
What is Natural Language Processing (NLP)?

Natural Language Processing (short: NLP, sometimes also called Computational Linguistics) is one of the fields which has undergone a revolution since methods from Machine Learning (ML) have been applied to it. In this blog post I will explain what NLP is about and show how Machine Learning comes into play. In the end you will have learned which problems NLP deals with, what kinds of methods it uses and how Machine Learning models can be adapted to the specific structure of natural language data.
Defining Natural Language Processing
According to Wikipedia,
[n]atural language processing (NLP) is a subfield of computer science, information engineering, and artificial intelligence concerned with the interactions between computers and human (natural) languages, in particular how to program computers to process and analyze large amounts of natural language data.
I doubt that this definition satisfies you, though. NLP deals with the computer-aided analysis of natural language data, so much we got. But what kinds of analysis are these, and what kind of data qualifies as natural language data?
Natural Language Data
Intuitively, you might think that “natural language” encompasses those forms of language that people naturally learn as their mother tongues and speak and write in their everyday lives (or did so in earlier days), such as English, Hindi, Latin etc. In some academic disciplines it is thus defined as the languages that evolved in humans without conscious planning and regimentation. According to this definition, for example Esperanto is not a natural language.
When it comes to NLP, however, we are usually not that strict. We may just acknowledge all those languages as natural which humans in fact use or used to communicate which each other. The distinction to be made here is between human languages and formal languages such as programming languages.
There are two obvious ways to generate computer-processable data from natural language: We can either create audio files of recorded speech or encode it in strings of characters, that is, as text. Next to pure text documents, which are unstructured documents, we often deal with documents that consist to a considerable amount of text, but also different information-bearing structures such as tables. The latter are called “(semi-)structured documents”. As in these cases analysing the natural language elements is probably crucial for analysing the overall document, we consider these documents also natural language data.
Analysing Speech and Text
I guess you might already have some ideas about how computers might analyse natural language data. The following (non-exhaustive) list contains some of the most important types of analysis:
Speech recognition: Given an audio recording containing speech, “write down” what is said, i.e. map the speech to the corresponding text.
Part-of-speech-tagging: Given a sentence (e.g. as text), determine the part of speech for each single word. Tagging a sentence is often a prerequisite for further processing.
Machine translation: Translate sentences from one language to another language. This task is performed by e.g. Google Translate and DeepL.
Sentiment analysis: Given a text (e.g. a movie review), extract the overall sentiment. The results can be used for recommender systems.
Question answering: Answer questions automatically (e.g. for chat bots).
Automatic summarization: Given a text, summarize the most important information in a readable way.
Spam detection: Decide whether a given email is spam or not.
Named entity recognition: Given a text a predefined categories, locate and classify named entity mentions. More about this below.
More generally, any kind of task which extracts information from natural language data can be considered NLP.
Methods and auxiliary tools
There is a vast number of tools and techniques facilitating NLP. Three of them are especially important and so ubiquitous you might have already heard of them: Optical Character Recognition, Regular Expressions and Machine Learning. If you are acquainted with these terms, skip to the section “ML models for NLP”. If not, let me explain them briefly.
Optical Character Recognition (OCR)
In NLP we often want to perform tasks on printed documents such as letters, invoices or contracts. Digitalizing them is easy, we only need to scan or take a picture of them. But the representation of the document as an image is usually not suitable for further processing: We want to process characters, not pixel values. Luckily, there are a number of tools to extract text from document images: commercial services like ABBYY Finereader and Google Cloud Vision or the open source engine Tesseract OCR. For well-scanned typewritten documents all of them work reliable. Optical character recognition gets more challenging when it comes to low quality document photographs (with respect to resolution, illumination, distortion, …) and handwriting.


If you are interested in reading about a project involving OCR that we did at dida, you can do this here: Automatic Verification of Service Charge Settlements.
Regular Expressions
Imagine you are looking for dates in a document. I guess you wouldn’t have to read the document very carefully, because you know how dates are usually formatted and recognize them at first glance: often the formatting is DD.MM.YYYY (most of Europe) or MM/DD/YYYY (USA), where “D”, “M” and “Y” are digits representing the day, month and year respectively. How could you pass on this knowledge about date formats to an algorithm that finds them automatically? The solution is Regular Expressions: they enable you to define search patterns based on the presence or absence of (sequences of) certain characters, their multiplicity and the satisfaction of definable conditions. For a simple, but detailed practical example check out this previous blog post.
Creating many such patterns and defining an algorithm’s behaviour based on search pattern matches can lead to powerful NLP machineries. This rule-based approach helped to develop one of the first chat bots in the 1960s, ELIZA.
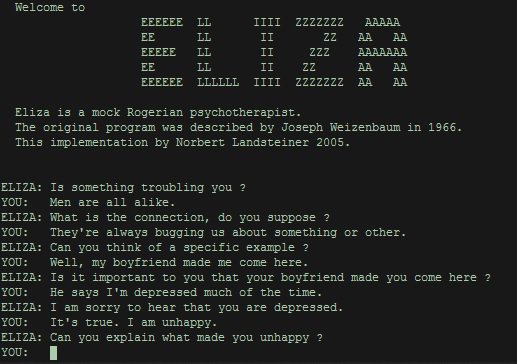
ELIZA managed to convince some people that she is human. One hilarious example is “an accidental conversation between eliza and bbn's vice president”.
Machine Learning
Hand-crafting Regular Expressions and rules can be a tiresome and tedious task. Moreover, it is a peculiar thing about natural languages that we manage to understand them perfectly in practice without necessarily having any knowledge about their theoretical workings: All of us have learned to speak our mother tongue long before we learned about its grammar in school. Thus, we can’t solve all NLP tasks by providing algorithms with a sufficient set of rules simply because we often don’t know the rules.
This is where Machine Learning models like neural networks come in: They promise to learn the relevant patterns on their own - provided there are enough training examples from which to abstract the patterns.
ML models for NLP
Since processing natural language data presents specific challenges, ML scientists created models adapted to the structure of that data. Typically, the data is sequential: In audio recordings the data is sequential with respect to a time axis; a text is a sequence of sentences, which in turn are sequences of words. We might just neglect this aspect and treat e.g. a sentence not as an ordered sequence, but as an unstructured set of words. Sometimes this approach is indeed useful (it is called “bag-of-words model”). But usually we can benefit from incorporating our knowledge about natural language data in the model. This gives rise to Recurrent Neural Networks (RNNs).
Recurrent Neural Networks
Imagine we want to create a model that is able to locate mentions of persons in texts. This is an example of named entity recognition. Often we don’t know in advance which person names might appear in a text, and we also don’t have a complete list of all names there are. Thus, we need an intelligent algorithm that manages to infer from the context of a word whether it is a person or not. For humans, that’s usually easy: Consider the sentence “X brought his kids to school”. It’s obvious from the context, i.e. the complete sentence, that X is a person. Given “Astrid spends her vacations in Y” instead it’s trivial to see that “Y” does not represent a person, but a location.
Let’s spell out what we want our model to do: It should take a sentence as input and then decide for every word whether it belongs to a person’s name or not, which means assigning it to one of two categories. Let us denote the words of a sentence by x1, x2 etc. Each of them shall be processed (let’s call this operation “U” and its output “si”) and then categorized (call this operation “V” and its output “oi”). If we did this in an isolated way for every single word, then we would lose the context information. To preserve it, we add a mechanism W by which the processed version of the word xt-1, that is st-1, influences st. Have a look at the image below:
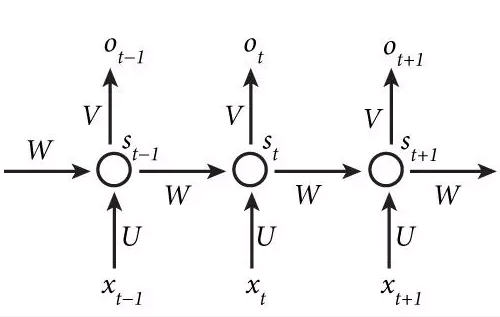
Vertically, the image displays how the words xt-1, xt, xt+1 are processed to obtain final outputs ot-1 etc. which we can think of as either “is a person” or “is not a person”. Horizontally, you see that the context st-1 influences st, and in turn st is used as context to influence st+1. Indirectly, st-1 also influences st+1 via its influence on st.
Let me make this a bit more concrete: Consider the sentence “they invited Z”. Our model might have already learned that “they” and “invited” don’t denote any specific persons, but that the word “invited” is often followed by the name of a person. By the horizontal W-connections, it is able to include this knowledge about “invited” in its decision how to categorize Z.
This is roughly the idea behind RNNs - although I have withheld a description of what U, V and W look like in detail (they correspond to matrices) and how we choose them appropriately (this is where self-learning appears).
There is an obvious caveat: As presented above, the RNN only takes into account the left context. By “left context” I mean the part of the sentence previous to a given word. This is taken care of in more complex bidirectional RNNs.
Takeaways
NLP is defined by the type of data it deals with.
It comprises a broad range of different tasks.
OCR tools extend the scope of NLP applications to (originally) printed documents.
Traditionally, NLP was carried out with a rule-based approach, employing Regular Expressions. Nowadays Machine Learning methods open up new possibilities.
Recurrent Neural Networks are used to exploit the sequential structure of natural language data.
Stay tuned for detailed presentations of our NLP projects and more in-depth discussions of RNN model architectures such as (bidirectional) LSTMs.
Contact
If you would like to speak with us about this topic, please reach out and we will schedule an introductory meeting right away.