Since the performance of existing commercial and open source solutions for table extraction was not sufficient in tests (only 60-70% of tables were correctly recognized), we decided to develop our own custom solution:
We use a CascadeTabNet to identify areas of the document where tables are located. This identification takes place exclusively on the image level.
Subsequently, we analyze the positions of the strings within these areas and their relative arrangement to each other in order to recognize columns and rows of the tables and to be able to read out their contents in a structured way.
Using this approach, we were able to increase the accuracy of table recognition to 93%.
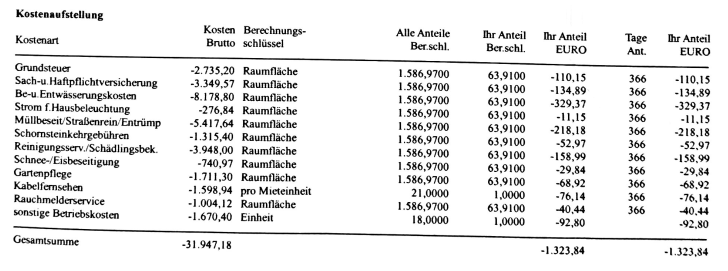
Review of the cost items
Based on the extracted table, listed cost items can be read out and evaluated. We want to check whether they can actually be passed on to the tenants.
Due to the often poor quality of uploaded documents, we decided to use an approach that is robust against OCR errors: the individual cost items are compared (as strings) with lists of
known admissible and
known inadmissible positions.
The comparison is done using a fuzzy string search, which outputs a similarity value for a pair of strings to be compared:
>>> fuzz.ratio("cable fees", "cable fees") -> 100
>>> fuzz.ratio("cable fees", "cable/TV fees") -> 87
>>> fuzz.ratio("cable fees", "property tax") -> 18
Since there are a variety of different algorithms for fuzzy string search (corresponding to different definitions of string similarity), we trained a machine learning classifier to consider and weight multiple types of similarity scores. Based on the associated similarity scores, the classifier makes an estimate of whether a given item is allocable or not:



.png)