
AI Index Report 2022: Der aktuelle Stand der KI

Der AI Index Report sammelt Daten über die weltweite Entwicklung von künstlicher Intelligenz (KI). Die diesjährige fünfte Ausgabe der unabhängigen Initiative des Stanford Institute for Human-Centered Artificial Intelligence (HAI) zielt erneut darauf ab, relevante Stakeholder wie politische Entscheidungsträger, Forscher oder verwandte Branchen über die enormen Fortschritte von KI, die technologischen und gesellschaftlichen Stadien der wichtigsten KI-Disziplinen zu informieren und ein Bewusstsein für entstehende Probleme zu schaffen.
In diesem Artikel werden wir ausgewählte Kernaussagen des Berichts bzgl. Machine Learning (ML) präsentieren und unsere Perspektive von dida zu den folgenden Themen geben:
Forschung und Entwicklung
Technische Leistung
Technische KI-Ethik
Wirtschaft und Bildung
KI-Politik und Governance
Den vollständigen Bericht finden Sie in der Originalquelle hier.
Forschung und Entwicklung
Die Akteure im Bereich Forschung und Entwicklung (F&E) sind so aktiv und vernetzt (über Ländern und Sektoren hinweg) wie nie zuvor.
Im Jahr 2022 enthalten viele alltägliche Dienste ML-Funktionalitäten, die ursprünglich aus den Ergebnissen öffentlicher ML-Communities und ihrer FuE-Aktivitäten stammen. Diese Gemeinschaften arbeiten grenz- und sektorübergreifend und veröffentlichen ihre Ergebnisse weitgehend als Open Source Software. So hat die Öffentlichkeit Zugang zu äußerst wertvollen Beiträgen, was zu raschen Fortschritten in der ML-Technologie führt.
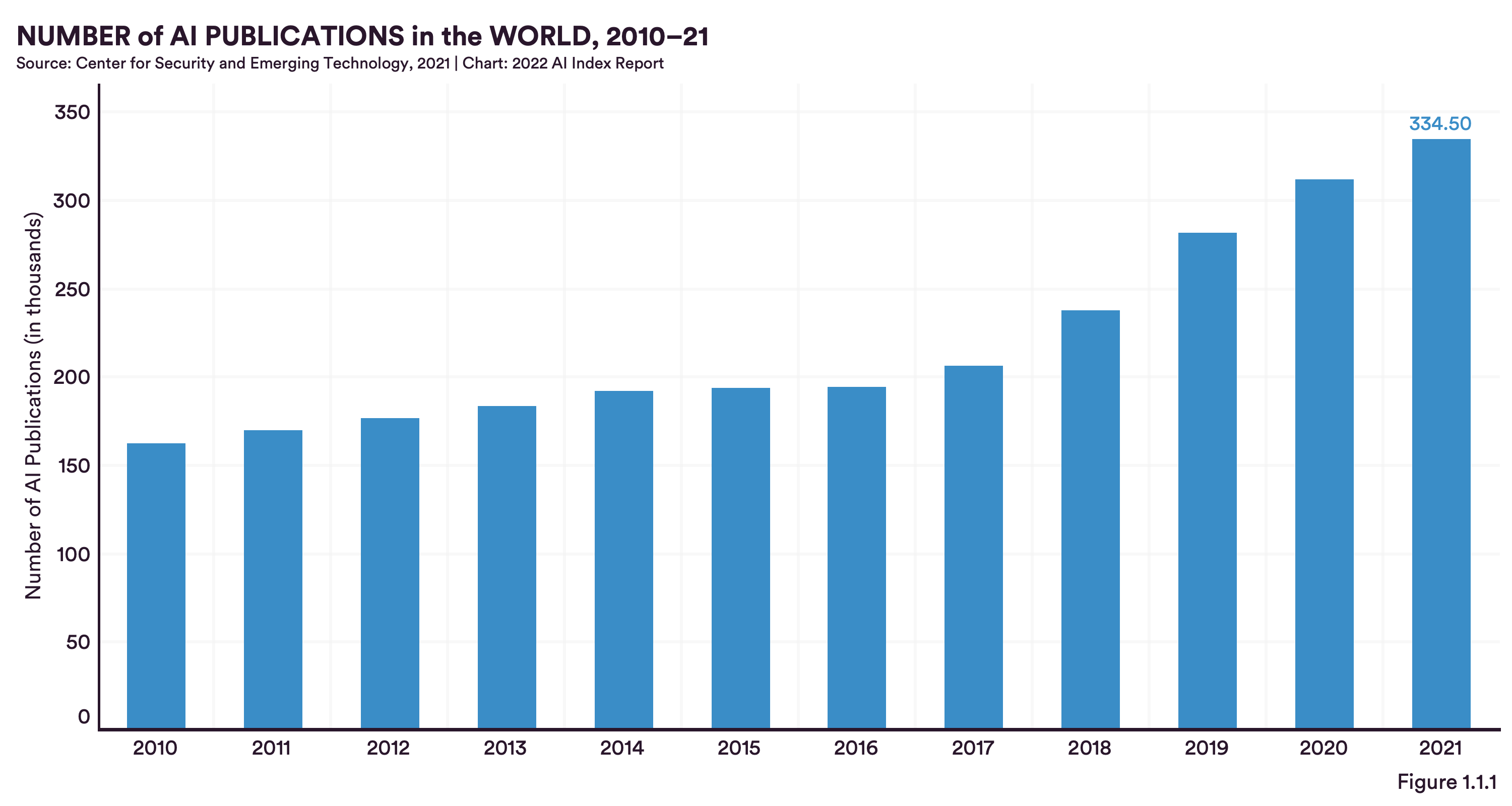
Betrachtet man die FuE-Aktivitäten nach Ländern, so wird deutlich, dass die beiden relevantesten Länder die Vereinigten Staaten von Amerika und China sind. Während China die höchste Anzahl an Veröffentlichungen pro Jahr hervorbringt, erreichen die USA die höchste Anzahl an Zitationen. Insgesamt hat sich die Zahl der Veröffentlichungen von 2010 bis 2021 verdoppelt (auf ca. 334.000). Darunter befinden sich viele Veröffentlichungen, die aus der internationalen Zusammenarbeit zwischen zwei Ländern hervorgegangen sind. Auch hier liefert die Zusammenarbeit zwischen den USA und China die meisten Ergebnisse, gefolgt von Großbritannien und China. Deutschland liegt mit seinem Kooperationspartner der USA auf Platz 5.
Die relevantesten Medien für die Veröffentlichung von Forschungsergebnissen sind akademische Journals, gefolgt von Konferenzen und Code-Repositories, während buchbasierte Veröffentlichungen in der KI-Forschung weniger bedeutend sind. Die beiden renommiertesten KI-Konferenzen sind nach wie vor die NeurIPS und die ICML, wenn man sie nach ihrer Teilnehmerzahl ordnet. Bei dida versuchen wir ebenfalls, uns aktiv an ML-Forschungsaktivitäten zu beteiligen, die wir dann in Produktionssoftware umsetzen und so die Brücke zwischen der akademischen Welt und der Industrie schlagen. Wir freuen uns, dass wir bereits Beiträge zu beiden Konferenzen (NeurIPS im Jahr 2020 und ein 'outstanding paper' zur ICML im Jahr 2021) beisteuern konnten und damit Teil dieser globalen Forschungsgemeinschaft sind.
Technische Leistung
Die technischen Leistungen haben sich innerhalb eines Jahres erheblich verbessert, so dass ML-Lösungen sich zu allgemeineren Fähigkeiten und zunehmenden Einsätzen in der Industrie entwickeln, während gleichzeitig die Schwachstellen von ML ebenfalls zunehmen.
Um die technischen Leistungen verschiedener ML-Lösungen zu vergleichen, werden sie je nach Aufgabe in der Regel an einigen großen Open-Source-Datensätzen getestet, wie ImageNet für Bildklassifizierungsaufgaben oder SQuAD für Fragenbeantwortungsaufgaben. Ein Trend, der sich gegenüber bestehenden Benchmarks durchsetzt, ist die Einbeziehung von externen Trainingsdaten in CV- und NLP-Projekte (9 von 10 ML-Lösungen, die bestehende Benchmarks schlagen konnten, nutzen dies). Wir bei dida stimmen dem zu und haben auch schon die Bedeutung von Daten für unsere Lösungen diskutiert und erklärt, wie ein datenzentrierter Ansatz die Leistung verbessern kann.
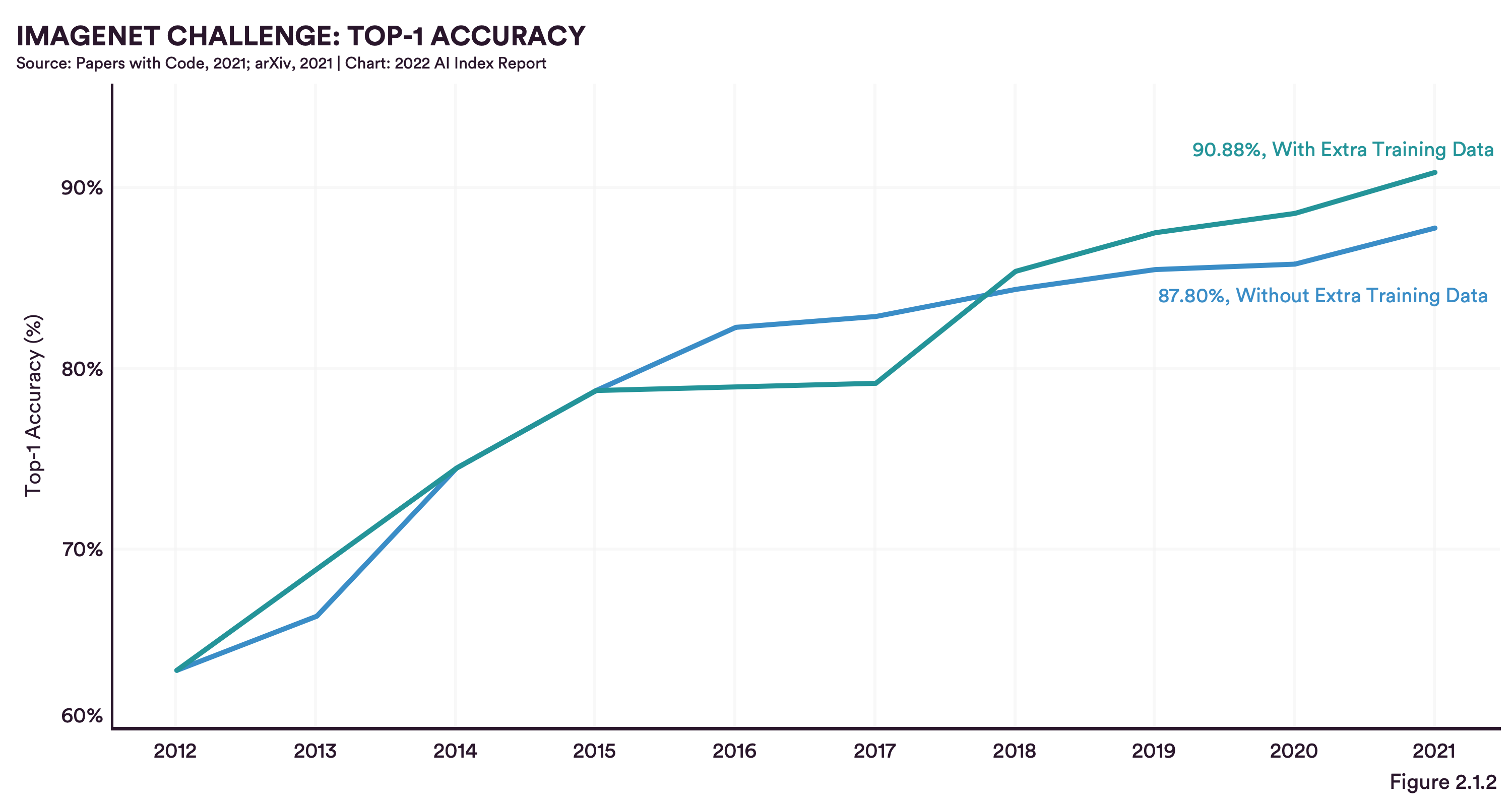
Die Quintessenz des Kapitels über Computer Vision (CV) ist im Grunde, dass in allen Teilbereichen von CV (d.h. Image Classification, Image Generation, Pose Estimation, Face Detection) die Leistungskurven ständig ansteigen, wenn auch nicht so extrem wie in früheren Jahren oder wie in jüngeren Teilbereichen von ML, wie z.B. Reinforcement Learning (RL). Sie führen dies darauf zurück, dass CV-Lösungen heute bereits sehr leistungsfähig sind, dass Convolutional Neural Networks (CNNs) im Anwendungsbereich sehr dominant sind und dass sich Verbesserungen eher auf Details als auf völlig neue Ansätze konzentrieren.
Etwas überraschend enthält der Bericht keine Zahlen über die vielversprechende Entwicklung von visuellen Transformatoren (ViTs) im Zusammenhang mit CV, die wir bei dida für sehr nützlich halten. Diesem Thema wird im nächsten Bericht vermutlich mehr Aufmerksamkeit geschenkt werden.
Generell deckt sich unsere Sichtweise bei dida mit den Ergebnissen des Berichts, dass CV einen Reifegrad erreicht hat, bei dem sich der Fokus mehr auf den Einsatz und weniger auf die Grundlagenforschung konzentriert. Hinzu kommt, dass die wesentlichen Beiträge von dida in vergangenen Projekten wie ASMspotter oder Crop Type Classification weniger die generellen Modellarchitekturen betrafen, sondern eher mathematische Details in der Pre- und Post-Processing, die Optimierung der Datenqualität oder die Nutzung der Zeitdimension. Wenn Sie sich für ML-Lösungen für Fernerkundungsdaten interessieren, schauen Sie sich unser entsprechendes Webinar an.
Die Natural Language Processing (NLP) umfasst eine Reihe von Teilaufgaben wie Sprachverständnis, Textzusammenfassung, natürliche Sprachinterferenz, Stimmungsanalyse oder maschinelle Übersetzung - einige komplexer als andere. Diese NLP-Modelle werden in der Regel mit den Fähigkeiten von Menschen bei genau der gleichen Aufgabe verglichen. Während ML bei grundlegenden Aufgaben wie dem Leseverständnis bereits besser abschneidet als der Mensch, sind ML-Modelle bei komplexeren Aufgaben wie der abduktiven Inferenz natürlicher Sprache (die Fähigkeit, auf der Grundlage von Informationen Schlussfolgerungen zu ziehen) noch schwächer. Nichtsdestotrotz werden Sprachmodelle immer leistungsfähiger, was vor allem auf das Aufkommen von Transformer-Modellen wie BERT oder GPT-3 zurückzuführen ist, die als De-facto-Standard im NLP angesehen werden können (ähnlich wie es CNNs in den letzten Jahren für den Lebenslauf waren).
Trotz ihrer leistungsstarken Fähigkeiten sind Transformer-Modelle recht groß und können kaum von Grund auf neu trainiert werden, was einerseits bedeutet, dass für Projekte mit nur kleinen Datensätzen Ansätze, die auf Recurrent Neural Networks (RNN) basieren, wie LSMTs, immer noch vorzuziehen sind, und andererseits zu der folgenden Schwäche führt: NLP-Lösungen hängen in hohem Maße von vorab trainierten Modellen ab, die die Arbeit mit Textdaten effizienter und in vielen Fällen überhaupt erst möglich machen. Die Open Source Verfügbarkeit von vortrainierten ML-Modellen ist zwar ein großer Vorteil für die gesamte ML-Community, birgt aber auch Risiken, denn Untersuchungen haben gezeigt, dass auch die größten, beliebtesten und fortschrittlichsten Sprachmodelle nicht frei von Verzerrungen sind. Aufgrund ihrer Vorteile können NLP-Lösungen jedoch kaum ohne sie funktionieren. Der index AI report widmet daher dem jungen Forschungsfeld der KI-Ethik ein ganzes Kapitel.
Im Gegensatz zu den ausgereifteren Bereichen CV und NLP haben die Algorithmen des Reinforcement Learnings (RL) eine schnellere Entwicklung durchgemacht. Während sie in früheren Jahren bei sehr spezifischen Aufgaben, wie dem Spiel Go, besser wurden, stellt der diesjährige AI Index Report fest, dass sie immer besser in allgemeineren Fähigkeiten werden. Die RL-Umgebung Procgen von OpenAI demonstriert dies sehr gut, da ihre RL-Fähigkeiten an einer Reihe von 16 verschiedenen Procgen-Spielen statt nur einem getestet werden. Mit dieser Entwicklung scheint RL dem Weg von CV und NLP zu folgen, die sich ebenfalls von spezifischen zu allgemeineren Lösungen entwickelt haben, gefolgt von einem breiten Einsatz. Künftige Herausforderungen werden nun darin bestehen, Lösungen zu schaffen, die darüber hinaus effizient sind.
Technische KI-Ethik
Immer komplexere Verzerrungen entstehen durch komplexere ML-Modelle, die eine Herausforderung für die Wissenschaft und die Industrie darstellen werden.
Im Kapitel "Technische KI-Ethik" des KI-Index-Berichts 2022 werden Daten über die Entwicklung des Bereichs der KI-Ethik, seine Ursachen, seine Bedeutung und seine Zukunftsaussichten vorgestellt. Im Allgemeinen gelten die Vorhersagen von Algorithmen als fair, wenn sie keine Gruppen aufgrund von Merkmalen wie Geschlecht, ethnischer Zugehörigkeit oder Religion positiv oder negativ beeinflussen. Da die Forschung jedoch zeigen konnte, dass es in den heutigen ML-Modellen verschiedene Arten von Verzerrungen gibt, konzentrieren sich immer mehr Veröffentlichungen (aus dem akademischen Bereich, aber auch aus der Industrie) auf ethische Aspekte.
Bei Sprachmodellen konnte zum Beispiel gezeigt werden, dass je komplexer ein Modell ist, desto wahrscheinlicher es ist, dass es toxische Ergebnisse produziert, wenn es mit toxischen Eingaben konfrontiert wird. Gleichzeitig sind komplexere Modelle aber auch besser in der Lage, Toxizität in ihren eigenen Ergebnissen zu erkennen. In dem Bericht heißt es, dass die bisherigen Bemühungen zur Verringerung der Toxizität zu einer schwächeren Leistung der Modelle führen. Außerdem scheinen multimodale Modelle (Modelle, die mehrere Eingabearten wie Bilder, Texte oder Sprache verwenden) multimodale Verzerrungen zu erzeugen, und je komplexer die Modelle werden, desto schwieriger wird es, diese Probleme zu bekämpfen. Jack Clarck, Co-Direktor des AI Index Report, erklärt, dass sich die ethischen Herausforderungen von den technologischen unterscheiden, da sie einen sozio-taktischen Ansatz zu ihrer Lösung erfordern und nicht einfach eine traditionelle technologische Lösung, die seiner Meinung nach viel schwieriger zu finden ist als die Lösungen, die ML zuvor benötigte.
Wenn Sie an weiteren Informationen über Ethik und ML interessiert sind, können Sie unseren einführenden Blogartikel dazu lesen
Wirtschaft und Bildung
Wirtschaftliche und bildungspolitische Anzeichen deuten auf einen zunehmende Integration von KI hin, da mehr Geld als je zuvor in KI investiert wird und die Zahl der KI-Spezialisten steigt.
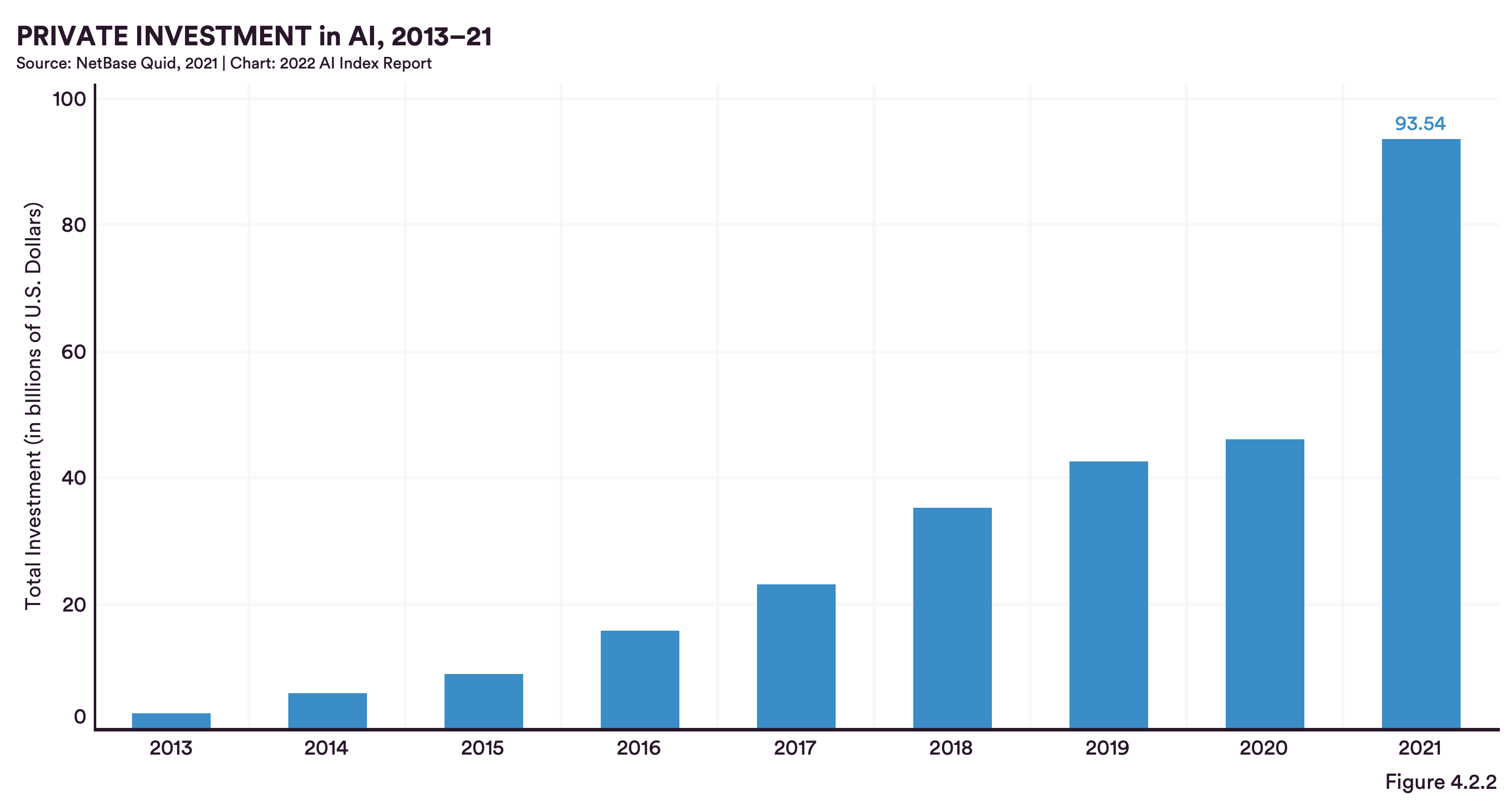
In Bezug auf den Kapitalfluss ist es interessant zu sehen, dass sich der Betrag der privaten Investitionen von 2020 bis 2021 ungefähr verdoppelt hat, während die Zahl der neu gegründeten Unternehmen abnimmt, was zu einer Konzentration des Kapitals bei weniger Akteuren führt.
KI ist nicht nur für Investoren attraktiv, sondern auch für Arbeitnehmer. Aus den Daten für die USA geht hervor, dass jeder fünfte promovierte Informatiker sich auf KI spezialisiert, was sie zur attraktivsten Spezialisierung macht. Die meisten dieser Absolventen finden dann eine Stelle in der Industrie und nicht in der Wissenschaft oder in anderen Organisationen. Was der KI-Index-Report nicht berücksichtigt, sind ähnliche akademische Bereiche, in denen die KI-Affinität ebenso hoch oder möglicherweise noch höher sein könnte. Ein kurzer Blick auf unser Team bei dida zeigt, dass die meisten unserer Machine Learning Scientists einen Hintergrund in Mathematik oder Physik haben - zwei Bereiche, die unserer Erfahrung nach sehr fähige KI-Spezialisten hervorbringen. Es könnten also noch mehr KI-Spezialisten in die KI-Industrie gehen.
KI-Politik und Governance
Politische Entscheidungsträger und Regierungen sind sich der rasanten Entwicklung der KI bewusst und haben begonnen, mögliche Gesetzesmaßnahmen zu diskutieren.
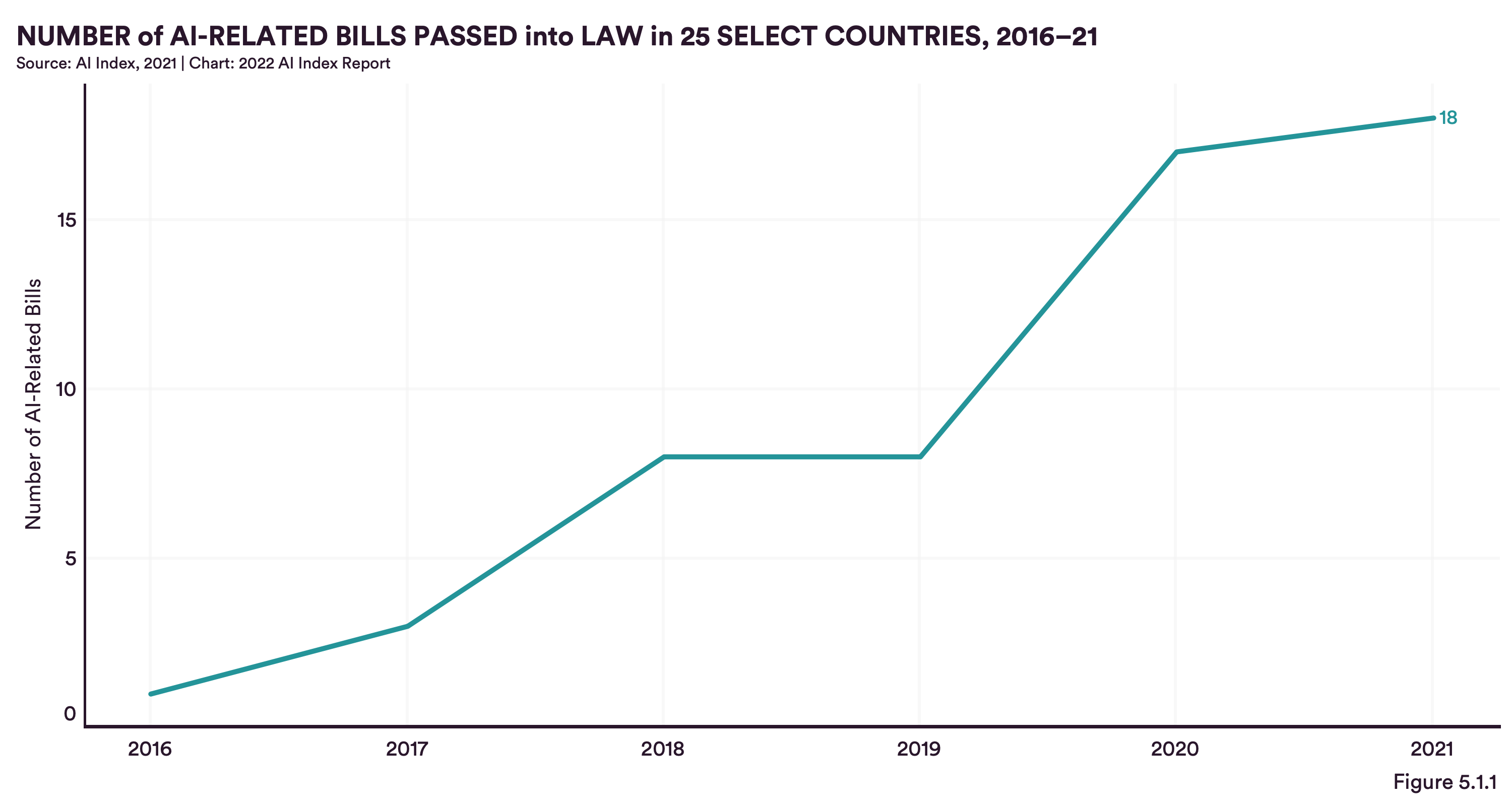
Technologische Entwicklungen können in der Regel schneller voranschreiten als politische Debatten und Gesetze. Im Jahr 2016 begann die Gesetzgebung langsam zu handeln und KI-bezogene Gesetze einzuführen. Bis 2021 wurden weltweit 18 Gesetze verabschiedet - Spanien, das Vereinigte Königreich und die USA führen die Rangliste mit jeweils 3 Gesetzen an. Auch wenn die Verabschiedungsrate solcher Gesetze nach wie vor niedrig ist (z. B. wurden nur 3 von 130 KI-Gesetzen in den USA verabschiedet), schafft die Politik ein Bewusstsein bei den Entscheidungsträgern. Dementsprechend steigt die Anzahl der Erwähnungen von KI-bezogenen Inhalten während der Sitzungen des US-Kongresses stark an. Der Bericht deutet also darauf hin, dass sich die Gesetzgeber der Notwendigkeit von KI-bezogenen Gesetzen bewusst sind und zunehmend ihre Bereitschaft signalisieren, zu handeln, bis sie dies schließlich tun werden. Es ist daher zu erwarten, dass immer häufiger KI-Gesetze erlassen werden, die die KI-bezogene Industrie erheblich stimulieren bzw. regulieren werden.
Fazit
Der Index AI Report 2022 bietet viele interessante Statistiken und Einblicke in die Entwicklung der KI und verwandter Bereiche. Die wichtigsten Aussagen lassen sich wie folgt formulieren:
Die FuE-Anstrengungen sind höher denn je und KI scheint sich von einem Prestigeprojekt zu einer echten (industriellen) Priorität entwickelt zu haben.
Während die Forschung früher hauptsächlich von der akademischen Welt betrieben wurde, nimmt die Industrieforschung zu und beeinflusst die KI-Gemeinschaft erheblich.
Die Leistungen und Fähigkeiten vieler KI-Technologien sind bereits auf einem Niveau, das über dem des Menschen oder nahe an dem des Menschen liegt, so dass Fragen des industriellen Einsatzes und der Skalierbarkeit stärker in den Vordergrund rücken als weitere Modellverbesserungen.
Mit der zunehmenden Komplexität der KI-Modelle steigen auch die damit verbundenen ethischen Probleme, was den Anstieg der KI-Ethikforschung erklärt, die sich mit der Überwindung von Problemen der zunehmenden Voreingenommenheit und Diskriminierung befasst.
Es wird mehr Kapital denn je in KI-Lösungen investiert, während die Zahl der neu gegründeten KI-Unternehmen zurückgeht, was zu einer Kapitalkonzentration bei den bestehenden KI-Akteuren führt.
Politische Entscheidungsträger auf der ganzen Welt sind sich zunehmend der Notwendigkeit von KI-bezogenen Gesetzen bewusst und obwohl die tatsächliche Einführung solcher Gesetze nach wie vor selten ist, signalisiert die Politik, dass sie in den nächsten Jahren mehr und mehr handeln wird.
Source:
Daniel Zhang, Nestor Maslej, Erik Brynjolfsson, John Etchemendy, Terah Lyons, James Manyika, Helen Ngo, Juan Carlos Niebles, Michael Sellitto, Ellie Sakhaee, Yoav Shoham, Jack Clark, and Raymond Perrault, “The AI Index 2022 Annual Report,” AI Index Steering Committee, Stanford Institute for Human-Centered AI, Stanford University, March 2022.