
What is AI

The terms Artificial Intelligence (AI), Machine Learning (ML) and Deep Learning (DL) are used with staggering frequency. However, it is not obvious what they are supposed to describe and how they relate to each other. This blog article is meant to elucidate some of the terminology used in these fields for the tech-enthusiastic layman, as well as to give some high-level notion of how these technologies can be used in Computer Vision (CV).
Artificial Intelligence and Deep Learning
As of today, a universally accepted definition of intelligence is yet to be given. Most people would describe it as the ability to think logically, to reason or to independently solve complex problems. By the same token, the definition of AI is a bit fuzzy as well. There is a multitude of fields associated with it, ranging from robotics over automated theorem proving (ATP) to generative models. However, the most prominent sub-field is Machine Learning. The figure below shows the relationship of the terms in a schematic way.
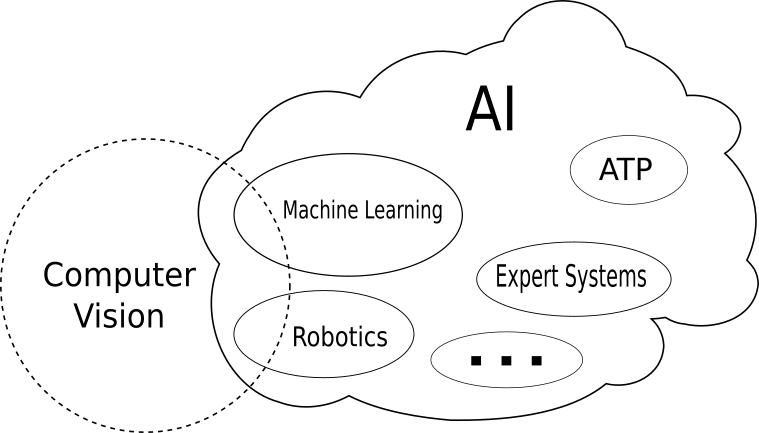
Machine Learning is the discipline where computers learn from vast numbers of examples to solve particular tasks. Possible applications range from text analysis to drug design. There is a whole cohort of algorithms that fall under the umbrella term Machine Learning.
Next to Support Vector Machines (SVM) and Decision Trees, Neural Networks are the go-to technology in ML. They are incredibly powerful function approximators and have shown comparable or even better performance on various classification, regression and controlling tasks. The following figure depicts the relationship of Machine Learning and its methods.

Neural Networks are a biologically inspired algorithm where the weighted sum of all inputs are passed through a non-linear function. The weights of the sum can be considered as synaptic connections, while the non-linear function mimics a neuron's response to a stimulus. In the simple Neural Network in the figure above the input vector x is passed to a single layer of neurons. As these neurons are neither the input nor the output of the network, they are called hidden neurons (circles). The layer of hidden neurons is called a hidden layer. The outputs of the hidden neurons are recombined via a weighted sum to give the output function f(x).
The next figure shows a simple one-class-classifier, consisting of a single neuron which receives the binary feature vectors of a dog and a cat (i.e. not a dog). The classifier computes the weighted sum of the elements of its inputs. If the result is larger than 0, the vector is classified as a dog, if less than 0, it is not a dog.

In theory, a simple Neural Network with arbitrarily many hidden neurons can approximate any mathematical function under some mild assumptions (see universal approximation theorem). In recent years it has been shown in practice to be much more beneficial to make Neural Networks deeper, i.e. feed the output of a hidden layer into another hidden layer, into another hidden layer, into another hidden layer and so on and so forth. There are some technical intricacies to consider when going deep, which is why for this branch the term Deep Learning has established itself, almost as if DL was a separate discipline. Technically though, it is nothing more than the lavish little brother of regular ML.
TL;DR: Deep Learning is sub-field of Machine Learning is sub-field of Artificial Intelligence.
Computer Vision - from data to information
In Computer Vision (CV), researchers try to get computers to "understand" what they see in an image and then act according to or simply share this information with a human user. Deep Neural Networks have established themselves as one of the most popular tools to perform CV. This is significantly due to the invention of Convolutional Neural Networks (CNN). This term is equally ubiquitous as Deep Learning. CNNs are basically Deep Neural Networks, however the synapses are modified out-of-the-box to mimic the brain's mechanism for vision. This modification is fundamentally nothing but taking a fully connected layer of neurons, cutting a significant number of connections and arranging the remaining ones in such a way that they have no choice but learning to localize specific shapes in an image. Several of these convolutions in consecutive layers of the Deep Neural Network will learn increasingly complex shapes. The first layer might learn to detect edges, the second might combine two edges to detect angles, the third layer combines a few angles to get a square and so on. For a great article visualizing the increasingly complex features at different layers, click here.
Deep Learning algorithms used for Computer Vision vary both in mechanism and in the extracted information, as we will discuss now
TL;DR: Convolutional Neural Networks are a specific type of Deep Neural Network used for Computer Vision. Computer Vision is the science of making computers "understand" what they see.
Classification
One of the first tasks Machine Learning algorithms became really good at was classification of images into different categories. This means the algorithm is presented a photo and has to produce a class label as an output, i.e. declare the image to show a dog or a cat or the number three (see the next figure). More advanced problems are the classification of skin cancers or diagnosing based on X-ray images. Both these fields are researched actively.

The classification task is usually broken down into two steps. First, convolutional layers learn to extract relevant features for the task, e.g. different shapes of eyes, noses, etc., and then a classifier decides for "Dog" / "Cat" / "Person". This classifier could be a simple Neural Network or another ML algorithm.
As many features are to some degree re-usable for different tasks, it has been shown that so-called transfer learning is quite helpful. Transfer learning describes the practice of simply taking the convolutional layers of a Deep Neural Network which was trained on another task (e.g. classifying flowers) and using them for a new task by fine-tuning the weights for the specific job at hand (e.g. classifying animals). In many scenarios this significantly speeds up the rather expansive training process.
TL;DR: In classification tasks the entire image is assigned to a class, which is associated with a particular label. Re-using layers from pre-trained Neural Networks can help quite a bit.
Semantic segmentation
Another task where Deep Learning regularly outperforms more traditional approaches is semantic segmentation. Semantic segmentation is the task of classifying each pixel in an image. This is a very difficult job, as the context of the pixel in the image needs to be considered. The Deep Neural Networks used here typically consist exclusively of convolutional layers (see U-Net). The output comes in form of a copy of the image, where different structures and objects are color-coded accordingly:

Applications of semantic segmentation are localization of anomalies in medical images, localization of clouds and solar panel visualization.
In the figure above, the cloud is masked with blue, the two people red and yellow is the background. Performing this type of segmentation gives the most depth of information and is appropriate in scenarios where computation times of several seconds and more are acceptable. In time-critical applications one has to sacrifice some of the information for speed, which brings us to object detection.
TL;DR: Semantic segmentation algorithms classify every pixel in an image, which is why they deliver the most information. Computation time might be critical though.
Object detection
Object detection is an alternative to semantic segmentation, if a rough localization needs to be performed fast. This is why these algorithms are used e.g. in video analysis and self-driving cars.

As seen in the figure above, the information is usually displayed by drawing bounding boxes around detected objects. There are various algorithms to do this (Faster-RCNN, YOLO, SSD). Roughly summarized, these algorithms propose many regions of the image and give them scores quantifying the membership in given classes. The resulting output of the network consists of a box marking the region and e.g. the class with the highest score. In the cartoon above the red boxes would be classified as "Person", while the green box would be classified as "Cloud".
TL;DR: Object detection identifies bounding boxes around objects and classifies them. The depth of information is lower than with segmentation, but the algorithms are fast enough for real-time application.
Sounds good! Where is the catch?
Almost every day we hear success stories of Deep Learning. To contextualize and give a realistic estimation of DL's potential, it might be worth pointing out some of the issues in the field, but also how researchers are attempting to over-come them.
Training data
The main bottleneck in the Deep Learning development pipeline is the acquisition of training data. All algorithms described above depend heavily on the access to large quantities of example inputs, where labels of the correct answer are already known (that is, all algorithms fall under the supervised learning paradigm). In some cases the labels come with the training data automatically, e.g. in time-series forecasting or in some applications, where the data can be labeled easily via clustering. In most cases of interest, however, the labels need to be added by an expert. Often this can be done by entry-level employees in a short phase of tedious busy-work, while the costs scale quite well with the expected increase in productivity. In other cases, labeling requires a high level of specialization. This is one of the problems hindering DL's progress in e.g. medical imaging, as the labeling would need to be done by highly-trained medical professionals.
The shortage of data in the medical sector is emblematic for the second problem with data acquisition: certain data is subject to quite rigorous data protection legislation, and is therefore unavailable or "anonymized beyond utility" for certain tasks.
Recently, there have been successful attempts to use generative Machine Learning to recombine and shuffle data properties to create new labeled training data from scratch. Models trained with artificial training data have shown increased performance.
TL;DR: Training data might be hard to get, that is why researchers are developing generative models to artificially increase the number of available examples.
Workflow integration and ethics
Technically not part of Deep Learning-research per se, yet another important question is the one of integrating DL models in the end user's workflow. In many jobs that Deep Learning is supposed to support, the respective employee might not have the required IT training or computers might not (yet) be part of their toolbox. Some questions to consider then are which devices are available and also capable of running DL and CV models (smartphones, digital cameras, etc.) and how would the user interface with the information provided by the algorithms (see augmented reality / virtual reality).
Once Deep Learning is part of the workflow, questions of responsibility arise. Who is responsible for mistakes and damages caused by AI? To this day Neural Networks are black boxes, where the developers have little to no knowledge of the inner workings. Making Neural Networks explainable is a very active area of research at the moment and some useful results to explain the decision process of a Neural Network have been published, however, most of them deliver measures of relevance, rather than causal relations. This is generally perceived as unsatisfactory.
TL;DR: Integration of Deep Learning into day-to-day life requires clever design choices. Once integrated, questions of responsibility need to be sorted out due to lack of explainability of Deep Learning-models.
I hope this post has clarified some of the terminology and has given you a broad overview of Deep Learning and Computer Vision.
Contact
If you would like to speak with us about this topic, please reach out and we will schedule an introductory meeting right away.