
Was ist Natural Language Processing (NLP)?

Natural Language Processing (kurz: NLP, manchmal auch Computerlinguistik) ist eines der Gebiete, das eine Revolution erfahren hat, seit Methoden des Machine Learning (ML) auf es angewendet wurden. In diesem Blogbeitrag werde ich erklären, worum es bei NLP geht und zeigen, wie Machine Learning ins Spiel kommt. Am Ende werden Sie gelernt haben, mit welchen Problemen sich NLP beschäftigt, welche Methoden es verwendet und wie Machine Learning-Modelle an die Besonderheiten natürlichsprachlicher Daten angepasst werden können.
Der Begriff Natural Language Processing
Laut Wikipedia ist Natural Language Processing (NLP) ein Teilgebiet der Informatik, Informationstechnik und künstlichen Intelligenz, das sich mit den Wechselwirkungen zwischen Computern und menschlichen (natürlichen) Sprachen beschäftigt, insbesondere mit der Frage, wie man Computer programmiert, um große Mengen an natürlichsprachliche Daten zu verarbeiten und zu analysieren. Ich bezweifle jedoch, dass diese Definition Dich zufrieden stellt. NLP beschäftigt sich mit der computergestützten Analyse von natürlichsprachlichen Daten, so viel haben wir verstanden. Aber welche Arten von Analysen sind das und welche Art von Daten gilt als natürlichsprachlich?
Natürlichsprachliche Daten
Intuitiv könnte man meinen, dass "natürliche Sprache" jene Sprachen umfasst, die Menschen natürlich als Muttersprache lernen und in ihrem Alltag sprechen und schreiben (bzw. einst sprachen und schrieben), wie Englisch, Hindi, Latein usw. In einigen akademischen Disziplinen ist sie daher definiert als die Sprachen, die sich beim Menschen ohne bewusste Planung und Reglementierung entwickelt haben. Nach dieser Definition ist beispielsweise Esperanto keine natürliche Sprache.
Wenn es um NLP geht, sind wir jedoch normalerweise nicht so streng. Wir können einfach alle jene Sprachen als natürlich anerkennen, die Menschen tatsächlich benutzen oder benutzt haben, um miteinander zu kommunizieren. Der entscheidende Unterschied liegt zwischen menschlichen Sprachen und formalen Sprachen wie Programmiersprachen.
Es gibt zwei offensichtliche Möglichkeiten, computerverarbeitbare Daten aus natürlicher Sprache zu erzeugen: Wir können entweder Audiodateien der aufgezeichneten Sprache erstellen oder sie in Zeichenketten, d.h. als Text, kodieren. Neben reinen Textdokumenten, die unstrukturierte Dokumente sind, haben wir es oft mit Dokumenten zu tun, die aus einer erheblichen Textmenge bestehen, aber auch unterschiedlichen informationstragenden Strukturen wie Tabellen beinhalten. Letztere werden als "(semi-)strukturierte Dokumente " bezeichnet. Da in diesen Fällen die Analyse der natürlichsprachlichen Elemente für die Analyse des Gesamtdokuments wahrscheinlich entscheidend ist, betrachten wir diese Dokumente auch als natürlichsprachliche Daten.
Sprach- und Textanalyse
Ich schätze, Sie haben vielleicht schon einige Ideen, wie Computer natürlichsprachliche Daten analysieren können. Die folgende (nicht vollständige) Liste enthält einige der wichtigsten Arten von Analysen:
Spracherkennung: Bei einer Audioaufnahme mit Sprache "aufschreiben", was gesagt wird, d.h. die Sprache dem entsprechenden Text zuordnen.
Part of Speech-Tagging: Bestimme bei einem Satz (z.B. als Text) die Wortart für jedes einzelne Wort. Die Kennzeichnung eines Satzes ist oft Voraussetzung für die weitere Verarbeitung.
Maschinelle Übersetzung: Übersetze Sätze von einer Sprache in eine andere Sprache. Diese Aufgabe wird z.B. von Google Translate und DeepL erledigt.
Stimmungsanalyse: Wenn Sie einen Text (z.B. eine Filmrezension) erhalten, extrahieren Sie die Gesamtstimmung. Die Ergebnisse können für Empfehlungssysteme verwendet werden.
Beantwortung von Fragen: Beantworten Sie Fragen automatisch (z.B. für Chat-Bots).
Automatische Zusammenfassung: Fassen Sie die wichtigsten Informationen anhand eines Textes lesbar zusammen.
Spam-Erkennung: Entscheiden Sie, ob eine bestimmte E-Mail Spam ist oder nicht.
Named-entity recognition: Wenn ein Text eine vordefinierte Kategorie hat, können Sie benannte Entitätserwähnungen finden und klassifizieren. Mehr dazu weiter unten.
Generell kann jede Art von Aufgabe, die Informationen aus natürlichsprachlichen Daten extrahiert, als NLP betrachtet werden.
Methoden und Hilfsmittel
Es gibt eine Vielzahl von Werkzeugen und Techniken, die NLP erleichtern. Drei von ihnen sind besonders wichtig und so allgegenwärtig, dass Sie vielleicht schon von ihnen gehört haben: Optische Zeichenerkennung (Optical Character Recognition), Regular Expressions und Machine Learning. Wenn Sie mit diesen Begriffen vertraut sind, springen Sie zum Abschnitt "ML-Modelle für NLP". Falls nicht, lassen Sie mich sie kurz erläutern.
Optische Zeichenerkennung (OCR)
In NLP wollen wir oft Aufgaben mit gedruckten Dokumenten wie Briefen, Rechnungen oder Verträgen durchführen. Die Digitalisierung ist einfach, wir müssen sie nur scannen oder ein Foto von ihnen machen. Die Darstellung des Dokuments als Bild ist jedoch in der Regel nicht für die Weiterverarbeitung geeignet: Wir wollen Zeichen verarbeiten, nicht Pixelwerte. Glücklicherweise gibt es eine Reihe von Tools, um Text aus Dokumentenbildern zu extrahieren: kommerzielle Dienste wie ABBYYY Finereader und Google Cloud Vision oder die Open-Source-Engine Tesseract OCR. Bei gut gescannten maschinengeschriebenen Dokumenten funktionieren alle zuverlässig. Die optische Zeichenerkennung wird schwieriger, wenn es um qualitativ minderwertige Dokumentenfotos (in Bezug auf Auflösung, Beleuchtung, Verzerrung,....) und Handschrift geht.


Regular Expressions
Stellen Dir vor, Sie suchen nach Datumsangaben in einem Dokument. Ich schätze, man müsste das Dokument nicht sehr sorgfältig lesen, denn man weiß, wie ein Datum in der Regel formatiert ist und erkennt es auf den ersten Blick: Oft ist die Formatierung TT.MM.JJJJ (fast ganz Europa) oder MM/DT/JJJJ (USA), wobei "D", "M" und "Y" Ziffern sind, die Tag, Monat bzw. Jahr darstellen. Wie können wir dieses Wissen über Datumsformate an einen Algorithmus weitergeben, der sie automatisch findet? Die Lösung sind Regular Expressions: Sie ermöglichen es, Suchmuster zu definieren, die auf dem Vorhandensein oder Fehlen von (Sequenzen von) bestimmten Zeichen, deren Anzahl und der Erfüllung definierbarer Bedingungen basieren. Für ein einfaches, aber detailliertes Praxisbeispiel siehe diesen vorherigen Blogbeitrag.
Das Erstellen vieler solcher Muster und das Definieren des Verhaltens eines Algorithmus basierend auf Suchmusterübereinstimmungen kann zu leistungsfähigen NLP-Maschinen führen. Dieser regelbasierte Ansatz half bei der Entwicklung eines der ersten Chat-Bots in den 1960er Jahren, ELIZA.
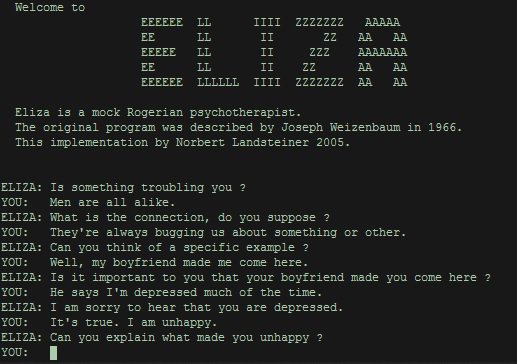
ELIZA hat es geschafft, einige Leute davon zu überzeugen, dass sie ein Mensch ist. Ein witziges Beispiel ist "ein zufälliges Gespräch zwischen eliza und dem Vizepräsidenten des bbn".
Machine Learning
Das Basteln von regulären Ausdrücken und Regeln kann eine lästige und langwierige Aufgabe sein. Darüber hinaus ist es eine Besonderheit der natürlichen Sprachen, dass wir es schaffen, sie in der Praxis perfekt zu verstehen, ohne unbedingt Kenntnisse über ihre theoretische Funktionsweise zu haben: Wir alle haben gelernt, unsere Muttersprache zu sprechen, lange bevor wir in der Schule etwas über ihre Grammatik gelernt haben. Daher können wir nicht alle NLP-Aufgaben lösen, indem wir Algorithmen mit einem ausreichenden Regelsatz ausstatten, eben weil wir die Regeln oft nicht kennen.
Hier kommen Modelle des Machine Learning wie neuronale Netze ins Spiel: Sie versprechen, die relevanten Muster selbst zu lernen - vorausgesetzt, es gibt genügend Trainingsbeispiele, um die Muster von ihnen zu abstrahieren.
ML-Modelle für NLP
Da die Verarbeitung natürlichsprachlicher Daten besondere Herausforderungen mit sich bringt, haben ML-Wissenschaftler Modelle entwickelt, die an die Struktur dieser Daten angepasst sind. In der Regel sind die Daten sequentiell: Bei Audioaufnahmen folgen die Wörter zeitlich aufeinander; ein Text ist eine Folge von Sätzen, die wiederum Wortfolgen sind. Wir könnten diesen Aspekt einfach vernachlässigen und z.B. einen Satz nicht als geordnete Folge, sondern als unstrukturierte Menge von Wörtern behandeln. Manchmal ist dieser Ansatz tatsächlich nützlich (er wird "Bag-of-Words-Modell" genannt). Aber in der Regel können wir davon profitieren, unser Wissen über natürlichsprachliche Daten in das Modell zu integrieren. Daraus entstehen Recurrent Neural Networks (Rekurrente Neuronale Netze, kurz: RNNs).
Recurrent Neural Networks
Stellen Sie sich vor, wir wollen ein Modell entwickeln, das in der Lage ist, Erwähnungen von Personen in Texten zu finden. Dies ist ein Beispiel für named-entity recognition. Oft wissen wir nicht im Voraus, welche Personennamen in einem Text vorkommen können, und wir haben auch keine vollständige Liste aller Namen, die es gibt. Wir brauchen also einen intelligenten Algorithmus, der es schafft, aus dem Kontext eines Wortes abzuleiten, ob es sich um eine Person handelt oder nicht. Für den Menschen ist das meist einfach: Denken Sie an den Satz "X hat seine Kinder zur Schule gebracht". Aus dem Kontext, d.h. dem ganzen Satz, ist ersichtlich, dass X eine Person ist. Wenn "Astrid ihre Ferien auf Y verbringt", ist es trivial zu sehen, dass "Y" keine Person, sondern einen Ort repräsentiert.
Lass mich ausbuchstabieren, was wir von unserem Modell erwarten: Es sollte einen Satz als Input nehmen und dann für jedes Wort entscheiden, ob es zum Namen einer Person gehört oder nicht, was bedeutet, dass es einer von zwei Kategorien zugeordnet wird. Bezeichnen wir die Wörter eines Satzes durch x1, x2 usw. Jedes von ihnen soll verarbeitet (nennen wir diese Operation "U" und ihr Ergebnis "si") und dann kategorisiert (nennen wir diese Operation "V" und ihr Ergebnis "oi") werden. Wenn wir dies für jedes einzelne Wort isoliert tun würden, dann würden wir die Kontextinformationen verlieren. Um sie zu erhalten, fügen wir einen Mechanismus W hinzu, mit dem die bearbeitete Version des Wortes xt-1, d.h. st-1, die Verarbeitung des folgenden Wortes, also st beeinflusst. Wirf einen Blick auf das Bild unten:
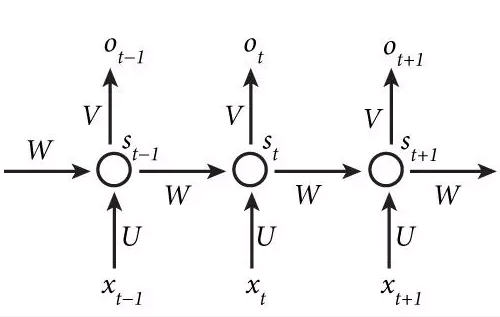
Vertikal zeigt das Bild, wie die Wörter xt-1, xt, xt+1 verarbeitet werden, um Ausgaben ot-1 usw. zu erhalten, die wir uns entweder als "ist eine Person" oder "ist keine Person" vorstellen können. Horizontal sehen wir, dass der Kontext st-1 den Wert st beeinflusst, und st wiederum als Kontext verwendet wird, um st+1 zu beeinflussen. Indirekt beeinflusst st-1 auch st+1 über den Einfluss auf st.
Lassen Sie uns das etwas konkreter machen: Betrachten wir den Satz "sie haben Z eingeladen". Unser Modell hat vielleicht schon gelernt, dass "sie" und "eingeladen" keine bestimmten Personen bezeichnen, aber dass das Wort "eingeladen" oft dem Namen einer Person (die eingeladen wurde) folgt. Durch die horizontalen W-Verbindungen kann es dieses Wissen über "eingeladen" in seine Entscheidung einbeziehen, wie Z zu kategorisieren ist.
Das ist ungefähr die Idee hinter RNNs - obwohl ich eine Beschreibung unterschlagen habe, wie U, V und W im Detail aussehen (sie entsprechen Matrizen) und wie wir sie angemessen auswählen (hier taucht das Selbstlernen auf).
Es gibt einen offensichtlichen Vorbehalt: Wie oben dargestellt, berücksichtigt das RNN nur den linken Kontext. Mit "linker Kontext" meine ich den Teil des Satzes, der einem bestimmten Wort vorausgeht. Dies wird bei komplexeren bidirektionalen RNNs berücksichtigt.
Takeaways
NLP wird durch die Art der Daten definiert, mit denen es sich beschäftigt.
Es umfasst ein breites Spektrum an unterschiedlichen Aufgaben.
OCR-Tools erweitern den Anwendungsbereich von NLP-Anwendungen auf (ursprünglich) gedruckte Dokumente.
Traditionell wurde NLP mit einem regelbasierten Ansatz unter Verwendung von Regular Expressions durchgeführt. Die Methoden des Machine Learning eröffnen heute neue Möglichkeiten.
Rekurrente neuronale Netze werden verwendet, um die sequentielle Struktur natürlichsprachlicher Daten auszunutzen.
Bleiben Sie dran für detaillierte Präsentationen unserer NLP-Projekte und vertiefte Diskussionen über RNN-Modellarchitekturen wie (bidirektionale) LSTMs.
Kontakt
Wenn Sie mit uns über dieses Thema sprechen möchten, kontaktieren Sie uns gerne und wir melden uns im Anschluss für ein unverbindliches Erstgespräch.