝐭𝐢𝐨𝐧: B-Teil Berlin
Wir freuen uns auf Ihre Teilnahme an der dida conference 2024.
Vortrag am California Institute of Technology
Unser CTO Lorenz Richter besuchte die Gruppe von Anima Anandkumar (Leiterin der Forschungsabteilung für Machine Learning bei NVIDIA und Bren-Professorin für Computertechnik) am Caltech in Los Angeles und hielt einen Vortrag über "diffusion-based generative modeling".
Es war eine tolle Gelegenheit, sich über die neuesten KI-Trends auszutauschen und etwas kalifornische Sonne zu tanken.
In seinem Vortrag ging Lorenz auf die Feinheiten der diffusionsbasierten generativen Modellierung ein. Der Vortrag stellte eine Verbindung zwischen generativer Modellierung auf der Basis von stochastischen Differentialgleichungen (SDEs) und drei Grundpfeilern der Mathematik her: stochastische optimale Kontrolle, partielle Differentialgleichungen (PDEs) und Pfadraummaße.
Der Vortrag zeigt, wie sehr sich die dida dafür einsetzt, aktiv zu mathematischer Forschung beizutragen, die Zusammenarbeit zwischen verschiedenen Fachgebieten zu fördern und auf internationaler Ebene mitzugestalten.
2023
Vortrag beim „Measure Transport, Diffusion Processes and Sampling Workshop“ in New York City
Lorenz Richter (Co-Founder & CTO der dida) folgte der Einladung zu einem Vortrag auf dem „Measure Transport, Diffusion Processes and Sampling Workshop“ im Flatiron Institute in New York City.
Der Workshop brachte Experten zu den mathematischen Aspekten des „diffusion-based generative modeling“ zusammen und bat eine gute Gelegenheit, sich mit anderen Wissenschaftlern auszutauschen.
In seinem Vortrag ging Lorenz auf Details des „diffusion-based generative modeling“ ein. Der Vortrag stellte eine Verbindung von „generative modeling“ auf der Basis von stochastischen Differentialgleichungen (SDEs) und drei grundlegenden Säulen der Mathematik her: stochastische optimale Steuerung, partielle Differentialgleichungen (PDEs) und Pfadraummaße.
Diese Präsentation spiegelt das Engagement von dida wider, mathematische Forschung im Machine Learning voranzutreiben.
Weitere Informationen zu dem Workshop finden Sie unter: https://events.simonsfoundation.org/event/335b8972-e63d-4672-82f3-4dd95868cb40/summary
Geschäftsführer Philipp Jackmuth gibt Einblicke im Data-Science-Podcast von INWT Statistics
Philipp Jackmuth war zu Gast in der neuesten Folge von "In Numbers We Trust - Der Data Science Podcast" der INWT Statistics GmbH.
Im Gespräch mit INWT's Geschäftsführer Amit Ghosh, sprachen die beiden über Machine-Learning-Projekte und deren Abgrenzung zu Projekten aus dem Bereich Data Science und klassischer Softwareentwicklung.
Philipp berichtete von Erfolgsfaktoren, die dida in vergangenen Projekten wieder und wieder identifizieren konnte, über die Bedeutung mehrdimensionaler Metriken bei der Bewertung von Machine-Learning-Modellen und über Strategien im Umgang mit Black-Box-Modellen.
Wir sagen vielen Dank an unsere Kolleg/innen von INWT für die Einladung und empfehlen Ihnen einmal in diese aber auch in andere sehr spannende Episoden des Podcasts reinzuhören.
Den Podcast finden Sie auf allen gängigen Plattformen sowie hier: https://inwt.podbean.com/
dida-Lösung als Finalist für FAZ KI-Innovationspreis ausgezeichnet
Am 10. Oktober zeichneten das FAZ-Institut und der KI-Bundesverband herausragende deutsche KI-Lösungen aus.
Der KI-Innovationspreis würdigt Pionierleistungen auf dem Gebiet der Künstlichen Intelligenz. Gesucht wurden Unternehmen, die KI-Technologien einsetzen, um ihr eigenes oder andere Unternehmen, ihre Branche und die Gesellschaft positiv zu beeinflussen.
Die für Mieterengel entwickelte Lösung zur automatischen Analyse von Nebenkostenabrechnungen schaffte es in die Endrunde (Top 3) des Awards.
Die KI-Lösung ermöglicht es Mietern, die Rechtmäßigkeit ihrer jährlichen Nebenkostenabrechnungen schnell und effizient zu überprüfen, indem sie einfach ein Foto hochladen. Seit ihrer Einführung im Jahr 2021 hat die Lösung die Überprüfungszeiten für Anwälte um 60 % reduziert und bereits mehr als 10.000 Kunden bedient.
Mieter erhalten eine kostenlose Bewertung ihrer Nebenkostenabrechnungen und können so fundierte Entscheidungen durch das Angebot einer kosteneffizienten Alternative zu herkömmlichen Rechtsberatungen treffen.
Auf diese Weise demokratisiert Mieterengel den Zugang zu rechtlichen Ressourcen und sorgt dafür, dass sich mehr Mieter selbstbewusst für ihre Rechte einsetzen können.
Wir freuen uns, dass die Jury den innovativen und positiven Charakter unserer KI-Lösung gewürdigt hat.
Zukunft gestalten: Hochschulbeirat der Universität Hohenheim diskutiert Integration von KI in Bildung
Am 16. Oktober 2023 hielt unser Geschäftsführer Philipp Jackmuth einen Impulsvortrag vor dem Hochschulbeirat der wirtschafts- und sozialwissenschaftlichen Fakultät der Universität Hohenheim.
Das Thema des Vortrags waren reale Anwendungsfälle von Künstlicher Intelligenz (KI).
Die Diskussion weitete sich auf die nahtlose Einbindung von KI-Entwicklungen in den Lehrplan aus. Dabei betonten alle Teilnehmer einhellig die bedeutende Rolle der Förderung von kritischem Denken als essentiellen Bestandteil universitärer Bildung.
AI Accelerator Institute Berlin 20223
Am 5. Oktober veranstaltete das AI Accelerator Institute seinen Generative AI and Computer Vision Summit im Waldorf Astoria in Berlin.
Technische Führungskräfte von u.a. Airbus, AstraZeneca, GSK oder Bosch präsentierten Aspekte ihrer neuesten Arbeiten und Erkenntnisse im Zusammenhang mit generativen und Computer-Vision-Modellen.
Da wir regelmäßig an KI-bezogenen Konferenzen teilnehmen und oft selbst unsere Ergebnisse präsentieren, war es wieder einmal ein interessanter Tag. Der Austausch mit anderen Entwicklern über ihre Projekte erlaubt es uns, den Stand der Technik in der Branche in Erfahrung zu bringen und unsere Arbeit und unseren Fortschritt mit ähnlichen Unternehmen zu vergleichen.
Es war gut zu sehen, dass unser Ansatz, aktiv an der KI-Forschung mitzuwirken und unsere internen F&E-Aktivitäten uns in eine gute Position versetzen, künftige Entwicklungen im Bereich der generativen KI und der Computer Vision mitzugestalten.
Virtueller Vortrag zum Thema "KI - Hype vs. echter Wert" im OGS World Café
Am 28. September sprach David Berscheid (virtuell) im OGS World Café in Koblenz zum Thema "KI - Hype vs. echter Mehrwert" und gab Einblicke in text- und bildbasierte KI-Projekte, die in der Produktion einen echten Mehrwert schaffen.
Darüber hinaus stellte er die dida-Perspektive auf aktuelle Entwicklungen dar und erläuterte, was aus unserer Sicht für Unternehmen relevant ist und sein wird, die KI-Lösungen derzeit entwickeln und einsetzen wollen.
Veranstaltet von der OGS GmbH, einem Koblenzer IT-Unternehmen, das sich auf ERP-Software spezialisiert hat, wurde im Rahmen des OGS World Cafés ein Programm mit informativen Vorträgen und Diskussionen u.a. zum Thema KI im ERP-Kontext geboten.
Wir freuen uns, dass wir einen Beitrag zum diesjährigen World Café leisten konnten und freuen uns schon auf das nächste.
Lorenz Richter, CTO von dida, präsentiert auf der ICIAM 2023 in Tokio
こんにちは (Konnichiwa)
Lorenz Richter (Co-Founder & CTO von dida) folgte der Einladung, auf der ICIAM 2023 vom 20. bis 25. August in Tokio zu referieren.
Die Konferenz konzentriert sich auf Themen der industriellen und angewandten Mathematik, bringt Fachleute der Mathematik und verwandter Bereiche zusammen und bietet eine internationale Plattform für aufschlussreiche Diskussionen und Wissensaustausch.
In seinem Vortrag ging Lorenz auf die Feinheiten der diffusionsbasierten generativen Modellierung ein. Der Vortrag stellte eine Verbindung zwischen der generativen Modellierung auf der Grundlage stochastischer Differentialgleichungen (SDEs) und drei grundlegenden Säulen der Mathematik her: stochastische optimale Steuerung, partielle Differentialgleichungen (PDEs) und Pfadraummaße.
Wir freuen uns, dass wir wieder einen Beitrag zur aktuellen Forschung leisten konnten.
Weitere Informationen über den Vortrag finden Sie unter: https://iciam2023.org/registered_data?id=00087#04799
dida besucht GovTech-Meetup in Berlin
Am 31. August fand erneut ein GovTech Campus Community Meetup in Berlin statt.
Diese regelmäßige Veranstaltungsreihe zielt darauf ab, Bund, Länder und Kommunen mit den innovativsten Akteuren der Techszene, der Zivilgesellschaft, der Open-Source-Community und der angewandten Forschung miteinander zu vernetzen.
Ziel ist es, Deutschland zum Vorreiter bei der Entwicklung und Anwendung digitaler Technologien und Lösungen für den öffentlichen Sektor - Government Technology - zu fördern.
Als Mitglied des GovTech Campus hatte dida das Privileg, an dieser Veranstaltung teilzunehmen. Unser Teammitglied Axel Besinger nutzte die Gelegenheit, um sich mit Experten aus der Industrie und dem öffentlichen Sektor auszutauschen.
Das Highlight war der Vortrag von Bernd Schlömer, Staatssekretär für Digitalisierung im Ministerium für Infrastruktur und Digitales des Landes Sachsen-Anhalt, sowie Beauftragter der Landesregierung für die Informationstechnik (CIO), zum Thema: "Plattformfähigkeit - Was bedeutet das in Zukunft für die deutsche Verwaltung?".
Es war spannend zu hören, wie agil Bernd Schlömer in Sachsen eine eigene Verwaltungsplattform aufbaut, die das Ziel hat, bürgerrelevante Produktkomponenten (ob selbst entwickelt oder gekauft) in diese Plattform zu integrieren, um Sachsen und damit auch Deutschland der Digitalisierung einen Schritt näher zu bringen.
Innovationstag mit der Vereinigten Volksbank Raiffeisenbank eG
Erfolgreicher Innovationstag mit der Vereinigten Volksbank Raiffeisenbank eG!
Am vergangenen Freitag durften wir dank Christoph Baier die Vereinigte Volksbank Raiffeisenbank eG (VVRB) im Rahmen ihres Innovationstages zum Thema Künstliche Intelligenz bei smartextract.ai / dida begrüßen.
In einer spannenden Diskussion erkundeten wir die vielfältigen Anwendungsszenarien der Informationsextraktion im Finanzsektor. Die Innovationsfreude und das große Interesse an neuen Technologien unter der Leitung von Herrn Ralf Magerkurth, Vorstandsvorsitzender der Vereinigten Volksbank Raiffeisenbank eG, haben uns tief beeindruckt und sollten als Vorbild für andere dienen.
Das gesamte Team von smartextract.ai und dida sagt DANKE für die Möglichkeit, unsere Ideen und Lösungen zu präsentieren und dieses beeindruckende Team zu treffen.
Wir zum nächsten Innovationstag!
Innovationstag mit der Vereinigten Volksbank Raiffeisenbank eG
Erfolgreicher Innovationstag mit der Vereinigten Volksbank Raiffeisenbank eG!
Am vergangenen Freitag durften wir dank Christoph Baier die Vereinigte Volksbank Raiffeisenbank eG (VVRB) im Rahmen ihres Innovationstages zum Thema Künstliche Intelligenz bei smartextract.ai / dida begrüßen.
In einer spannenden Diskussion erkundeten wir die vielfältigen Anwendungsszenarien der Informationsextraktion im Finanzsektor. Die Innovationsfreude und das große Interesse an neuen Technologien unter der Leitung von Herrn Ralf Magerkurth, Vorstandsvorsitzender der Vereinigten Volksbank Raiffeisenbank eG, haben uns tief beeindruckt und sollten als Vorbild für andere dienen.
Das gesamte Team von smartextract.ai und dida sagt DANKE für die Möglichkeit, unsere Ideen und Lösungen zu präsentieren und dieses beeindruckende Team zu treffen.
Wir zum nächsten Innovationstag!
dida nimmt an Panel bei Google Cloud-Veranstaltung teil
Unser ML Scientist & Project Lead, Jakob Scharlau, nahm an einer großartigen Veranstaltung im Google-Büro in Berlin teil, die vom KI Park e.V., Google und pacemaker® by thyssenkrupp ausgerichtet wurde.
Unter dem Titel "AI Innovation: LLMs, Federated Learning und Slime Mold Algorithmen" ging es um fortschrittliche Methoden der Künstlichen Intelligenz und deren spannende Auswirkungen auf unsere Zukunft.
In zwei Keynote-Sitzungen wurden die Komplexität der Operationalisierung von Large Language Models und die Rolle von #AI bei der Nachfrageprognose unter Verwendung von föderiertem Lernen und Slime-Mold-Algorithmen erörtert.
Insgesamt war es ein aufschlussreicher und spannender Abend, der der Zukunft der KI gewidmet war und wertvolle Einblicke und Möglichkeiten zum Austausch mit Branchenführern bot.
Wir freuen uns, regelmäßig an solchen Veranstaltungen teilzunehmen, von unseren Kollegen zu lernen und einige unserer Erkenntnisse im Austausch anzubieten.
Wir freuen uns, dass das Paper "Improved sampling via learned diffusions" auf dem Workshop "New Frontiers in Learning, Control, and Dynamical Systems", der diese Woche auf der International Conference on Machine Learning (ICML) auf Hawaii stattfindet, angenommen wurde.
In dem Paper wird untersucht, wie das Sampling aus bestimmten Wahrscheinlichkeitsdichten über Diffusionsprozesse angegangen werden kann, bei denen die Drift über neuronale Netze gelernt wird. Es wird die Perspektive der Pfadraum-Maße vorgeschlagen, die es erlaubt, bestehende Methoden wie Schrödinger-Bridges oder „diffusion based generative modeling“ zu verallgemeinern. Diese neue Perspektive erlaubt es, effizientere Loss-Funktionen zu entwerfen, welche zu erheblichen Verbesserungen in numerischen Experimenten führen können.
Wir freuen uns sehr, dass wir unseren Anspruch, Spitzenforschung zu betreiben und Beiträge für die ML-Community zu leisten, fortsetzen können.
dida mit Paper auf der ICML 2023
Wir freuen uns, dass das Paper "Improved sampling via learned diffusions" auf dem Workshop "New Frontiers in Learning, Control, and Dynamical Systems", der diese Woche auf der International Conference on Machine Learning (ICML) auf Hawaii stattfindet, angenommen wurde.
In dem Paper wird untersucht, wie das Sampling aus bestimmten Wahrscheinlichkeitsdichten über Diffusionsprozesse angegangen werden kann, bei denen die Drift über neuronale Netze gelernt wird. Es wird die Perspektive der Pfadraum-Maße vorgeschlagen, die es erlaubt, bestehende Methoden wie Schrödinger-Bridges oder „diffusion based generative modeling“ zu verallgemeinern. Diese neue Perspektive erlaubt es, effizientere Loss-Funktionen zu entwerfen, welche zu erheblichen Verbesserungen in numerischen Experimenten führen können.
Wir freuen uns sehr, dass wir unseren Anspruch, Spitzenforschung zu betreiben und Beiträge für die ML-Community zu leisten, fortsetzen können.
Kickoff des Umwelt-Forschungsprojekts WERTIS-KI
Zusammen mit unseren Partnern Ostfalia Hochschule für Angewandte Wissenschaften, A&B Peine und GE-T hat dida die Arbeit am Forschungsprojekt „Wertstoff-Informations-System mit Künstlicher Intelligenz”, gefördert vom Bundesministerium für Umwelt, Naturschutz, nukleare Sicherheit und Verbraucherschutz, begonnen.
Unser gemeinsames Ziel ist die Entwicklung einer KI-gestützten Handy-App zur Ermittlung des richtigen Entsorgungswegs für zu entsorgende Produkte.
Weitere Informationen finden sich auf der Projekt-Website.
Kickoff des Umwelt-Forschungsprojekts WERTIS-KI
Zusammen mit unseren Partnern Ostfalia Hochschule für Angewandte Wissenschaften, A&B Peine und GE-T hat dida die Arbeit am Forschungsprojekt „Wertstoff-Informations-System mit Künstlicher Intelligenz”, gefördert vom Bundesministerium für Umwelt, Naturschutz, nukleare Sicherheit und Verbraucherschutz, begonnen.
Unser gemeinsames Ziel ist die Entwicklung einer KI-gestützten Handy-App zur Ermittlung des richtigen Entsorgungswegs für zu entsorgende Produkte.
Weitere Informationen finden sich auf der Projekt-Website.
dida hält Vortrag auf der Corporate-Content-Konferenz in München
Am 14. Juni hielt David Berscheid einen Vortrag auf der co³ - Corporate Content Conference - in München.
In seiner Keynote zum Thema "KI erfolgreich einsetzen: Best Practices aus 5 Jahren KI-Projekte" präsentierte er einige dida-Erfahrungen, wie man die richtigen Probleme und Prozesse innerhalb einer Organisation identifiziert, um sie mit KI zu lösen, wie man Lösungen am effektivsten implementiert und welche Rolle die Unternehmenskultur hierbei spielt.
Die Konferenz richtete sich an Marketing- und Kommunikationsexpert*innen, die in ihrem Arbeitsumfeld mit den schnellen technologischen Entwicklungen generativer KI konfrontiert sind. Neben den Best Practices von dida befasste sich die Konferenz auch mit ethischen und rechtlichen Aspekten, die sich aus den Fortschritten generativer KI ergeben.
Weitere spannende Beiträge kamen von Organisationen wie IBM iX, der Technischen Universität München oder der German Entrepreneurship GmbH.
Wir bedanken uns beim corporate-content.com-Team für die Einladung und die tolle Organisation!
KI-Park-Workshop mit Vitesco Technologies
Letzte Woche hatten wir die Gelegenheit, in die Welt der Automobil-Tests einzutauchen und KI-Potenziale mit Leiter*innen der Test-Abteilungen von Vitesco zu diskutieren.
Ziel der vom KI Park organisierten Veranstaltung war es, Unternehmen mit KI-Spezialisten zusammenzubringen, sich gegenseitig vorzustellen und erste Expertenmeinungen zu Anwendungsfällen, potenziellen Herausforderungen und aktuellen KI-Entwicklungen zu geben.
Für uns war es ein hochinteressanter Austausch, da Testumgebungen in der Automobilindustrie vielversprechende Datenmengen für KI-Automatisierungen bieten, gleichzeitig aber auch viel auf dem Spiel steht, wenn es um fehlerhafte Tests geht.
Wir hoffen, dass wir Viteso wertvolle Impulse geben konnten und freuen uns auf deren weitere KI-Entwicklungen sowie auf zukünftige KI-Park-Workshops.
dida auf der hub.berlin-Konferenz 2023
Gestern sind wir der Einladung des Bitkom gefolgt und haben auf der hub.Berlin-Konferenz über das Thema KI Co-Creation zwischen Startups und Corporates gesprochen.
In seinem Vortrag sprach David Berscheid über drei Faktoren, die unserer Erfahrung nach für erfolgreiche Co-Creation-Projekte wichtig sind: Das Abstecken von realistischen Zielen und Erwartungen, die wiederholte Integration von Domänenexpertise und ein starker Fokus auf kulturelle und kommunikative Aspekte zwischen dem Startup und dem Corporate.
Die Konferenz war ein voller Erfolg und konzentrierte sich hauptsächlich auf die Themen Tech und Digitalisierung.
Wir konnten uns auch selbst einige interessante Vorträge ansehen, wie z.B. die Eröffnungs-Keynote von Tim Höttges (CEO der Deutschen Telekom) oder "How Generative AI Redefines Business Decision-Making" von Martin Heinig (Head of New Ventures & Technologies bei SAP).
Für uns als NLP-Spezialisten und tägliche Nutzer von vortrainierten Transformer-Modellen war es außerdem sehr spannend, Jonas Andrulis zuzuhören und mit ihm über Aleph Alpha und seine Pläne zur Entwicklung sicherer und erklärbarer Sprachmodelle für Europa zu sprechen.
Vielen Dank auch an David Kregler für die Moderation unseres Vortrags!
dida veröffentlicht gemeinsam mit Bitkom e.V. Whitepaper zum Thema "Co-Creation and Collaboration – wie Startups & KMU erfolgreich zusammenarbeiten"
Unter der Leitung von Bitkom e.V. haben wir gemeinsam mit anderen Experten*innnen für Machine Learning zusammengetan, um Wege aufzuzeigen, wie KMUs algorithmische Lösungen erfolgreich in ihrem Unternehmen einsetzen können.
Das Whitepaper präsentiert verschiedene Formen der Zusammenarbeit, Potenziale und Herausforderungen sowie Erfolgsfaktoren, die die federführenden Unternehmen als entscheidend erachten.
Außerdem finden Sie 8 Use Cases, in denen wir und andere Unternehmen aus dem Bereich Machine Learning konkrete Beispiele für erfolgreiche Kooperationen mit KMUs in der Vergangenheit vorstellen.
Wir bedanken uns bei Bitkom für die Koordination und Fertigstellung des Whitepapers!
Das Whitepaper finden Sie hier: https://www.bitkom.org/Bitkom/Publikationen/Co-Creation-and-Collaboration
dida beim KI Park Sommer-Event
Am 11. Mai fand das KI Park e.V. Summer Event 2023 im Marienpark (Berlin, Deutschland) statt.
Diese Veranstaltung zielt darauf ab, die Verbindungen innerhalb des Ökosystems der künstlichen Intelligenz in Deutschland und Europa zu fördern. Als Mitglied des KI Park e.V. hatte dida das Privileg, an dieser Veranstaltung teilzunehmen.
Unsere Teammitglieder, Augusto Stoffel und Axel Besinger, nutzten die Gelegenheit, um sich mit Experten aus der Industrie auszutauschen und didas neueste Arbeiten in den Bereichen Natural Language Processing und Computer Vision vorzustellen.
Die Veranstaltung war ein durchschlagender Erfolg mit angesehenen Rednern, Podiumsteilnehmern aus der KI-Forschungsgemeinschaft und Praktikern.
dida-Vortrag auf der Corporate-Content-Conference in München
Am 14. Juni wird David Berscheid einen Vortrag auf der Corporate Content Conference - CO³ - in München halten. Das Thema der Konferenz lautet "AI - The Future of Corporate Content" und richtet sich an Marketingexperten großer Konzerne.
In seinem Vortrag wird David über Best Practices für den erfolgreichen Einsatz von KI sprechen, basierend auf den Erfahrungen aus über 25+ Projekten bei dida.
Wir freuen uns auf die Konferenz, auf viele interessante Vorträge und Panels sowie auf viele neue Kontakte.
Ticket können hier gekauft werden.
Eindrücke der ersten dida Machine-Learning-Konferenz
Letzten Freitag haben wir unsere erste Machine-Learning-Konferenz im B-Part Berlin veranstaltet.
Es war ein sehr interessanter Tag mit Vorträgen, Workshops, einer Podiumsdiskussion und Zeit zum Austauschen und Netzwerken.
Wir hoffen, dass alle Gäste und Redner die Veranstaltung so sehr genossen haben wie wir und freuen uns, dass 150 - 200 Leute gekommen sind, um unser 5-jähriges Jubiläum zu feiern - viel mehr als wir ursprünglich erwartet hatten.
Für diejenigen, die nicht dabei sein konnten, haben wir einige Impressionen der Veranstaltung beigefügt. Wir arbeiten auch schon am Videomaterial, das bald online sein wird.
Vielen Dank an alle, die uns bisher auf unserem Weg unterstützt haben und es weiterhin tun werden!
Wie kann Verwaltung zukunftsfester werden?
Wie kann Verwaltung zukunftsfester werden?
Zu diesem interessanten Thema hat unser Geschäftsführer Philipp Jackmuth eine Veranstaltung am 28.03.2023 besucht, welche von GovMarket und PwC in Berlin organisiert wurde.
Neben Beiträgen direkt aus Kommunen kamen auch der ehemalige Staatssekretär (BMF) Volker Halsch sowie Ekin Deligöz, parlamentarische Staatssekretärin des Familienministeriums (BMFSFJ), zu Wort.
Frau Deligöz betonte, dass durch bessere Bedingungen in der Kinderbetreuung und Pflege ein Arbeitskräftepotential in Millionenhöhe gehoben werden könne (in Vollzeitäquivalten bis zu 1 Million). Andere Referenten stellten die Möglichkeiten einer zunehmenden Digitalisierung und Prozess-Automatisierung in den Fokus, um die Verwaltung zukunftssicher zu machen.
Einig waren sich alle darin, dass nun wirklich gehandelt werden müsse, damit nach der uns bevorstehenden Pensionswelle der kommenden Jahre die Verwaltung überhaupt funktionsfähig bleibt.
dida veröffentlicht Paper über frühzeitige Klassifizierung von Fruchtarten (Deep Learning mit Satellitendaten)
Die dida Autoren Frank Weilandt, Lorenz Richter, Tiago Sanona und Jona Welsch haben zusammen mit unserem Kooperationspartner FERN.Lab des GFZ Potsdam ein Paper zur frühzeitigen Vorhersage von Fruchtarten mittels Satellitendaten veröffentlicht.
Die Vorhersage von Frucharten für Felder ("crop classification") ist ein bekanntes Problem in der Erdbeobachtung und dient als Grundlage für Anwendungen im öffentlichen und privaten Sektor, wie zum Beispiel Ernte/Ertrags-Vorhersagen.
Im Paper wird eine Deep Learning basierte Methode vorgestellt. Diese erlaubt zum einen Vorhersagen zu einem beliebigen Zeitpunkt im Jahr mit einem einzigen Modell zu treffen und zum anderen die einfache Kombination verschiedener Datenquellen (wie zum Beispiel optische und Radar Daten).
Die im Paper beschriebenen Erkenntnisse wurden im Rahmen des Kooperationsprojekts "CropClass" mit dem FERN.Lab gewonnen.
Google Cloud Sunnyvale startup summit
Vom 8. bis 10. Februar durften wir am Google Cloud Sunnyvale startup summit teilnehmen, zu dem wir von Google ins Silicon Valley eingeladen wurden.
Der Workshop bot eine Menge an interessanten Vorträgen von hochrangigen Google-Mitarbeitern, etwa von dem VP Databases, dem VP Business Development and Growth, dem Lead Cloud Quantum Engineer und dem Director of Product Management von Google Brain.
Dabei gab es eine ausgewogene Mischung aus technischen sowie unternehmerischen Themen und lieferte etliche Inspirationen aus den Bereichen Big Data und Machine Learning. Die geschichtsträchtige Umgebung tat ihr Übrigens, um den Workshop einen vollen Erfolg werden zu lassen.
Wir freuen uns auf den weiteren Austausch mit Google und sind froh, in der Google Cloud als Service Partner gelistet zu sein.
dida beim Deutsche Bahn mindbox pitch day
Letzte Woche wurden wir von der Deutschen Bahn eingeladen, um beim mindbox Pitch Day unsere Vision einer digitalen Bahn vorzustellen!
Wir sind stolz darauf, von Moritz Besser und Augusto Stoffel vertreten worden zu sein.
Die Veranstaltung war eine perfekte Plattform für ein Brainstorming zum Thema Digitalisierung bei der Deutschen Bahn und das Kennenlernen interessanter Teams der Klarso GmbH und Scriptomat. Wir sind gespannt auf zukünftige Kooperationen und Projektmöglichkeiten.
dida bei der LEAM.AI Konferenz 2023 im Allianz Forum
Am 24. Januar fand die leam.ai-Konferenz statt.
Es handelt sich um eine Initiative zur Förderung von 'large european AI models' (leam) unter der Leitung des Bundesverbands KI, die darauf abzielt, ein europäisches KI-Ökosystem zu etablieren, das eine wettbewerbsfähige Position in der weltweiten KI-Entwicklung einnimmt.
Da dida Mitglied im Bundesverband KI ist, nutzte unser Geschäftsführer Philipp Jackmuth die Gelegenheit, sich mit anderen Branchenexperten zu treffen und den Status Quo der Initiative zu diskutieren. Es war eine gut organisierte Konferenz mit Referenten und Podiumsteilnehmern aus der KI-Forschungsgemeinschaft, Praktikern sowie Vertretern aus der Politik.
dida ist Co-Veranstalter des KI Park Meetups
Am 19. Januar war dida Co-Gastgeber des "KI Park Meetups".
Unsere ML-Scientists Angela Maennel und Konrad Mundinger moderierten die Diskussionen rund um das Thema Natural Language Processing.
Es war eine tolle Veranstaltung und wir hatten viele interessante Gespräche mit anderen ML-Wissenschaftlern und Ingenieuren. Wir freuen uns schon auf die nächsten Veranstaltungen des KI Parks.
2022
dida-Präsentation beim Open NLP Meetup: "Ethics in Natural Language Processing"
Unser Mitarbeiter Marty hat auf dem Open NLP Meetup einen Vortrag über "Ethics in Natural Language Processing" gehalten!
Wenn Sie sich fragen, welche Auswirkungen große Sprachmodelle auf uns als Gesellschaft haben, schauen Sie sich gerne die Aufzeichnung an: https://youtu.be/7Idjl3OR0FY
Tech Talk im Januar: Kundenbedürfnisse mit NLP besser verstehen
Am 19. Januar um 11 Uhr wird unsere Machine Learning Scientist Angela Maennel erklären, wie mit NLP benutzerfreundliche Schnittstellen gelingen.
Während Kunden es bevorzugen, ihre Bedürfnisse in Form von Freitext auszudrücken, sind für die Verarbeitung oft strukturierte Daten notwendig. Wie man diesen Interessenkonflikt mit Hilfe von NLP auflösen kann, wird Angela in diesem Vortrag erläutern. Der Vortrag basiert auf einem gemeinsamen Projekt mit felmo, um einen solchen Konflikt für deren Website zu lösen.
Sie können sich jetzt kostenlos über folgenden Link anmelden: Hier klicken
dida stellte zwei Papers auf der NeurIPS 2022 vor
Wir freuen uns, mitteilen zu können, dass dida zwei Paper zur diesjährigen Conference on Neural Information Processing Systems (NeurIPS) in New Orleans beigesteuert hat. Die NeurIPS ist eine der größten und wichtigsten Konferenzen zu Innovationen im maschinellen Lernen und verwandten Themen.
Nach einem Beitrag in Form eines akzeptierten Papers im Jahr 2020 (sowie ICML-Papers in den Jahren 2021 und 2022) haben dida-Mitarbeiter in diesem Jahr ein Paper und eine Workshop-Präsentation ("An optimal control perspective on diffusion-based generative modeling") über diffusionsbasierte generative Modelle sowie ein Paper mit Präsentation ("Optimal rates for regularized conditional mean embedding learning") über nichtparametrische Statistik zur NeurIPS beigesteuert. Wir sind stolz darauf, dass es der dida gelungen ist, sich unter international renommierten Forschern von führenden Universitäten und Technologieunternehmen zu behaupten. Von den 9634 eingereichten Beiträgen wurden 2672 (27,7%) angenommen und nur 184 (1,9%) erhielten einen Vortrag.
Der Beitrag "An optimal control perspective on diffusion-based generative modeling" stellt eine Verbindung zwischen stochastischer optimaler Steuerung und diffusionsbasierten generativen Modellen her. Diese Perspektive erlaubt es, Methoden aus der Stuerungstheorie auf generative Modelle zu übertragen und z.B. eine “evidence lower bound” als direkte Folge des bekannten Verifikationssatzes aus der Kontrolltheorie abzuleiten. Darüber hinaus wird eine neuartige diffusionsbasierte Methode zum Sampling aus unnormalisierten Dichten entwickelt - ein Problem, das in der Statistik und in den Naturwissenschaften häufig auftritt.
Die Arbeit "Optimal rates for regularized conditional mean embedding learning" löst zwei offene Probleme im Zusammenhang mit einem häufig verwendeten nichtparametrischen Regressionsmodell: Wir beweisen Konvergenzraten für eine Situation, in der das Modell falsch spezifiziert ist (was bedeutet, dass die Grundwahrheit nicht analytisch durch das Modell dargestellt werden kann) sowie untere Schranken für die Konvergenzraten aller Lernalgorithmen, die das zugrundeliegende allgemeine Problem lösen. Insgesamt liefern diese Ergebnisse Bedingungen, unter denen die Konvergenzgeschwindigkeit des untersuchten Modells von keinem anderen Modell, das das Problem löst, übertroffen werden kann.
Projektstart: dida ist Teil des Forschungsprojekts "KIOptiPack"
Start des KI-Anwendungshub Kunststoffverpackungen für nachhaltige Kreislaufwirtschaft durch Künstliche Intelligenz: Im Rahmen der BMBF-Fördermaßnahme „KI-Anwendungshub Kunststoffverpackungen – nachhaltige Kreislaufwirtschaft durch Künstliche Intelligenz“ werden Methoden der Künstlichen Intelligenz (KI) dazu genutzt, die Nachhaltigkeit von Kunststoffverpackungen zu verbessern – entlang der gesamten Wertschöpfungskette von Design bis zum erneuten Eintreten in den Kreislauf.
dida bei den virtuellen KI-Tagen des ibi-research Instituts
dida ist dieses Jahr auf den Virtuellen KI-Tagen des ibi research Instituts zum Thema "Künstliche Intelligenz im Handel und in der Finanzdienstleistung" vertreten. didas Machine Learning Project Lead Jona Welsch wird in seinem Vortrag "Mit Natural Language Processing (NLP) (un-)strukturierte Dokumente verarbeiten" spannende Erfahrungen aus "real world" KI Projekten im Handel teilen. Eine Teilnahme ist kostenlos möglich, Anmeldungen unter https://ki-tage.de/.
dida nahm teil an der Deep Learning World
Am 5. Oktober stellte unsere Machine Learning Scientist Angela Maennel unser Projekt für felmo vor, in welchem es um natürliche Sprachverarbeitung ging. In der anschließenden Frage-und-Antwort-Runde gab es viele Rückfragen zur Möglichkeit, unsere Lösung auch für andere Probleme anwenden zu können. In diesem Projekt haben wir erneut festgestellt, dass problemspezifische Anpassungen die Vorhersagequalität stark steigern, jedoch kann die generelle Herangehensweise in vielen verschiedenen Kontexten angewendet werden.
dida auf dem Google Cloud Leaders Circle
Diese Woche nahm dida am Leaders Circle im Rahmen der Google Cloud Next Konferenz in München teil. Wir haben uns gefreut, mit vielen interessanten Unternehmen ins Gespräch zu kommen, die ihre internen Prozesse durch effizientes Datenmanagement und Digitalisierung vorantreiben wollen. Immer mehr Unternehmen setzen dabei insbesondere auf Machine Learning, um ihre Geschäftsprozesse zu verbessern oder innovative Tools zu entwickeln. Google bietet hierbei mit ihren flexiblen und leistungsfähigen Cloud-Angeboten eine Plattform, die sich hervorragend eignet, um die damit verbundenen Herausforderungen zu bewerkstelligen, und dida ist stolz, ein offizieller Google-Service-Partner zu sein.
dida bei der Jahrestagung der Gesellschaft für Informatik
Am 27.9.22 stellte unser Machine Learning Project Lead Jona Welsch unser Forschungsprojekt CropClass im Rahmen des Workshops "Geodaten als Open Data für die Künstliche Intelligenz" auf der Jahrestagung der Gesellschaft für Informatik in Hamburg vor. In der anschließenden Diskussionsrunde mit anderen Vortragenden aus Industrie und Forschung gab es einen spannenden Austausch, insbesondere zum Umgang mit freiverfügbaren Satellitendaten aus dem Copernicus Programm der ESA.
dida hält Vortrag bei der Deep Learning World 2022
Wir halten einen Vortrag auf der Deep Learning World Konferenz am 5. Oktober 2022.
In Berlin präsentiert Angela Maennel unseres NLP Projekt für felmo, eine Firma die Tierarzt-Hausbesuche anbietet. Das Ziel des Projektes war aus Kundenanfragen Symptome, Krankheiten und gewünschte Behandlungen heraus zu lesen. Mit dieses Informationen kann felmo dann weiter verarbeiten um interne Prozesse zu verbessern.
Video-Aufzeichnung von unserem ICML-Vortrag
Im Juli nahm dida an der diesjährigen International Conference on Machine Learning (ICML 2022) teil, die - nach zwei Jahren reinen Online-Veranstaltungen - vor Ort in Baltimore, USA, stattfand. Wir haben uns sehr gefreut, unsere Arbeit über robuste SDE-basierte PDE-Löser präsentieren zu dürfen, welche als Konferenz-Paper angenommen wurde. Die Aufzeichnung der dazugehörenden Präsentation gibt es hier.
Es war gut, wieder persönlich mit der Spitzenforschung im Bereich des Machine Learnings in Kontakt zu kommen und sich mit Forschern aus der ganzen Welt auszutauschen. Wir konnten erneut feststellen, dass insbesondere robustes Machine Learning sowie mathematisch rigorose Analysen von Blackbox-Algorithmen weiter an Bedeutung gewinnen - ein Trend, der sich unserer Meinung nach fortsetzen wird und der gut zur dida-Philosophie passt, tief in das Thema Deep Learning einzusteigen.
dida präsentiert auf der Data Natives Konferenz
dida präsentiert auf der Data Natives Konferenz (31. August - 2. September 2022).
Jona Welsch, Machine Learning Project Lead bei dida, präsentiert dort zum Thema "Informationsextraktion - Erfahrungen aus NLP Projekten" didas Learnings aus Kundenprojekten.
Informationsextraktion und das Verarbeiten natürlicher Sprache können in einer Vielzahl von Geschäftsfeldern angewendet werden - von der Digitalisierung und Verarbeitung von Rechnungen und Bestellungen, bis hin zur automatisierten Interpretation von Freitext. Unter anderem geht es hier um mögliche Fallstricke bei der Verarbeitung von PDF-Dokumenten oder die effektive Nutzung von “Graph Neural Networks”.
dida's ASMSpotter unterstützt nun ökologsiche Forschung von der Universität Kent
Der schönste Lohn für die eigene Arbeit ist die Anerkennung, die man erhält von anderen, die die eingenen Arbeitsresultate nutzen. Noch schöner ist es dann, wenn diese Arbeit außerdem auf philantropische Weise die Welt verbessern kann. Daher schätzen wir uns glücklich, dass uns Forscher von der Universität Kent gefragt haben, ob sie unseren ASMSpotter für ihre Regenwaldforschung verwenden können.
Hier eine Beschreibung der Forscher von ihrer Arbeit:
"Handwerklicher Kleinbergbau ist ein wachsender Treiber bei der Abholzung des Amazonas Regenwaldes und eine Hauptursache in Guyana, wo unsere Forschung ihren Schwerpunkt hat. Natürliche und assistierte Regeneration des Waldes sind notwendig, um die Biomasse-Verluste durch solche Nutzung zu ersetzen. Jedoch ist bis jetzt nicht bekannt, wie sich Kleinbergbau im Vergleich zu anderen traditionellen Abholzungsgründen wie Landwirtchaft auf natürliche Regeneration auswirkt.
Manche Minen regenerieren auf natürliche Weise, während andere garnicht regenerieren und auf menschliche Hilfe angewiesen sind. Damit stellen wir uns nun die Frage: unter welchen Bedingungen erholen sich solche Minen wieder? Unsere aktuelle Fragestellung betrifft die Geometrie der bearbeiteten Bereiche: begünstigt lang und dünn oder eher kreisförmig eine Erholung?
Als wir dida's mächtiges ASMSpotter-Werkzeug entdeckten, welches eine quasi Live-Detektion von Minen und ihrer Form und Größe auf Satellitenbildern ermöglicht, wandten wir uns an die Firma mit der Bitte, ob wir den ASMSpotter zur Erstellung von Datensätzen zu den Minen in Guyana benutzen dürden." - Elmontaserbellah Ammar BSc, MSc candidate, Durrell Institute for Conservation and Ecology, University of Kent, Canterbury, UK
dida mit Paper auf der ICML 2022
Wir freuen uns, mitteilen zu können, dass ein Paper, an dem dida mitgewirkt hat, bei der diesjährigen International Conference on Machine Learning (ICML) angenommen wurde. Die ICML ist eine der renommiertesten Konferenzen im Bereich des Machine Learnings, auf der zahlreiche Universitäten, aber auch Unternehmen wie Google, Facebook und DeepMind regelmäßig ihre neuesten Erkenntnisse veröffentlichen. In diesem Jahr wurden dort 1235 von 5630 Einreichungen angenommen, was einer Annahmequote von 21,9% entspricht.
Wir freuen uns sehr, dass wir unsere Ambition, Spitzenforschung zu betreiben und zur Machine-Learning-Community beizutragen, weiter verfolgen können. Nach einem Paper auf der NeurIPS 2020 und einem Paper auf der ICML 2021, das mit einem von fünf „outstanding paper awards“ ausgezeichnet wurde, können wir so unsere Absichten fortsetzen, angewandtes Machine Learning mit innovativer Forschung zu verbinden. Dabei ist es stets die Philosophie des Unternehmens, dass diese beide Welten gegenseitig voneinander profitieren.
Das angenommene Paper ist hier zu finden. Es schlägt robustere und effizientere Algorithmen zum Lösen von linearen Kolmogorov partiellen Differentialgleichungen (PDEs) vor und analysiert diese rigoros. Solche PDEs sind in zahlreichen Anwendungen zu finden, etwa im Finanzwesen, der Physik, dem Reinforcement Learning oder der diffusionsbasierter generativer Modellierung. Bei Fragen zögern Sie bitte nicht, uns zu kontaktieren.
dida nahm teil am ESA Living Planet Symposium
Unser Team von drei dida-Mitarbeitern war auf dem ESA Living Planet Symposium im Mai 2022 in Bonn.
didas ML-Wissenschaftler Frank Weilandt stellte unser Projekt "Frühe Fruchtarterkennung via Multisensor-Fusion und temporaler Aufmerksamkeit (temporal attention)" vor, ein Forschungsprojekt mit dem Geoforschungszentrum GFZ Potsdam. Außerdem trafen wir unsere Fernerkundungskollegen aus aller Welt zu einem spannenden Austausch über neue Entwicklungen in der Erdbeobachtung.
dida präsentiert auf ESA Living Planet Symposium
dida hält im Mai 2022 einen Vortrag auf dem ESA Living Planet Symposium zur Klassifikation von Feldfrüchten aus Satellitendaten.
In Bonn wird unser ML Scientist Frank Weilandt unser Projekt über "Frühe Fruchtarten-Klassifikation mittels Multi-Sensor-Fusion und zeitlicher Attention" vorstellen. Wir entwickeln Software, die aus Satellitendaten auf landwirtschaftlichen Flächen Feldfrüchte erkennt, z.B. Weizen oder Mais. Ein Hauptziel ist die Klassifikation bereits während des Beobachtungsjahres. Diese Arbeit entsteht gemeinsam mit dem GeoForschungsZentrum Potsdam.
dida hält einen Vortrag beim Geokomm Technologiesalon
Am Donnerstag, dem 24. März wird unser ML Berater Moritz Besser einen kurzen Vortrag zu maschinellem Lernen in Industrieprojekten halten. Dies geschieht im Rahmen des Technologiesalons, veranstaltet vom GEOkomm Verband der GeoInformationswirtschaft Berlin-Brandenburg e.V.
Die Teilnahme ist kostenlos und ohne Registrierung möglich, einfach diesem Link folgen.
dida hält Vortrag bei der AMLD in Lausanne
Wir sind eingeladen worden, auf der AMLD in Lausanne, Schweiz, einen Vortrag über das LaserSKI-Projekt zu halten.
Zusammen mit einem Konsortium von Fertigungsunternehmen haben wir an einem Ansatz zur Automatisierung der Fehlererkennung in Diodenlaser-Wafern gearbeitet, bei dem ein FasterRCNN-Objekterkennungsmodell zum Einsatz kommt. Unser Machine Learning Scientist Dr. William Clemens wird im Track "AI and Manufacturing" sprechen und zeigen, wie KI zur Optimierung der Qualitätssicherung in der Fertigung eingesetzt werden kann.
Unser ASMSpotter erscheint in Forbes-Artikel
Anfang des Jahres wurde unser Projekt ASMSpotter von der UNESCO ausgezeichnet. Nun hat das bekannte Forbes-Magazin einen Artikel über die Top 10 Liste der UNESCO veröffentlicht, in dem auch unsere Anwendung beschrieben wird. Der ASMSpotter ermöglicht es, informellen Bergbau in Regenwaldgebieten zu detektieren und wird von uns zusammen mit unseren Partnern bei Levin Sources entwickelt. Aktuell wird unsere Technologie in Guyana angewendet. Weitere Informationen gibt es auf der Projektseite.
Paper zum Lösen parabolischer und elliptischer PDEs mittels Deep Learning
Kürzlich ist ein neues Paper mit dida-Beteiligung auf Arxiv erschienen. In diesem werden Machine-Learning-Methoden zum Lösen von hochdimensionalen parabolischen und elliptischen partiellen Differentialgleichungen (PDEs) untersucht. Insbesondere werden bestehende Algorithmen betrachtet, die auf Residualminimierungen ("physics informed neural networks") oder stochastischen Rückwärtsprozessen ("deep BSDE") basieren sowie eine neue Methode vorgeschlagen, die auf dem neuen „diffusion loss“ fußt. Diese neue Methode kann als eine Interpolation zwischen den beiden bestehenden Methoden interpretiert werden, wobei sie einige numerische Vorteile mit sich bringt. Diese Vorteile können zu effizienteren und genaueren PDE-Approximationen führen und werden daher wahrscheinlich vermehrt Anwendung bei dem Lösen von hochdimensionalen PDEs finden.
dida koorganisiert ein Meetup zum Thema "Klimaanpassung mit Umweltdaten" am 10. Februar
Zusammen mit unseren Freunden und Partnern von Polyteia und K'UP organisieren wir ein Meetup zum Thema "Klimaanpassung - mit Umweltdaten für Unternehmen & Politik" am 10. Februar. Wir würden uns über Ihre Teilnahme freuen, je mehr Perspektiven wir zu dem Thema sammeln, desto breiter wird unser aller Blick werden! (Dieses Event wird in Deutsch stattfinden)
dida nahm teil am All-Hands-Meeting des Bundesministeriums für Bildung und Forschung
Wir haben unseres laufende Projekt LaserSKI am 10. Januar bei dem All-Hands-Meeting von BMBF gesponserten KI-Projekten präsentiert. Es war eine interessante Erfahrung online eine Poster Präsentation zu halten, aber Dank der guten Vorbereitung des Gastgebers, Munich Center for Machine Learning, eine durchaus positive.
dida's ASMSpotter wird von der UNESCO ausgezeichnet
Unter der Schirmherrschaft der UNESCO hat das Internationale Forschungszentrum für Künstliche Intelligenz unser Projekt ASMSpotter, welches wir zusammen mit Levin Sources verfolgen, als eines von 10 hervorragenden Projekten ausgezeichnet. Die Ziele nachhaltiger Entwicklung Nr.12 ("Verantwortlicher Konsum und Produktion") und Nr. 15 ("Leben auf dem Land") rücken mit unserer Arbeit näher. Mehr Informationen über den ASMSpotter gibt es auf unserer Projektseite.
dida präsentiert gemeinsam mit unserem Partner idealo auf der OOP (Object Oriented Programming) Konferenz
Zusammen mit unserem Partner idealo stellt dida eine Machine Learning Lösung zur kontinuierlichen Aktualisierung einer großen Produktdatenbank vor.
Dr. Jan Anderssen (Domain Lead Inventory Business at idealo) und Jona Welsch (Machine Learning Project Lead at dida) zeigen, wie state-of-the-art Deep Learning Methoden (wie z. B. Transformers, BERT) zusammen mit smartem Text Matching angewendet wurden, um relevante Produktinformationen aus Fließtext zu extrahieren.
Weiterhin erklären sie, wie die existierende Datenbank zur automatischen Erstellung eines Trainingsdatensatzes genutzt werden konnte, was die nötige manuelle Arbeit zur Erstellung von Trainingsdaten erheblich verringerte. Das entwickelte Modell erlaubt regelmäßige automatische Updates von idealos Produktdatenbank.
2021
Neues Webinar am 25.11.21: "ML für Remote Sensing: Satellitendaten automatisch analysieren"
Die Verfügbarkeit von Remote Sensing und insbesondere Satellitendaten ist in den letzten Jahren stark gewachsen. Gleichzeitig wird eine manuelle Auswertung dieser Informationen bei steigender Datenmenge immer ineffizienter. Moderne Machine Learning Methoden sind dafür prädestiniert diese Lücke zwischen großen verfügbaren Datenmengen und Expertenwissen zur Analyse zu schließen. Ihre Anwendung im Bereich Remote Sensing ermöglicht es Nutzern Erkenntnisse aus Satellitendaten zu ziehen und unternehmerisch zu nutzen.
In unserem anstehenden Webinar geben Moritz Besser (Machine Learning Consultant) und Jona Welsch (Machine Learning Project Lead) einen Überblick über verfügbare Satellitendaten, Machine Learning Methoden zur deren automatischen Verarbeitung, sowie praktische Anwendungsfälle im Unternehmenskontext.
Melden Sie sich hier an!
AIgent3D research project kicks off
Gemeinsam mit unseren Projektpartnern von Bond3D und Fraunhofer IPT ist dida in ein 2-Jahre Forschungsprojekt gestartet, welches vom Bundesministerium für Bildung und Forschung gefördert wird.
Das Ziel des Projekts ist es die Effizienz in der additiven Fertigung („3D Druck“) zu steigern, indem moderne Machine Learning Algorithmen auf verschiedene Daten angewandt werden, die aus der Schmelzschichtungsproduktion bei Bond3D gesammelt werden. Durch die Verknüpfung von Sensor- und Kameradaten aus den Produktionsmaschinen können reichhaltige Datensets gesammelt werden, die die wertschöpfende Anwendung maschinellen Lernens ermöglichen sollen. So wird dida beispielsweise untersuchen, wie diese Daten genutzt werden können, um Prozessparameter einzustellen oder um die Produktqualität während der Produktion vorherzusagen.
Wir freuen uns sehr auf die Zusammenarbeit mit unseren Projektpartnern in diesem spannenden Forschungsprojekt.
dida partizipierte am landwirtschaftlichen Innovation Day
Am 20. Oktober nahm dida am Lacos Innovation Day teil, einer Landwirtschaftsmesse mit dem Ziel technische Innovatoren in der Branche zusammenzubringen. Als Neulinge in dem Sektor wurden wir sehr freundlich begrüßt und konnten feststellen, dass das potential von KI in dem Bereich deutlich erkannt wird. Wir freuen uns mit unseren neuen Kontakten im Austausch zu bleiben und mit ihnen in Zukunft Machine Learning in die Welt der Lebensmittelproduktion einzuführen.
Hier der Fernsehreport über die Veranstaltung.
Forschungsprojekt KAMI gestartet
Ein sehr spannendes neues Forschungsprojekt im Bereich Landwirtschaft hat begonnen: im Projekt "Künstliche Intelligenz zur Erfassung der Atmung bei Milchkühen" (KAMI) wird mit Hilfe von KI-Technologien das Tierwohl und die Tiergesundheit verbessert, Leistungspotentiale ausgeschöpft und der Medikamenteneinsatz reduziert.
Unter der Schirmherrschaft des ATB Potsdam arbeitet dida mit der Stiftung Universität Hildesheim, dem Lehr- und Versuchsanstalt für Tierzucht und Tierhaltung e.V. und der ITEMA GmbH zusammen.
Weitere Informationen finden Sie hier.
Neues Webinar am 14. Oktober 2021: „Echte Mehrwerte aus ML Projekten - unsere Erfolgsfaktoren“
Die Fortschritte der letzten 10-15 Jahre in Machine-Learning (ML) sind so beeindruckend, dass auch viele Firmen in Deutschland mittlerweile eigene Abteilungen für diesen Bereich aufgebaut haben. Wir durften einige dieser Firmen in den letzten Jahren unterstützen, u.a. bei der Überführung von Proof-of-Concepts (POCs) in den Produktivbetrieb.
In unserem anstehenden Webinar teilen Philipp Jackmuth (Geschäftsführer von dida) und Dr. Petar Tomov (Machine Learning Project Manager) ihre Erfahrungen, welche die entscheidenden Faktoren sind, die erfolgreiche von gescheiterten ML Projekten unterscheiden.
Melden Sie sich hier an.
Im Rampenlicht: ASMSpotter bei den AMLD Africa vorgestellt
Letzte Woche organisierte die École polytechnique fédérale de Lausanne (EPFL), Schweiz, die "Applied Machine Learning Days" (AMLD) Afrika. Im Gegensatz zu den 'normalen' AMLD bei denen letztes Jahr unser Machine Learning Scientist William Clemens einen Vortrag hielt, hatte diese Edition einen Fokus auf den afrikanischen Kontinent und es wurden Problemlösungen sowie Innovatoren von dort vorgestellt.
Moritz Besser, Machine Learning Consultant bei dida, war eingeladen einen Vortrag über unseren ASMSpotter zu halten. Im Projekt geht es darum, informellen handwerklichen Kleinbergbau (artisanal small-scale mining = ASM) mit Hilfe von künstlicher Intelligenz auf Satellitenbildern zu erkennen. Diese wachsende Form des Bergbaus verursacht immer mehr soziale und Umweltprobleme, formalisiert jedoch zu Armutsbekämpfung beitragen kann. Der ASMSpotter kann hierbei ein wichtiges Hilfsmittel darstellen.
dida auf der EuroPython Konferenz 2021
Augusto Stoffel, Machine Learning Scientist bei der dida, hielt einen Vortrag über graphische neuronale Netze und ihre Anwendung für die Informations Extraktion auf der diesjährigen EuroPython.
Die EuroPython ist eine der wichtigsten Konferenzen der Python-Gemeinschaft mit über 1200 Teilnehmern. Sie umfasst eine Sitzung, die den Themen der Datenwissenschaft Themen gewidmet.
Der Vortrag richtete sich an ein überwiegend technisches Publikum und führte in die grundlegenden Ideen rund um maschinelles Lernen mit Graphen. Diese konzeptionelle Sichtweise wird bereichert, Anwendungsfälle aus unserer Erfahrung bei der Entwicklung von ML-Projekten, welche die Fähigkeiten zum Verstehen von Tabellen erfordern, wurden ebenfalls behandelt.
Haben Sie eine potenzielle Anwendung für maschinelles Lernen und möchten Sie die Möglichkeiten mit einem Spezialisten diskutieren? Dann buchen Sie einen ML talk bei uns!
Unser ICML-Artikel wurde als „outstanding paper“ ausgezeichnet
Wir freuen uns, dass das diesjährige ICML-Paper von unserem CTO Lorenz Richter als herausragendes Paper ausgezeichnet wurde. Nur 5 von 1184 akzeptierten und 5513 eingereichten Arbeiten (also etwa 0,1%) erhielten diese ehrenvolle Erwähnung. Die anderen ausgezeichneten Arbeiten können hier eingesehen werden. Wir freuen uns, dass dida weiterhin einen Beitrag zur Spitzenforschung im Bereich des maschinellen Lernens leisten kann, welche ebenso für praktische Anwendungen von großer Bedeutung ist.
Die Arbeit schlägt einen effizienten numerischen Löser für hochdimensionale parabolische partielle Differentialgleichungen vor, die zum Beispiel in den Ingenieurwissenschaften, der Physik und der Finanzwelt relevant sind. Es stützt sich auf das Tensor-Train-Format und stellt diesen Ansatz tiefen neuronalen Netzen als eine alternative Methode gegenüber. Das Paper ist hier und die Videopräsentation hier zu finden.
dida auf der Bühne bei der Machine Learning Week Europe 2021
dida war Teil einer Expertenrunde bei der diesjährigen Machine Learning Week Europe vom 14. - 18.6.21.
Jona Welsch, Machine Learning Project Lead bei dida, präsentierte dort zum Thema "Informationsextraktion - Erfahrungen aus NLP Projekten" didas Einblicke aus Kundenprojekten. Im Anschluss diskutierte er in einem Panel mit anderen Branchenexperten über wichtige Aspekte bei der Entwicklung von "production-ready" Natural Language Processing (NLP) Modellen.
Informationsextraktion und das Verarbeiten natürlicher Sprache können in einer Vielzahl von Geschäftsfeldern angewendet werden - von der Digitalisierung und Verarbeitung von Rechnungen und Bestellungen, bis hin zur automatisierten Interpretation von Freitext. Unter anderem ging es hier um mögliche Fallstricke bei der Verarbeitung von PDF-Dokumenten oder die effektive Nutzung von “Graph Neural Networks”.
Webinar zu neuronalen Sprachmodellen in der Unternehmenspraxis am 29.06.2021
Live-Webinar: "NLP-Trend: Neuronale Sprachmodelle gewinnbringend in die Unternehmenspraxis integrieren"
Neuronale Sprachmodelle, wie z.B. Googles BERT, sind große neuronale Netze, die mit Hilfe großer Textsammlungen trainiert wurden und dadurch semantische und strukturelle Zusammenhänge zwischen den Begriffen einer Sprache gelernt haben.
Neuronale Sprachmodelle sind aktuell die dominierende Entwicklung im NLP-Bereich mit vielen praktischen Anwendungen, von der neuronalen Suche und dem Question Answering bis hin zur Informationsextraktion.
Es stehen eine Reihe frei verfügbarer, vortrainierter Modelle zur Verfügung. Um sie in der eigenen Unternehmenspraxis gewinnbringend einzusetzen, müssen einige Dinge berücksichtigt werden. Welche genau und wie das geht, zeigen wir in unserem Webinar nach einem Überblick der Funktionsweise von neuronalen Sprachmodellen und Beispielen für ihre Anwendungsmöglichkeiten.
Wie funktionieren neuronale Sprachmodelle?
Einsatzbeispiele aus den Bereichen Suche und Question Answering
Wie kann ein neuronales Sprachmodell für mein Unternehmen/Anwendungsgebiet optimiert werden?
Wie klappt die Integration mit meinen Daten und Anwendungen?
dida beim GEOkomm Technologiebrunch
Beim virtuellen Technologiebrunch des Verbands der Geoinformationswirtschaft in Berlin/Brandenburg GEOkomm e. V. am 4. Juni 2021 waren Jona Welsch, Machine Learning Project Lead und Robert Heesen, Director of Product eingeladen dida’s Erfahrungen unter dem Titel “Informationsextraktion mit KI - Expertentipps zur erfolgreichen Umsetzung” zu teilen.
Informationsextraktion und das Verarbeiten natürlicher Sprache (Natural Language Processing, NLP) können in einer Vielzahl von Geschäftsfeldern angewendet werden - von der Digitalisierung und Verarbeitung von Rechnungen und Bestellungen, bis hin zur automatisierten Interpretation von Freitext. Unter anderem ging es hier um mögliche Fallstricke bei der Verarbeitung von PDF-Dokumenten oder die effektive Nutzung von “Graph Neural Networks”.
dida mit Paper und langem Vortrag bei diesjähriger ICML
Wir freuen uns mitteilen zu können, dass dida mit einem Paper und einem langem Vortrag zur diesjährigen International Conference on Machine Learning (ICML) beitragen wird, einer der weltweit angesehensten Konferenzen zur Künstlichen Intelligenz. Von 5513 Einreichungen sind nur 166 (d.h. etwa 3%) mit dieser Möglichkeit ausgezeichnet worden. Unser Paper schlägt einen effizienten numerischen Löser für hochdimensionale parabolische partielle Differentialgleichungen vor, die z.B. im Ingenieurwesen, der Physik und in der Finanzwelt relevant sind. Er basiert auf dem Tensor-Train-Format und kontrastiert diesen Ansatz mit tiefen neuronalen Netzen als eine alternative Methode. Eine Preprint-Version ist hier zu finden.
Nach einem Paper auf der letztjährigen NeurIPS-Konferenz, zu dem man hier eine kurze Videopräsentation finden kann, freuen wir uns, dass wir unser Bestreben, praktisches Machine Learning mit Spitzenforschung zu verbinden, weiter vorantreiben können. Es ist die Philosophie unseres Unternehmens, dass diese beide Welten stark voneinander profitieren können.
Bei Fragen zu den Papers oder zu anderen Themen zögern Sie bitte nicht, uns zu kontaktieren.
dida präsentiert "PreTrainAppEO" auf dem 3. Symposium zur angewandten Satellitenerdbeobachtung
Ewelina Fiebig und Konrad Schultka, Machine Learning Scientists bei dida, werden auf dem vom DLR organisierten 3. Symposium zur angewandten Satellitenerdbeobachtung „Neue Perspektiven der Erdbeobachtung“ eines unserer neuen Projekte - "PreTrainAppEO" - vorstellen.
Das Ziel des Projekts ist die Entwicklung einer neuen Methodik, die den Ansatz vortrainierter KI-Modelle nutzt, um eine Generalisierbarkeit auf verschiedene Standardanwendungen in der Erdbeobachtung und Fernerkundung zu erreichen. Das Projekt wird in Zusammenarbeit mit dem Lehrstuhl für Methodik der Fernerkundung der TU München durchgeführt.
Der Vortrag findet am 16. Juni um 13:10 Uhr in Session 7: KI - Neue Verfahren statt.
„PreTrainAppEO“ - ein gemeinsames BMWI Forschungsprojekt von dida und TU München LMF
Seit Mai 2021 arbeitet dida zusammen mit dem Lehrstuhl für Methodik der Fernerkundung (LMF) der Technischen Universität München (TUM) an einem vom Bundesministerium für Wirtschaft und Energie (BMWI) geförderten Projekt „PreTrainAppEO“. Das Projekt wird mit einem Betrag von 199 Tsd. EUR gefördert und ist auf den Zeitraum von zwei Jahren ausgelegt. Die Bezeichnung „PreTrainAppEO“ steht für Pre-Training Applicability in Earth Observation (Anwendbarkeit von vortrainierten KI-Modellen in der Erdbeobachtung).
Erdbeobachtung und Fernerkundung sind aufgrund des technologischen Fortschritts im Bereich Raumfahrt und Aufnahmetechnik sowie Sensorik zu einem wichtigen Bestandteil von beispielsweise Transport- und Versorgungssektoren sowie Geowissenschaften und Meteorologie geworden. Gleichzeitig gewinnt der Einsatz von Methoden des maschinellen Lernens (ML) bei der Analyse und Auswertung von Bild- und Sensordaten zunehmend an Bedeutung. Dies wird auch durch einige unserer Projekte sehr deutlich:
ASMSpotter, CropClass, Schätzung der verfügbaren Fläche für Photovoltaik-Anlagen, 4D Urban Insights, DWD Clouds.
Obwohl sich ML-Ansätze durch eine sehr hohe Leistungsfähigkeit und Genauigkeit auszeichnen, ist ihre Performanz auf den spezifischen Anwendungsfall und Trainingsdatensatz beschränkt. Dies hat zur Folge, dass der Trainingsaufwand und die Beschaffung großer Datensätze für jeden neuen Anwendungsfall wiederholt werden muss, was zu hohen Kosten in der Anwendungsentwicklung führt. Leider - im Gegensatz zu bereits etablierten vortrainierten KI-Modellen wie ResNet oder VGG, die auf dem generischen Bilddatensatz ImageNet basieren - sind derzeit keine vortrainierten KI-Modelle für Satellitendaten oder Erdbeobachtungsanwendungen vorhanden.
Umso mehr freuen wir uns, ein Teil von "PreTrainAppEO" zu sein. Das Ziel dieses Projektes ist es, den Einsatz von KI im Bereich der Erdbeobachtung und Fernerkundung attraktiver und effizienter zu machen, indem eine Methodik entwickelt wird, die den Ansatz vortrainierter KI-Modelle nutzt, um eine Generalisierbarkeit auf verschiedene Standardanwendungen in diesem Bereich zu erreichen.
dida auf der Bühne des DLR Copernicus-Forums 2021
dida ist gleich drei Mal auf dem DLR Copernicus Forum, das dieses Jahr vom 23.-24. März virtuell stattfindet, vertreten. Unser Managing Director Philipp Jackmuth wird am 23. März um 14.40 Uhr an der Podiumsdiskussion „Künstliche Intelligenz – Schlüssel zum Copernicus Datenschatz?" gemeinsam mit Vertretern des DLR (Deutsches Zentrum für Luft- und Raumfahrt), des DFKI (Deutsches Forschungszentrums für Künstliche Intelligenz), der ECMWF (European Centre for Medium-Range Weather Forecasts) und dem Bundesministerium für Verkehr und Digitale Infrastruktur teilnehmen.
Außerdem präsentiert Moritz Besser, Machine Learning Consultant bei dida, am 24. März ab 14.30 Uhr das Projekt "ASMSpotter - Identifizierung von Kleinbergbau basierend auf Satellitenbildern" in der vom BGR ausgerichteten Fachsession "Energie und Rohstoffe". Außerdem stehen Robert Heesen, Director Product, und Moritz Besser für Rückfragen in einem virtuellen Stand bereit.
Wir freuen uns auf das diesjährige Copernicus Forum und darüber, dass dida seine Projekte einem fachkundigen Fernerkundungspublikum vorstellen kann.
dida präsentiert das "CropClass" Projekt auf dem agraSpace Netzwerk Event
Auf dem virtuellen Netzwerktreffen des ZIM Netzwerks "agrASpace" mit dem Titel "Künstliche Intelligenz in der Landwirtschaft" am 4. März 2021 haben Robert Heesen, Director Product und Jona Welsch, Machine Learning Scientist bei dida das Projekt "CropClass" vorgestellt. Das Projekt mit dem Titel " CropClass- Unterjährige Fruchtarten Klassifikation mit Fernerkundungsdaten und Machine Learning" hat zum Ziel, die Fruchtarten auf landwirtschaftlichen Flächen möglichst frühzeitig im Jahr auf Basis von öffentlich zugänglichen Satellitendaten wie Sentinel-1 und Sentinel-2 Daten zuverlässig zu bestimmen und über eine Nutzeroberfläche zugänglich zu machen. Das Projekt wird gemeinsam mit dem fern.lab, der Fernerkundungsabteilung des GFZ Potsdam durchgeführt und läuft noch bis Juni 2022.
Potenzielle Anwender der Software sind Landwirtschaftsministerien zur Kontrolle von EU-Agrarsubventionen, Verkäufer von Saatgut und Dünge- und Spritzmitteln sowie Händler von Agrargütern. Weitere Informationen finden Sie in der Präsentation.
dida in KI-Startup-Landschaft 2021 von appliedAI vertreten
dida ist erneut im Rahmen der "AI Startup Landscape 2021" der appliedAI Initiative als eines von 278 vielversprechenden Startups mit KI-Fokus in der Kategorie "Professional, scientific and technical activities" aufgeführt. Dafür wurde aus öffentlichen Quellen wie Crunchbase und LinkedIn eine "longlist" von KI-Startups erstellt. Die Auswahl der Startups erfolgte in persönlichen Interviews durch das appliedAI Team, um die Ausrichtung auf Künstliche Intelligenz zu überprüfen. Außerdem wurden die Startups von einer Jury bestehend aus bekannten KI-Firmen und -Investoren wie Google, NVIDIA, HV Ventures und Lakestar evaluiert. Die Kategorisierung erfolgte auf Basis von Shivon Zilis’ "landscape of machine intelligence".
Wir freuen uns auch in diesem Jahr in der AI Startup Landscape unserer sehr geschätzten Kollegen von appliedAI vertreten zu sein.
dida und RWTH Aachen MRE starten gemeinsames BMBF Forschungsprojekt "AuBeSa"
Am 4. Januar 2021 hat dida die Arbeit an dem Forschungsprojekt "AuBeSa" im Rahmen des BMBF (Bundesministerium für Bildung und Forschung) Förderprogramms "KMU-innovativ" mit einem Projektvolumen von insgesamt 800 Tsd. EUR aufgenommen. "AuBeSa" ist das Akronym für "Automatische Erkennung, Vermessung und mineralogische Klassifizierung von Bergehalden und -Teichen mit Satellitenfernerkundung".
Bergehalden sind Abfälle aus dem Bergbau, die bei der Förderung von Rohstoffen und Erzen anfallen und meist nahe des Tagebaus angehäuft werden. Je nach Prozessierung lagern, insbesondere in älteren Bergehalden verlassener Tagebaue, wertvolle Rohstoffe, für die es zu damaliger Zeit keine Verwendung gab. Diese Bergehalden geraten heute aufgrund hoher Explorationskosten neuer wirtschaftlicher (primärer) Lagerstätten und verbesserter Prozessierungsmethoden in den Fokus von Bergbau-Unternehmen.
Wird in einer Bergehalde förderfähiges Material von Explorationsunternehmen gefunden, so werden sogenannte sekundäre Lagerstätten errichtet und neue Tagebaue zur Förderung der Rohstoffe errichtet.
Die Schwierigkeit in der Exploration sekundärer Lagerstätten liegt allerdings darin, die wirtschaftliche Nutzbarkeit ohne Vor-Ort Studie abschätzen zu können. Da hohe Kosten mit einer Vor-Ort Studie verbunden sind, kann die automatische Analyse von Fernerkundungsdaten zu der Bewertung der wirtschaftlichen Nutzbarkeit beitragen.
In "AuBeSa" wird ein KI-Algorithmus trainiert, der basierend auf einer Datenbank bekannter Standorte von Bergehalden, diese automatisch lokalisieren kann. Um die wirtschaftliche Nutzbarkeit abzuschätzen, wird zudem das Volumen der Bergehalden errechnet sowie die mineralogische Zusammensetzung auf Basis von Satellitendaten bestimmt. Neben der KI-Expertise von dida ist daher geologisches Expertenwissen zur Umsetzung des Projektes notwendig. Wir sind froh, mit dem "Institute of Mineral Resources Engineering (MRE)" der RWTH Aachen einen starken Partner an unserer Seite zu haben und freuen uns, die erfolgreiche Zusammenarbeit aus dem ASMSpotter Projekt fortsetzen zu können.
2020
Beginn der führenden KI-Konferenz NeurIPS - Auch dida mit einem akzeptierten Paper
Am kommenden Sonntag, dem 6. Dezember, beginnt die in diesem Jahr virtuell stattfindende, international führende KI-Fachkonferenz NeurIPS. Insgesamt wurden in diesem Jahr 9.450 Fachbeiträge eingereicht, wovon 1.900 Beiträge akzeptiert wurden, eine Steigerung von knapp 200% im Vergleich zu 2017. Auch in diesem Jahr dominieren nach einer Analyse der Firma Criteo die amerikanischen Technologie-Unternehmen und Universitäten die Liste der Konferenzbeiträge.
Nach Ländern betrachtet führen die USA mit weitem Abstand die Liste der forschungsstärksten KI-Länder mit mehr als 1.186 akzeptierten Beiträgen an, gefolgt von China (259) und Großbritannien (205). Deutschland folgt auf Platz 6 (70), kurz hinter der Schweiz (90). Insgesamt stellt Europa inklusive Großbritannien und der Schweiz 520 Fachbeiträge.
Nach Institutionen betrachtet zeigt sich, dass neben den US Universitäten wie Stanford (104), MIT (100) oder UC Berkeley (89), insbesondere die amerikanischen Technologie-Unternehmen und deren Forschungsabteilungen in der KI-Forschung führend sind. Allen voran Google. Inklusive ihrer in London ansässigen Tochter DeepMind kommt das US Unternehmen auf 237 Beiträge, gefolgt von Microsoft (95) und Facebook (58).
Bei der Analyse der deutschen Fachbeiträge durch dida finden sich allerdings auch einige Hoffnungsschimmer für den KI-Standort Deutschland. Denn auch Deutschland kann KI-Spitzenforschung vorweisen. Gemessen an der Anzahl der akzeptierten Fachbeiträge ist das Max Planck Institut für Intelligente Systeme (13) mit Sitz in Tübingen führend, vor der TU München (10), der Universität Tübingen (8) und dem Max Planck Institut für Informatik (8) mit Sitz in Saarbrücken. Aber auch Unternehmen wie die Robert Bosch GmbH (6) betreiben KI-Spitzenforschung.
Auf der Landkarte betrachtet ist der Süden bzw. Südwesten Deutschlands führend in der KI Forschung, mit Schwerpunkten in der Universitätsstadt Tübingen (22), München (13) und Saarbrücken (12).
Auch auf der Veranstaltung selbst ist Deutschland gut vertreten. Neben Prof. Dr. Ulrike von Luxburg (Universität Tübingen) im Vorstand ist auch Prof. Dr. Bernhard Schölkopf (Max Planck Institut für Intelligente Systeme, Tübingen) im Beirat der NeurIPS Organisation vertreten. Als Sponsoren tritt neben Zalando in diesem Jahr auch das Bundesministerium für Bildung und Forschung (BMBF) in Erscheinung.
Auch dida kann dieses Jahr einen Fachbeitrag auf der NeurIPS vorweisen. So wurde ein Artikel akzeptiert, an der Gründer von dida, Lorenz Richter, mitgewirkt hat. Lorenz Richter: “Wir bei dida verstehen uns als Unternehmen an der Schnittstelle zwischen Forschung und Anwendung. Aus diesem Grund suchen wir bei dida Mathematiker und Physiker, die über langjährige Erfahrung in der Forschung verfügen. Somit wollen wir dazu beitragen, dass KI-Forscher nicht ins Ausland abwandern und zeitgleich die Ergebnisse ihrer Forschung in die Anwendung bringen können. Zeitgleich möchten wir unseren Mitarbeitern ermöglichen, weiterhin KI-Spitzenforschung zu betreiben, um die Entwicklung von KI in Deutschland weiter voranzutreiben und sich nicht nur auf die Entwicklung neuer KI-Methoden durch die amerikanischen Technologie-Unternehmen und Universitäten zu verlassen.”
Sie finden Lorenz Paper hier.
dida in die European AI Landscape aufgenommen
Bei den "Sweden Innovation Days" am 17. November wurde die europäische Landschaft der KI-Startups vorgestellt, auf der mehr als 500 Startups aus Schweden, Frankreich und Deutschland gelistet sind. Unterstützt wurde die Initiative durch das German Entrepreneurship und das German Accelerator-Programm sowie durch Vinnova, Schwedens Innovationsagentur - appliedAI (Deutschland), Ignite Sweden, AI Sweden, die RISE Research Institutes of Sweden (Schweden) sowie Hub France IA (Frankreich). Der Zweck der Europäischen Landschaft von KI-Startups ist es, Unternehmen, die an der Implementierung von KI-Lösungen interessiert sind, eine Übersicht zu geben, welche Unternehmen in ihrem Anwendungsgebiet erfahrene KI Dienstleister sein könnten.
Alle Startups wurden getestet und befragt, um ihren Fokus auf KI-Technologien zu untersuchen und sie in eine von 25 Kategorien einzuordnen. Als Teil der Landschaft wird dida auch mit dem Abzeichen "Trusted AI Startup" ausgezeichnet.
Wir fühlen uns geehrt, Teil der Landschaft und des Clubs mit anderen KI-Startups zu sein, und hoffen, dass sich weitere europäische KI-Initiativen den Bemühungen anschließen, eine gesamteuropäische Landkarte der KI-Startups zu erstellen und die Transparenz auf dem KI-Markt zu verbessern. Sie finden dida in der europäischen KI-Landschaft hier: https://www.ai-startups-europe.eu/
NLP Webinar am 24. November: Recurrent Neural Networks
Anwendungen der Natürlichen Sprachverarbeitung wie die semantische Suche (Google), die automatisierte Textübersetzung (z.B. DeepL) oder die Textklassifikation (z.B. E-Mail-Spamfilter) sind aus unserem Alltag nicht mehr wegzudenken. In vielen Bereichen des NLP beruhen entscheidende Fortschritte auf der Entwicklung und Erforschung einer Klasse von künstlichen neuronalen Netzen, die besonders gut an die sequentielle Struktur natürlicher Sprachen angepasst sind: rekurrente neuronale Netze, kurz: RNNs. Das Webinar gibt eine Einführung in die Funktionsweise von RNNs und veranschaulicht deren Einsatz an einem Beispielprojekt aus dem Bereich der Legal Tech. Es schließt mit einem Ausblick auf die zukünftige Bedeutung von RNNs inmitten alternativer Ansätze wie BERT und Convolutional Neural Networks. Das Webinar findet am 24. November 2020 statt.
Hier können Sie sich anmdelden
Webinar am 27. Oktober: Automatisierte Beantwortung von Fragen mit neuronalen Netzen: BERT
In diesem Webinar stellen wir eine auf dem BERT Modell basierende Methode zur automatisierten Beantwortung von Fragen vor. Die potentiellen Anwendungen sind vielfältig: die Ideen dieses Ansatzes können zum Beispiel in Chatbots, Informationsextraktion aus Texten und Q&A Sektionen von Websites verwendet werden. Als konkretes Beispiel gehen wir auf die Extraktion von Information aus biomedizinischen Forschungsarbeiten am Beispiel des offenen CORD-19 Datensatzes zur COVID-19 Forschung ein.
Mehr Informationen hier.
"AI for good" - dida gewinnt internationale Auszeichnung "Microsoft AI for Earth" für die Regulierung des illegalen Goldabbaus
dida hat den mit 100.000 USD dotierten, international renommierten “Microsoft AI for Earth” Preis gewonnen (Link). Bei dem Wettbewerb, bei dem Lösungen zur Regulierung von informellem Kleinbergbau von der amerikanischen Organisation Conservation X Labs prämiert wurden, setzte sich dida mit seiner Software ASMSpotter (englisch: artisanal mining (ASM)) gegen mehr als 100 Unternehmen aus 40 verschiedenen Nationen durch.
Informeller Kleinbergbau stellt die Lebensgrundlage für mehr als 100 Millionen Menschen dar und ist von großer Bedeutung für die weltweite Rohstoffversorgung. Aufgrund fehlender Möglichkeiten zur großflächigen Beobachtung und effektiver Kontrollen geht informeller Bergbau allerdings häufig mit großen Schäden für Natur und Bevölkerung einher. Genau dort setzt ASMSpotter an.
ASMSpotter analysiert mithilfe von KI-Algorithmen Satellitenbilder des europäischen Satelliten Sentinel-2 der Europäischen Raumfahrtagentur ESA aus dem Copernicus Programm und von Planet, einem kommerziellen Anbieter von Satellitenbildern, erkennt automatisch informelle Bergbaustätten und macht Veränderungen zum letzten Satellitenbild sichtbar. Die Software wurde im Rahmen einer Förderung durch die Europäische Raumfahrtagentur entwickelt.
Im Laufe des Projektes wurde mit Levin Sources ein Partner aus Großbritannien gewonnen, der Regierungen bei der Umsetzung von Programmen zur Formalisierung von Kleinbergbau unterstützt, so dass die Lösung nicht missbräuchlich genutzt und effektiv implementiert wird.
Robert Heesen, Director Product bei dida: “Wir fühlen uns sehr geehrt, von einer so hervorragend besetzten Jury und von Microsoft ausgezeichnet zu werden. Mit ASMSpotter wollen wir zeigen, dass KI einen positiven Beitrag zu den großen Problemen der Menschheit leisten kann. ASMSpotter hilft die Umweltzerstörung zu minimieren und die Arbeitsbedingungen der lokalen Bevölkerung zu verbessern. Bisher mangelt es lokalen Behörden an Lösungen zur automatischen, großflächigen Überwachung von Bergbauaktivitäten. Regierungen, die unsere Lösung nutzen, können den Sektor deutlich besser regulieren, weil Sie frühzeitig Veränderungen erkennen und handeln können. Mit unserem Partner Levin Sources sorgen wir zeitgleich dafür, dass die Lösung nicht missbraucht wird und ihr gesamtes Potenzial entfalten kann.”
Die nächsten Schritte sind laut Heesen die Einführung der Lösung in Ghana, gemeinsam mit dem Bergbauministerium in Ghana und dem Partner Levin Sources. Außerdem möchte dida die Lösung auch für andere Rohstoffe wie Cobalt oder Baumaterialien wie Kies verfügbar machen. Heesen: “Technisch gesehen ist die KI-Lösung gut skalierbar auf andere Länder und Rohstoffe. Jetzt suchen wir nach Partnern, die mit uns dafür sorgen, dass die Lösung verantwortlich und effektiv genutzt wird.”
Über dida:
dida ist ein KI-Unternehmen mit einer Spezialisierung auf der Entwicklung von Computer Vision Anwendungen, d.h. der automatischen Analyse von Bilddateien. dida hat seinen Sitz in Berlin und beschäftigt zwanzig Mitarbeiter, wovon fünfzehn in der Entwicklung von KI-Anwendungen tätig sind.
Ansprechpartner:
Robert Heesen
robert.heesen@dida.do
+49 151 65266677
Webinar: BERT für die Semantische Suche am 24. September 2020
Webinar: BERT für die Semantische Suche | 24. September 11:00 - 12:00 Uhr (CEST)
Im Webinar werden unter anderem folgende Fragen beantwortet:
Was ist Semantische Suche und welche Probleme kann ich damit lösen?
Was ist BERT und wie kann ich es für Semantische Suche einsetzen? (Inklusive eines Beispiels aus der Praxis)
Was für Daten benötige ich dafür?
Hier können Sie sich für das Seminar anmelden.
dida und das GFZ Potsdam erhalten Projektzuschlag
Gemeinsam mit dem GFZ Potsdam, dem nationalen Forschungszentrum für Geowissenschaften, hat dida den Zuschlag für ein Projekt zur Erkennung von Ackerfrüchten
vom Bundeswirtschaftsministerium erhalten. Das Ziel des Projektes ist die unterjährige und frühzeitige Klassifikation der Fruchtart auf landwirtschaftlich
genutzten Parzellen auf Basis von Satellitendaten aus dem europäischen Satelliten-System Sentinel mittels Machine Learning Algorithmen.
Eine möglichst frühzeitige Klassifikation der Fruchtart und die Überführung in einen Online Service sollen diese Daten auch für zusätzliche Anwendungen nutzbar
machen, zum Beispiel zur Preisfindung in Warenterminbörsen oder zur Ableitung von Ernteprognosen.
Wir freuen uns auf die Zusammenarbeit mit dem GFZ Potsdam und ein spannendes Projekt über die nächsten zwei Jahre!
Nvidia Inception Summit: Neue Titan RTX für dida
Im Februar 2020 wurde dida auserwählt ASMSpotter auf dem Nvidia Inception Summit / GTC (siehe Presentation Gallery > Computer Vision / Intelligent Video Analytics / Video & Image Processing) vorzustellen. ASMSpotter ist ein ESA-Projekt, welches dida gemeinsam mit dem Institute of Mineral Resources Engineering (MRE) der RWTH Aachen entwickelt hat. Das Ziel des Projekts ist es, automatisch Kleinbergbau im Amazonas-Regenwald in Surinam aufzuspüren.
dida wurde zusammen mit sieben anderen Unternehmen eingeladen ihre Projekte vorzustellen. Unsere Präsentation wurde mit einer Titan RTX Grafikkarte von Nvidia belohnt. Wir sind sehr glücklich, dass wir die GPU heute in Empfang nehmen konnten und haben natürlich sofort unsere on premise-Maschine aufgerüstet. Vielen Dank an Alexander Martynau und Nvidia!
NLP Webinar 2/3: Labeling Tools
-- Vielen Dank für die zahlreiche Teilnahme an den ersten Webinaren! --
In einer Reihe von 3 Webinaren erläutert dida's Ewelina Fiebig im Detail die wichtigsten Schritte, die zur erfolgreichen Umsetzung eines NLP-Projekts führen.
Webinar 1: Texterkennung (OCR) | 23. April von 11-12 Uhr (CEST)
Link zur Aufzeichnung.
Webinar 2: NLP Labeling Tools | 28. Mai von 11-12 Uhr (CEST)
Link zur Aufzeichnung.
In diesem Beitrag werden wir uns mit dem Thema der Auswahl eines geeigneten Labeling-Tools befassen. Dabei werden wir auf die folgenden Aspekte eingehen:
Was bedeutet Labeling und was kann gelabelt werden?
Warum ist Labeling überhaupt nötig?
Herausforderungen bei der Wahl eines geeigneten Tools.
Unsere Tipps, was vor und bei der Auswahl eines Tools wichtig zu beachten ist.
Kurze Präsentation ausgewählter Tools.
Andere erwähnenswerte Tools.
Webinar 3: NLP Case Study - Entity Recognition in Documents | 18. Juni von 11-12 Uhr (CEST)
dida auf der Deep Learning World am 12. Mai
dida's Dr. Petar Tomov und Philipp Jackmuth waren eingeladen am 12. Mai auf der diesjährigen Deep Learning World (DLW) einen Vortrag zu halten. Die DLW ist eine Konferenz mit Schwerpunkt im Bereich der kommerziellen Nutzung von Deep Learning.
Petar und Philipp berichteten über Erfahrungen sowie konkreten Tipps und Tricks aus einem kürzlich für die Europäische Weltraumorganisation (ESA) durchgeführten Projekt. Ziel des Projekts ist es, aus Satellitendaten illegale Minen in Entwicklungsländern aufzuspüren. Wir möchten uns besonders bei den Zuhörern für das große Interesse an dem Thema und die vielen engagierten Fragen bedanken. Wir freuen uns schon auf die - hoffentlich wieder physisch stattfindende - Konferenz im nächsten Jahr.
Projektabschluss des ESA Projektes "ASMSpotter"
dida hat das ESA Projekt "ASMSpotter" erfolgreich abgeschlossen. Bei dem Projekt wurde untersucht, ob es möglich ist, dass Kleinstbergbau
für Gold auf Satellitenbildern mit Machine Learning automatisiert identifiziert werden können.
In der Umsetzung hat dida sowohl mit PlanetScope und Sentinel-2 Satellitenbildern gearbeitet und zusammen mit dem Institute of Mineral Resources
Engineering (MRE) von der RWTH Aachen einen Trainingsdatensatz von über 10.000 annotierten Bildern zum Modelltraining generiert. Für das Testgebiet im
Nordosten Surinams konnte eine Klassifizierungsgenauigkeit von über 80% erreicht werden. Außerdem konnte nachgewiesen werden, dass das ML-Modell
sehr gut auf Gebiete ähnlicher Topografie angewendet werden kann.
Aufgrund der positiven Begutachtung der ESA wird das Projekt in Zukunft mit einem Partner fortgesetzt. Dabei wird die Software in einem
Kleinstbergbau Projekt in Ghana implementiert, um illegale Bergbauaktivitäten frühzeitig zu identifizieren.
Wir bedanken uns für die vertrauensvolle Zusammenarbeit mit der ESA und dem MRE der RWTH Aachen!
NLP Webinar 1/3: Optical Character Recognition (OCR)
-- Vielen Dank für die zahlreiche Teilnahme an den ersten Webinaren! --
In einer Reihe von 3 Webinaren erläutert Ewelina Fiebig von dida im Detail die wichtigsten Schritte, die zur erfolgreichen Umsetzung eines NLP-Projekts führen.
**Webinar 1: Texterkennung (OCR) | 23. April von 11-12 Uhr (CEST)**
In diesem Beitrag befassen wir uns mit dem Thema der Texterkennung und stellen Ihnen vor:
Was bedeutet OCR?
Anwendungsbeispiel
Warum wird OCR benötigt?
Welche OCR-Tools gibt es?
Wie werden diese Tools bedient?
Welches Tool passt auf welche Problemstellung?
Hier finden Sie die Aufzeichnung in deutscher Sprache.
Webinar 2: NLP Labeling Tools | 28. Mai von 11-12 Uhr (CEST)
Wir werden auf die folgenden Aspekte eingehen:
Was bedeutet Labeling und was kann gelabelt werden?
Warum ist Labeling überhaupt nötig?
Herausforderungen bei der Wahl eines geeigneten Tools.
Unsere Tipps, was vor und bei der Auswahl eines Tools wichtig zu beachten ist.
Kurze Präsentation ausgewählter Tools.
Andere erwähnenswerte Tools.
Hier finden Sie die Aufzeichnung in deutscher Sprache.
Webinar 3: NLP Case Study - Entity Recognition in Dokumenten | 18. Juni von 11-12 Uhr (CEST)
Offizieller Start des BMBF-Projekts LaserSKI
Unter der Projektleitung von dida haben das Leibniz Ferdinand-Braun-Institut, eagleyard Photonics, Coherent DILAS und Innolume zum 1. April 2020 das Forschungsprojekt LaserSKI begonnen, welches vom Bundesministerium für Bildung und Forschung gefördert wird. Ziel des Projektes ist es einen Machine-Learning-Algorithmus zu entwickeln, um Fehler in verschiedenen Stufen der Laserdiodenproduktion zu erkennen. Zusätzlich wird ein Referenzrahmen für Fehlerklassen erstellt, welcher in der gesamten Photonikindustrie anwendbar ist.
Das Gesamtprojektvolumen beträgt knapp 2 Mio. EUR. Aus über 400 Projektvorschlägen war LaserSKI eines der 21 Projekte, die im Rahmen der Bekanntmachung "Anwendungen von Methoden der Künstlichen Intelligenz in der Praxis" ausgewählt wurden. dida freut sich auf ein spannendes Projekt in einer High-Tech-Industrie mit etablierten Unternehmen und Forschungsinstituten als Partner!
COVID-19: Michael Borinsky beteiligt sich an einem Joint Venture vom RKI & der HU Berlin
Mathematische Modelle können COVID-19 nicht heilen, aber sie können uns helfen zu verstehen, wie sich das Virus ausbreitet, und die geeigneten Maßnahmen zur Eindämmung der Pandemie zu ergreifen.
Michael Borinsky, dida's External Advisor, trug zu einem gemeinsamen Projekt des Robert-Koch-Instituts und der Humboldt-Universität zu Berlin bei, das u.a. länderspezifische Vorhersagen über die Fallzahlen von COVID-19 für die nächsten 6 Tage liefert.
Bitte genießen Sie die Vorhersagen mit Vorsicht: selbst wissenschaftlich fundierte Vorhersagemodelle können versagen (wie z.B. Wettervorhersagen).
dida bei der Konferenz Digitaler Staat
Philipp Jackmuth von dida nahm an der 2-tägigen Konferenz Digitaler Staat teil, die vom 2. bis 3. März in Berlin Innovatoren, Modernisierer und Trendsetter zu intensiven Diskussionen zusammenbrachte.
Ein zentrales Thema war die laufende Umsetzung des Online-Zugangsgesetzes (OZG), das der Verwaltungsdigitalisierung derzeit einen großen Schub verleiht. In diesem Zusammenhang wurde die Frage diskutiert, was nach der Umsetzung des OZG geschehen sollte, um den Weg in die digitale Zukunft der Verwaltung erfolgreich zu gestalten. Schirmherrin und Eröffnungsrednerin des Kongresses war wieder einmal die Staatsministerin für Digitalisierung Dorothee Bär.
Spannende GovTech-Challenge in Dänemark
Es war ein aufregender Tag in Kopenhagen, an dem Lorenz Richter, CTO bei dida, und Wolf Winkler, Senior Consultant bei dida, der dänischen Behörde für Sicherheitstechnik (DSTA) die Ergebnisse einer fünfwöchigen GovTech-Herausforderung präsentierten. Die vorgeschlagene Lösung automatisiert wesentliche Teile des Arbeitsablaufs von Produktprüfern auf der Grundlage der KI-Technologien Computer Vision (CV), Bilderkennung und Verarbeitung natürlicher Sprache (NLP). Ziel ist es, die Inspektoren von administrativer Arbeit zu entlasten und ihnen so zu ermöglichen, die Anzahl der Produktinspektionen zu erhöhen. Das Feedback des Challenge Owner zu unseren Vorschlägen war überwältigend positiv. Wir danken dem DSTA und unseren Partnern von PUBLIC für die Organisation der Herausforderung und für die warme und einladende Atmosphäre. Wir freuen uns sehr darauf, dies weiter zu verfolgen. Besonders, da es sehr wahrscheinlich den Besuch schöner Orte in Dänemark und die Zusammenarbeit mit dem führenden digitalen öffentlichen Sektor und der Regierung in Europa beinhalten wird.
dida unter den KI-Startups in der appliedAI-Startup Landscape
dida wurde von appliedAI, der AI Initiative der TU München, als eines der deutschen KI-Startups gelistet. Das jährlich erscheinende Poster "AI German Startup Landscape" schafft einen Überblick über KI-Firmen, die in verschiedenen Branchen tätig sind. Im Jahr 2020 waren 247 Startups gelistet und dida ist unter "Industries, Other" zu finden. Wir sind stolz darauf, zu den Start-ups zu gehören, die produktive KI-Lösungen für unsere Partner programmieren und teilen das Ziel von appliedAI, KI zugänglich für die deutsche Industrie zu machen.
KI in der Fernerkundung beim DLR Bonn
Am 27. Februar fand ein Fachgespräch zum Thema künstliche Intelligenz Verfahren in der Erdbeobachtung am Deutschen Luft- und Raumfahrtzentrum (DLR) in Bonn statt. Aus der Privatwirtschaft nahmen Firmen wie Eftas, GAF AG und Live-EO teil. dida wurde durch ihren Geschäftsführer, Philipp Jackmuth, vertreten. Gemeinsam wurde mit Vertretern aus Wissenschaft und öffentlicher Hand diskutiert, welche Rahmenbedingungen geschaffen werden können, um den Einsatz von KI-Verfahren in der Erdbeobachtung zu erleichtern. Die Teilnehmer waren sich einig, dass neben einer nutzerfreundlichen Daten-Infrastruktur auch die Bereitstellung von annotierten Trainingsdaten vorteilhaft sei. Des Weiteren sollen erfolgreiche Anwendungen von KI-Verfahren durch Showcases und einen vermehrten Wissensaustausch auch anderen Marktteilnehmern zur Verfügung gestellt werden.
dida wurde zum Pitch beim Nvidia Inception Summit ausgewählt
Im Februar 2020 wurde dida ausgewählt, ASMSpotter am 6. März auf dem (Nvidia Inception Summit)[https://events.nvidia.com/inception-summit] zu präsentieren. ASMSpotter ist ein ESA-Projekt, das von dida und dem (Institut für Mineralische Rohstofftechnik (MRE))[http://mre.rwth-aachen.de/?noredirect=de_DE] an der RWTH Aachen entwickelt wurde. Ziel des Projektes ist die automatische Lokalisierung von artesanalen und kleinräumigen Bergbaustandorten (ASM) im Amazonas-Regenwald von Surinam. dida wurde zusammen mit sieben weiteren Unternehmen ausgewählt, um ihre Arbeit zu präsentieren.
dida auf dem Netzwerktreffen des ZIM Netzwerkes agraSpace
Die Landwirtschaft ist wahrscheinlich einer der Industriezweige mit dem größten Potenzial für die Anwendung von Computer Vision, da Vegetationsfortschritt, Ungeziefer und Blattkrankheiten von Satellitenbildern, UAVs oder Drohnen aus beobachtet werden können. dida engagiert sich im ZIM-Innovationsnetzwerk agraSpace, um Ideen über die Anwendungen von Computer Vision in der Landwirtschaft auszutauschen. Am 27. Februar fand am Leibniz-Institut für Agrartechnik und Bioökonomie e.V. (ATB) ein Netzwerktreffen statt, bei dem sich die Netzwerkpartner trafen, um mögliche Projekte zu diskutieren und nach potenziellen Partnern für gemeinsame Förderanträge zu suchen. Zu den Partnern gehören Forschungseinrichtungen wie das Leibniz-Institut für Agrartechnik und Bioökonomie e.V. (ATB), das Leibniz-Zentrum für Agrarlandschaftsforschung (ZALF), das Deutsche GeoForschungsZentrum (GFZ) und private Unternehmen wie die Vereinigte Hagelversicherung, 365FarmNet und dida. Themen der Veranstaltung waren u.a. die neuen Förderrichtlinien des ZIM-Programms, eine Präsentation von Ideen für Forschungsanträge des Leibniz-Instituts für innovative Mikroelektronik (IHP), ein Vortrag aus der landwirtschaftlichen Praxis von Herrn Meise von der Firma agrafrisch, einem landwirtschaftlichen Unternehmen aus Ostbrandenburg, und ein Vortrag über ein Projekt der BTU Cottbus-Senftenberg zu einem vom BMWI geförderten Projekt zum Strukturwandel in der Lausitz.
dida wurde für das ESA-Kickstartprojekt "4D Urban Insights" ausgewählt
dida ist stolz darauf, für die ESA-Kickstart-Aktivität "4D Urban Insights" im Rahmen der Ausschreibung für Bewerbungen mit gesellschaftlicher Wirkung ausgewählt worden zu sein. Mit "4D Urban Insights" will dida eine Software zur Erkennung von Zersiedelung und Bebauung schaffen, um Stadtplanern und Versicherungen ein Werkzeug an die Hand zu geben, mit dem sie das Stadtwachstum in schnell wachsenden Städten verfolgen können. Im Jahr 2050 werden 68% der Weltbevölkerung in Städten leben, gegenüber 30% vor siebzig Jahren. 90% des städtischen Bevölkerungswachstums wird bis 2050 aus Asien und Afrika kommen. In Afrika wachsen die Städte insbesondere durch das Bevölkerungswachstum und die Migration in städtische Gebiete . Aus diesem Grund werden die zehn schnellst wachsenden Städte in den nächsten fünfzehn Jahren in Afrika liegen. Deshalb konzentriert sich die Machbarkeitsstudie auf fünf afrikanische Städte im Golf von Guinea: Lagos, Abidjan, Luanda, Accra und Douala. Wir freuen uns auf ein weiteres interessantes Projekt zusammen mit der ESA.
Applied Machine Learning Days 2020 in Lausanne
Zu viert waren wir bei den Applied Machine Learning Days im SwissTech Convention Center in Lausanne. Unser William Clemens hielt einen Vortrag und zusätzlich hatten wir die Chance unsere Dienstleistungen auf der Ausstellungsfläche zu präsentierten. Will gab einige Einblicke in die Erkennung von Mustern in geostationären Satellitendaten mit Hilfe von Convolutional Neural Networks. Wir haben uns über das große Interesse an unseren Use Cases gefreut und sind dankbar für viele interessante Diskussionen mit Kollegen aus der Industrie und der Wissenschaft. Wir werden im Jahr 2021 auf jeden Fall wiederkommen!
dida beim Deutsche Bahn Accelerator-Programm
dida hat am Accelerator Programm der Deutschen Bahn, DB mindbox, teilgenommen. dida wurde als eines von drei Unternehmen ausgewählt, die ihre Lösung zur Extraktion von Informationen aus Zugdokumentationen und die Übertragung in ein internes Arbeitshandbuch zur Instandhaltung von Zügen, vorstellen durften. Die Deutsche Bahn lud alle Teams am 28. Januar in ihr Büro in Frankfurt ein, um die Details des Projekts zu besprechen, Workshops mit allen Teams zu veranstalten und den Teams die Möglichkeit zu geben, Fragen an die Ansprechpartner der DB Fachabteilungen zu stellen. Am Ende stellten alle Startups ihren Lösungsansatz vor und wurden von einer Jury der DB Fachabteilung bewertet.
2019
dida präsentiert ESA Kickstarter-Projekte beim DLR in Bonn
Johan Dettmar, Machine Learning Scientist bei dida, wurde eingeladen, auf der jährlichen Veranstaltung "National Program for Space Travel and Innovation" des DLR Raumfahrtmanagement in Bonn, Deutschland, zu präsentieren. dida wurde Anfang des Jahres mit zwei ESA Kickstarter-Projekten ausgezeichnet, nämlich "ASMSpotter", einem Machine Learning (ML) basierten Softwaretool zur Erkennung von handwerklichen Mining-Standorten im Nordosten Surinams sowie "4D Urban Insights", einem ML-Softwaretool zur Überwachung der Stadtentwicklung von 5 westafrikanischen Städten. Die beiden Projekte wurden verschiedenen Mitgliedern von ESA und DLR sowie deren akademischen und industriellen Partnern vorgestellt.
Fachposter Natural Language Processing
Zusammen mit AI Spektrum haben wir ein Poster zum Thema Natural Language Processing (kurz NLP) erstellt. Es beschreibt Techniken und Methoden zur maschinellen Verarbeitung natürlicher Sprache. Das Ziel ist eine direkte Kommunikation zwischen Mensch und Computer auf Basis der natürlichen Sprache.
Das Fachposter informiert über Herangehensweise, Funktion und Anwendungsgebiete. Hier kann man das Poster in hoher Auflösung herunterladen (Registrierung nötig). Viel Spaß bei der Lektüre!
dida präsentiert ASMSpotter beim ESA Mining Workshop
Robert Heesen, Director Product bei dida, wird am 28. November die Kickstart acitivity "ASMSpotter" bei der Europäischen Weltraumbehörde ESA in Harwell,
Großbritannien vorstellen. Der Workshop ""Weltraum-Anwendungen für den Bergbau", veranstaltet von ESA,
Catapult und dem United Nations Crime Institute (UNICRI) wird sich mit Themen wie der Überwachung und Verbesserung von Bergbaubetrieben und der
Förderung sozialer Aktivitäten, Umweltüberwachung und Finanzierungsmöglichkeiten für Bergbauaktivitäten befassen. Darüber hinaus werden Fallstudien
aus dem Bergbau- und Strafverfolgungssektor und Machbarkeitsstudien vorgestellt.
dida präsentiert das DWD-Projekt beim DLR
Will Clemens, Machine Learning Scientist bei dida, wird auf dem diesjährigen DLR Symposium "Neue Perspektiven der Erdbeobachtung" eines unserer kürzlich abgeschlossenen Projekte für den Deutschen Wetterdienst (DWD) vorstellen. Unter dem Titel "Machine Learning basierte Erkennung von Gewitterwolken in METEOSAT Satellitenbildern" wird Will ein Projekt zur Verbesserung der Wetterüberwachung an Flughäfen vorstellen. Die Präsentation findet am 13. November um 16.00 Uhr in der Session 6a "KI-Anwendungen" statt.
dida bei der ZIM-Netzwerkjahrestagung "AI for the German Mittelstand"
dida ist an den beiden ZIM-Netzwerken agraSpace und CopServ beteiligt und wird daher am 24. September in Berlin am jährlichen Treffen der ZIM-Netzwerke teilnehmen. Die diesjährige
Das Thema "Künstliche Intelligenz im Mittelstand - mit ZIM-Netzwerken in die digitale Zukunft" ist für die dida von hoher Relevanz, da KI in Zukunft eine große Rolle für den deutschen Mittelstand spielen wird und ZIM-Netzwerke eine gute Möglichkeit bieten, mit potenziellen Endanwendern zu kooperieren und Anwendungsfälle aus verschiedenen Branchen kennenzulernen. In letzter Zeit wurden KI-Softwareprojekte selten mit ZIM-Mitteln gefördert, so dass das Thema dieser Konferenz nahelegt, dass für den neuen ZIM-Förderzyklus ab 2020 signifikante Veränderungen für KI-Softwareunternehmen wie dida zu erwarten sind.
dida bei Intergeo
Da dida in den letzten Monaten mehrere Fernerkundungsanwendungen für Kunden wie ENPAL und DWD umgesetzt hat, wird Robert von dida nächste
Woche die Intergeo, die führende Geodatenmesse in Europa und jährlicher Treffpunkt der Geodatengemeinschaft besuchen. Die Intergeo findet in der Messe
Stuttgart vom 17. bis 19. September statt. Schwerpunktthemen der diesjährigen Intergeo sind Smart Cities und die Digitalisierung des öffentlichen Dienstes.
Aussteller sind große Unternehmen und Institutionen wie Airbus und die Europäische Kommission sowie viele KMU und Start-ups.
dida bei der BMS Konferenz "Mathematics of Deep Learning"
Die dida Machine Learning Scientists Lorenz Richter und Konrad Schultka nahmen an der Konferenz Mathematics of Deep Learning teil, die sich mit den mathematischen Grundlagen tiefer neuronaler Netze und deren stetig wachsenden Anwendungen beschäfigt.
Unter anderem wurden Vorträge über äquivariante Verallgemeinerungen von Convolutional Neural Networks (Taco Cohen), über Zusammenhänge mit der Theorie der gewöhnlichen und partiellen Differentialgleichungen (Eldad Haber), über die nicht-konvexe Loss-Landschaft tiefer neuronaler Netze (René Vidal), über alternative Lernstrategien mittels Langevin-Gleichungen (Ben Leimkuhler) und über Anwendungen bei inversen Problemen und parametrischen partiellen Differentialgleichungen (Gitta Kutyniok) gehalten.
dida beim agrASpace Netzwerktreffen
dida ist Mitglied im agrASpace Innovationsnetzwerk von GEOKOMM und nimmt am 5. September am Netzwerktreffen in Berlin teil. Das Netzwerktreffen findet im "Forum Digitale Technologien" am Fraunhofer Heinrich-Hertz-Institut statt.
Ziel der Veranstaltung ist es, sich unter den 30 Partnern des ZIM-Netzwerks zu vernetzen und innovative Projekte in der Landwirtschaft zu diskutieren, die mit Satelliten- und in-situ-Daten realisiert werden können.
Durch ihre Projekterfahrung in der Programmierung von Computer Vision Anwendungen mit Satellitendaten für ENPAL und DWD verfügt dida über umfangreiche Erfahrungen auf diesem Gebiet und wird sich in den kommenden Jahren im Bereich der Fernerkundung weiter engagieren.
dida beim Google Machine Learning Bootcamp
Am 27. und 28. August 2019 nahmen die dida Data Scientists Johan Dettmar und Matthias Werner an der "Train the Trainers: Machine Learning Bootcamp" bei Google for Startups Campus in Warschau. Im Workshop ging es um Tipps und Tricks für Google-Partner, um Machine Learning Bootcamps für potenzielle und aktuelle Kunden zu organisieren und durchzuführen. Das Ziel der ML Bootcamps ist es, Kunden in die Welt des Machine Learning und der Data Science einzuführen und gleichzeitig nützliche Tools und Infrastrukturen auf der Google Cloud Platform zu präsentieren.
dida ist GCP Surge Partner
dida ist mittlerweile im Google Cloud Partner Programm in den "Surge"-Status aufgestiegen, welcher die höchste Stufe des Programms darstellt und nur wenigen Teilnehmern vorbehalten ist. Die gesamte Infrastruktur der Google Cloud, die Daten- und API-Lösungen sowie die Rechenleistung geben dida die Möglichkeit, modernste Machine-Learning-Anwendungen zu entwickeln. Wir freuen uns auf die weitere Partnerschaft mit Google!
Interview mit #KI_Berlin
Die Plattform #KI_Berlin spiegelt die Berliner KI-Szene wider und dient der Vernetzung der nationalen und internationalen KI-Community. KI-Berlin.de zeigt aktuelle und zukunftsweisende Entwicklungen, Netzwerke, Initiativen und Experten.
Sie wandten sich an unseren CTO Lorenz Richter und unseren Geschäftsführer Philipp Jackmuth, um sowohl über Anwendungen im Bereich Computer Vision als auch über allgemeine Rahmenbedingungen im KI-Bereich in Deutschland zu sprechen (-> hier finden Sie das komplette Interview). Das Ziel von KI_Berlin ist es, Technologieunternehmen, Startups, Forschungseinrichtungen und Talente auf einer Plattform zu verbinden und Berlin als KI-Standort sichtbar zu machen."
dida an der Universität Mainz - Medizinische Fakultät
Die Medizinische Fakultät der Universität Mainz veranstaltet jedes Jahr die DICOM-Konferenz für Radiologen. Neben dem Bilddatenmanagement standen die Themen Künstliche Intelligenz und Datensicherheit im Vordergrund. dida wurde eingeladen, einen Vortrag über aktuelle Forschungsthemen im Bereich Machine Learning und Mustererkennung in medizinischen Bildern zu halten. Wir freuten uns über die Gelegenheit, mit Radiologen und Medizintechnikern die Bedürfnisse und Erwartungen an die Prozessautomatisierung und Entscheidungsunterstützungssysteme in der Radiologie zu diskutieren.
dida beim BDLI Network Meeting
dida geht am 14. Juni zum ersten BDLI Network Meeting in Berlin in der FABRIK 23. Das Thema des Netzwerktreffens lautet: "Wir sind ein Team für die Zukunft - Wie können New Space und Classic Space zusammenarbeiten?". Da die dida viel mit Raumdaten arbeitet und immer mehr Anwendungen mit Hilfe von Machine Learning Algorithmen betrieben werden, freuen wir uns auf interessante Diskussionen und Präsentationen. Wenn du Robert vom dida-Team treffen möchtest, kannst du dich gerne an ihn wenden!
dida tritt dem Space2Agriculture Innovation Network bei
Wir freuen uns, mitteilen zu können, dass dida Mitglied im staatlich geförderten Innovationsnetzwerk Space2Agriculture geworden ist, das vom DLR initiiert wurde. Weitere Partner des Netzwerks sind verschiedene Institute von Fraunhofer und DLR, Deutscher Bauernverband, John Deere oder KWS Saat.
Wir teilen die Vision des DLR, dass die Landwirtschaft einer der ersten Sektoren sein wird, der aus Weltraumdaten mit verschiedenen Anwendungen in der Klassifizierung von Nutzpflanzen, der Kontrolle von EU-Fördermitteln für die Landwirtschaft, der Modellierung von Pflanzenwachstum und der Präzisionslandwirtschaft Nutzen ziehen wird. Darüber hinaus werden Drohnen immer mehr visuelle Daten liefern, die von Machine Learning-Algorithmen interpretiert werden können. Da die dida über umfangreiche Erfahrungen in der Mustererkennung und Bildsegmentierung von Satellitenbildern verfügt, glauben wir, dass die Landwirtschaft eine vielversprechende Branche mit verschiedenen interessanten Problemen ist, die mit Machine Learning und Computer Vision Software zu lösen sind.
dida bei der Deep Learning World in München am 6. Mai
In unserer Nachmittagssitzung am 6. Mai präsentierten wir die Erfahrungen aus einem aktuellen Legal-Tech-NLP-Projekt. Im Jahr 2018 wurden wir beauftragt, eine Software zu entwickeln, die die Rechtsgültigkeit bestimmter Paragraphen in Mietverträgen beurteilen kann. Nachdem wir die Anwälte einem frühen Prototyp ausgesetzt hatten, stellten wir fest, dass wir detaillierte Erklärungen darüber geben mussten, wie das neuronale Netz seine Entscheidung herleitet. Aus diesem Grund haben wir uns entschieden, das Problem in verschiedene Module aufzuteilen, was wesentlich zu einer besseren Transparenz beigetragen hat. Ein Schlüsselmodul verwendet ein wiederkehrendes neuronales Netz (RNN) in Form eines bidirektionalen LSTM. Jetzt, da die Software in Produktion ist, wollten wir unsere Erfahrungen teilen und auch die Qualität der Vorhersagen diskutieren.
Die Deep Learning World fand in München zusammen mit der Konferenz Predictive Analytics World statt, die Hunderte von Datenwissenschaftlern aus ganz Europa anzog. Wenn Sie nicht an unserer Sitzung teilnehmen konnten, sich aber für eine Live-Demo unserer maschinellen Lernanwendung interessieren, können Sie sich gerne an uns wenden.
Treffen Sie uns beim IT-Vergabetag in Berlin am 15. Mai
Da dida im öffentlichen Sektor immer aktiver wird, werden wir an einem Workshop zum Thema öffentliche Ausschreibungen für IT-Unternehmen teilnehmen. Die Veranstaltung wird vom "Deutschen Vergabenetzwerk" organisiert und von der Europäischen Zentralbank sowie dem Bundesministerium für Umwelt und Naturschutz unterstützt. Wir freuen uns bereits auf einen interessanten Austausch mit allen Beteiligten im Bereich der öffentlichen Beschaffung.
dida tritt dem CopServ Network bei
Wir freuen uns, Teil des staatlich geförderten Kooperationsnetzwerks CopServ zu sein. Gemeinsam mit international renommierten Partnern und Forschungseinrichtungen wie der Ruhr-Universität Bochum, Eftas oder Exasol will CopServ Innovation und Wachstum durch die Förderung der Nutzung von Daten aus dem europäischen Satellitenprogramm Copernicus fördern. Die Haupteinsatzgebiete sind erneuerbare Energien, Forstwirtschaft, Landwirtschaft und Bergbau.
Da dida in den letzten Jahren mehrere Projekte im Bereich der Mustererkennung aus Satellitensensenderdaten erfolgreich abgeschlossen hat, sind wir uns der möglichen Fortschritte bewusst, die durch eine stärkere Marktakzeptanz der Copernicus-Fernerkundungsdaten erreicht werden können. Daher stimmen wir mit der Agenda von CopServ überein und haben beschlossen, uns mit ihnen zu engagieren.
Treffen Sie uns bei 'Copernicus meets Galileo' in Bochum am 8. Mai
dida-Vertreter nahmen am 8. Mai an der Konferenz "Copernicus meets Galileo" teil. Gastgeber war die Technische Hochschule Georg Agricola in Bochum, Teilnehmer waren Kopernikus-Anwender aus ganz Deutschland. Vorträge von Institutionen wie dem DLR, T-Systems und der RWTH Aachen über die Verwendung von Kopernikus- und Galileo-Daten sowie über Anwendungen, die mit Kopernikus-Daten erstellt wurden, wurden gehalten. Den Abschluss der Veranstaltung bildete eine Raumshow im Planetarium Bochum zu Pink Floyd Musik.
dida beim Digital Future Science Match am 14. Mai in Berlin
dida-Mitarbeiter werden am 5. digital future science match teilnehmen, das vom Hasso-Plattner-Institut, dem Zuse Institut Berlin und dem Tagesspiegel organisiert wird. Die Konferenz steht unter dem Motto "What's next in Artificial Intelligence?" und wird von prominenten Referenten wie Anja Karliczek, Bundesministerin für Bildung und Forschung, und Christoph Schütte, Präsident des Zuse Instituts Berlin, begleitet. Bitte kontaktieren Sie uns, um ein Treffen zu vereinbaren, wenn Sie mehr darüber erfahren möchten, was die dida für Ihr Unternehmen tun kann oder um Best Practices zu KI-Projekten im Allgemeinen zu diskutieren.
2018
dida ML Meetup am 1. November im Mindspace Berlin
Vielen Dank an fast 100 Kunden und Freunde, die an unserem Machine Learning Meetup im Mindspace Berlin teilgenommen haben. Wir hatten beschlossen, die Veranstaltung in 2 Sitzungen aufzuteilen: 1) Den Computer lehren zu sehen: Tiefenlernen und Bildsegmentierung, 2) Von 2d bis 3d: Nachbearbeitung und projektive Geometrie. Unten finden Sie sich in unserem neuesten Imagevideo wieder, das aus dem beim Treffen gefilmten Material produziert wurde.
Unser Vortrag auf der Deep Learning World am 12. November in Berlin
Wir haben die Gelegenheit sehr genossen, auf der Deep Learning World Konferenz in Berlin einen Vortrag über das Innenleben von Faltungsneuronalen Netzen (CNNs) zu halten.
Im Jahr 2015 gewannen CNNs erstmals gegen den Menschen in der jährlichen ImageNet-Herausforderung zur Bildklassifizierung. Dies markierte einen Wendepunkt.
in der Objekterkennung innerhalb visueller Daten. Seitdem wurden weitere große Fortschritte bei der Algorithmik und Hardware gemacht.
Seite. Noch nie war es einfacher, ein CNN einzurichten und zu betreiben. dida nutzte diese technologischen Fortschritte, um
verschiedene Projekte. Die Präsentation gab dem Publikum Einblicke, wie Objekterkennungsprojekte geplant sind und welche Dienstleistungen erbracht werden.
werden für die technische Umsetzung des Projekts verwendet. Auch die wichtigsten Hindernisse und Lösungen wurden diskutiert. Vielen Dank an das Publikum für Ihre aktive Teilnahme an der Q&A-Sitzung!
Treffen Sie uns im Copernicus Forum in Berlin
Wir wurden eingeladen, vom 27. bis 29. November auf dem National Forum for Remote Sensing and Copernicus 2018 ein Poster aus einem aktuellen Fernerkundungsprojekt zu präsentieren. Ein wichtiger Teil des Projekts war die Bildsegmentierung, für die wir uns für ein von der Universität Freiburg entwickeltes neuronales Faltungsnetz entschieden hatten (-> U-Net). Gastgeber der Konferenz ist das Bundesministerium für Verkehr und digitale Infrastruktur in Berlin. Mit über 450 Teilnehmern und vielen erfahrenen Referenten ist das Kopernikus-Forum eine der bedeutendsten Veranstaltungen auf dem Gebiet der Fernerkundung in Europa.
Wir danken dem DLR (Deutsches Zentrum für Luft- und Raumfahrt) für die Einladung und allen Teilnehmern für den interessanten Austausch. Wir hoffen, Sie auf dem nächsten Forum wiederzusehen!
Team-Event auf der Pydata Berlin am 6. & 7. Juli
In diesem Jahr haben wir uns entschieden, gemeinsam mit allen Teammitgliedern an der PyData-Konferenz in Berlin teilzunehmen. Vielen Dank an die Organisatoren, die Referenten und Sponsoren wie Anaconda oder Rasa! Für uns war es eine interessante Veranstaltung mit vielfältigen Vorträgen, die von der Analyse von Zeitausdrücken in Dokumenten über generalisierte additive Modelle bis hin zu modernen Ansätzen des bayesischen Lernens reichten. Wie immer ist eines der angenehmsten Dinge bei PyData die entspannte und freundliche Atmosphäre. Wenn Sie interessiert sind, wurden die meisten Vorträge aufgezeichnet - Sie finden sie hier.
Unser Vortrag auf der PAW Industry 4.0 am 13. Juni in München
Auf der diesjährigen Konferenz Predictive Analytics World Industry 4.0 wurden wir gebeten, eine Fallstudie darüber vorzustellen, wie wir Deep Learning in einer Geschäftsanwendung eingesetzt haben.
Wir haben uns entschieden, ein kürzlich entwickeltes Softwareprogramm zu präsentieren, das in der Lage ist, aus Bilddaten die Anzahl der Solarmodule vorherzusagen.
die auf ein bestimmtes Haus passen können. Diese Anwendung muss mit Adressdaten als Input versorgt werden und
liefert innerhalb von Sekunden genaue Schätzungen der Dachfläche und der Anzahl der Solarmodule. Wir haben mit einem Live-Auftritt begonnen.
Demonstration der Anwendung und erläuterte dann das Innenleben, insbesondere den Teil der Bildsegmentierung.
wo wir tiefes Lernen nutzten. Vielen Dank an unseren Kunden Enpal, dass er sich die Zeit genommen hat, die Anwendung gemeinsam zu präsentieren.
dida Vortrag auf dem Pydata Berlin Meetup am 17. Januar
Nachdem wir in letzter Zeit hauptsächlich an Bildverarbeitungsanwendungen gearbeitet haben, haben wir uns entschieden, einige unserer Ergebnisse mit der Python-Community zu teilen. Pydata Berlin gibt uns die Möglichkeit, am 17. Januar vor bis zu 200 Personen einen Blitzreferat zu halten. Wir freuen uns schon sehr darauf und hoffen, viele bekannte Gesichter zu sehen!
Vielen Dank auch an Celera One für die Bereitstellung von Speisen, Getränken und der Location.




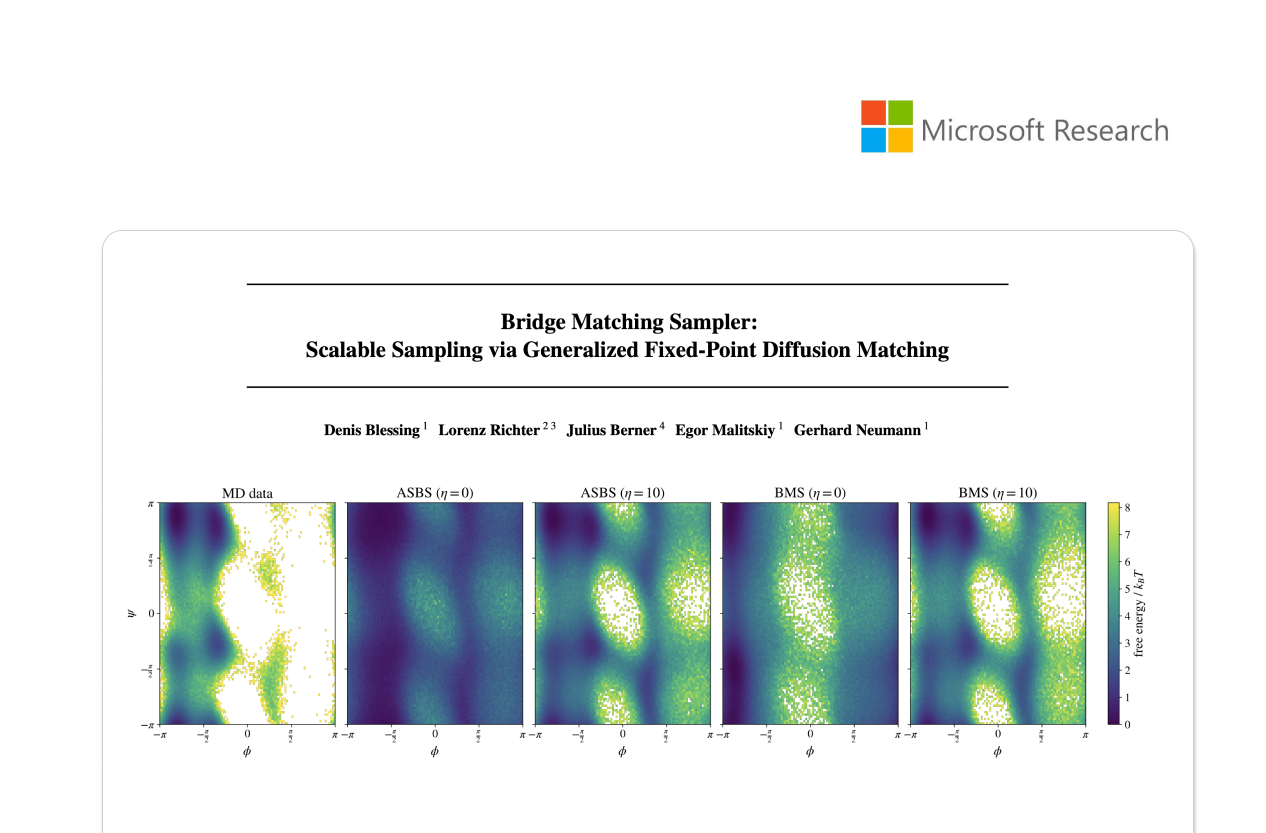

.png)
.png)





.png)

.png)








.png)
















.jpeg)














.png)








.png)








.jpg)
.png)





_small.jpeg)
































.png)





















_small.jpg)

_small.jpg)



_small.jpg)
_small.jpg)
_small.jpg)

_small.jpg)

_small.jpg)

_small.jpg)




_small.jpg)
_small.jpg)




_small.jpg)







_small.jpg)

.jpg)
