
Was ist KI?

In den letzten fünf bis zehn Jahren hat kaum ein Thema einen so rasanten Anstieg der Popularität erlebt wie Deep Learning. Seit 2009 hat sich die Anzahl der jährlich veröffentlichten Deep Learning-Forschungsbeiträge mehr als verdoppelt. Es scheint, dass jeder über KI spricht und jedes Technologieunternehmen tiefe neuronale Netze für sein neuestes Produkt verwendet. Die Begriffe Künstliche Intelligenz (KI), Machine Learning (ML) und Deep Learning (DL) werden mit erstaunlicher Häufigkeit verwendet. Es ist jedoch nicht offensichtlich, was sie beschreiben sollen und wie sie sich zueinander verhalten. Dieser Blog-Artikel soll einige der in diesen Bereichen verwendeten Begriffe für den technikbegeisterten Laien erläutern und eine Vorstellung davon vermitteln, wie diese Technologien in der Computer Vision (CV) eingesetzt werden können.
Künstliche Intelligenz und Deep Learning
Bis heute ist eine allgemein akzeptierte Definition von Intelligenz noch nicht gegeben. Die meisten Menschen würden es als die Fähigkeit beschreiben, logisch zu denken, vernünftig zu denken oder komplexe Probleme selbstständig zu lösen. Entsprechend ist die Definition von KI auch etwas unscharf. Es gibt eine Vielzahl von assoziierten Bereichen, die von der Robotik über den automatisierten Theoremnachweis (ATP) bis hin zu generativen Modellen reichen. Der wichtigste Teilbereich ist jedoch das Machine Learning. Die folgende Abbildung zeigt die Beziehung der Begriffe in schematischer Form.
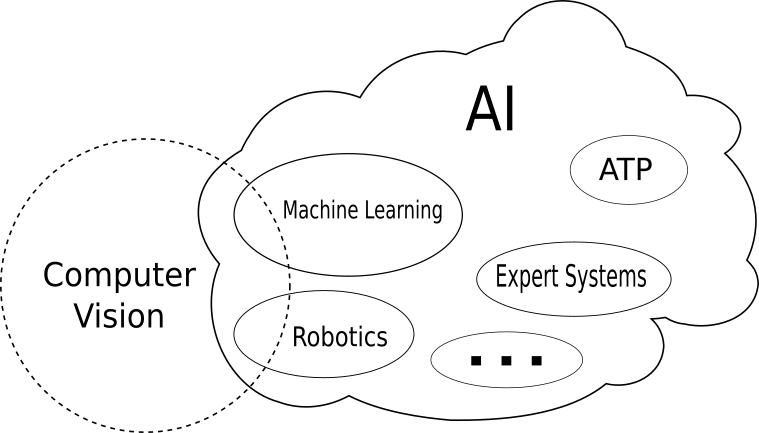
Machine Learning ist die Disziplin, in der Computer an einer Vielzahl von Beispielen lernen bestimmte Aufgaben zu lösen. Die Einsatzmöglichkeiten reichen von der Textanalyse bis zur Arzneimittelentwicklung. Es gibt eine ganze Reihe von Algorithmen, die unter dem Oberbegriff Machine Learning zusammengefasst sind.
Neben Support Vector Machines (SVM) und Decision Trees sind neuronale Netze die vielversprechendsten Werkzeuge im ML. Sie sind unglaublich leistungsstarke Funktionenapproximierer und haben bei verschiedenen Klassifizierungs-, Regressions- und Kontrollaufgaben eine vergleichbare oder sogar bessere Leistung gezeigt. Die folgende Abbildung veranschaulicht den Zusammenhang von Machine Learning und seinen Methoden.

Neuronale Netze sind ein biologisch inspirierter Algorithmus, bei dem die gewichtete Summe aller Eingaben durch eine nichtlineare Funktion geleitet wird. Die Gewichte der Summe können als synaptische Verbindungen betrachtet werden, während die nichtlineare Funktion die Reaktion eines Neurons auf einen Stimulus nachahmt. Im einfachen neuronalen Netzwerk in der obigen Abbildung wird der Eingangsvektor x an eine einzelne Schicht von Neuronen übergeben. Da diese Neuronen weder Eingang noch Ausgang des Netzwerks sind, werden sie als hidden neurons (circles) bezeichnet. Die Schicht der hidden neurons wird als hidden layer bezeichnet. Die Ausgänge der hidden neurons werden über eine gewichtete Summe zu der Ausgabefunktion f(x) neu kombiniert.
Die nächste Abbildung zeigt einen einfachen Einklassenklassifizierer, bestehend aus einem einzelnen Neuron, das die binären Feature-Vektoren eines Hundes und einer Katze (d.h. keinen Hund) empfängt. Der Klassifikator berechnet die gewichtete Summe der Elemente seiner Eingänge. Wenn das Ergebnis größer als 0 ist, wird der Vektor als Hund klassifiziert, wenn weniger als 0, ist es kein Hund.

Theoretisch kann ein einfaches neuronales Netzwerk mit beliebig vielen hidden neurons unter milden zusätzlichen Annahmen jede mathematische Funktion approximieren (siehe Universeller Approximationssatz). In den letzten Jahren hat sich in der Praxis gezeigt, dass es viel vorteilhafter ist, neuronale Netze tiefer zu machen, d.h. die Ausgabe eines hidden layers in ein weiters hidden layer und so weiter und so fort einzuspeisen. Es gibt einige technische Feinheiten zu beachten, wenn man in die Tiefe geht, weshalb sich für diesen Bereich der Begriff Deep Learning etabliert hat, fast so, als wäre DL eine eigenständige Disziplin. Technisch gesehen ist es aber nichts anderes als der kleine Bruder des üblichen ML.
TL;DR: Deep Learning ist Teilbereich des Machine Learning ist Teilbereich der Künstlichen Intelligenz.
Computer Vision - von den Daten zur Information
In dem Bereich Computer Vision (CV) versuchen Forscher, Computer dazu zu bringen, das, was sie in einem Bild sehen, zu "verstehen" und dann entsprechend zu handeln oder diese Informationen einfach mit einem menschlichen Benutzer zu teilen. Deep Neural Networks haben sich als eines der beliebtesten Werkzeuge zur Durchführung von CV etabliert. Dies ist wesentlich auf die Erfindung der Convolutional Neural Networks (CNN) zurückzuführen. Dieser Begriff ist ebenso allgegenwärtig wie Deep Learning. CNNs sind im Grunde genommen Deep Neural Networks, aber die Synapsen werden modifiziert, um den Mechanismus des Gehirns für das Sehen nachzuahmen. Diese Modifikation ist im Grunde nichts anderes, als eine vollständig verbundene Schicht von Neuronen zu nehmen, eine beträchtliche Anzahl von Verbindungen zu trennen und die restlichen so anzuordnen, dass sie keine andere Wahl haben, als zu lernen, bestimmte Formen in einem Bild zu lokalisieren. Mehrere dieser Typen von Verbindungen in aufeinanderfolgenden Schichten des Deep Neural Network werden immer komplexere Formen lernen. Die erste Schicht könnte lernen, Kanten zu erkennen, die zweite könnte zwei Kanten kombinieren, um Winkel zu erfassen, die dritte Schicht kombiniert einige Winkel, um ein Quadrat zu erhalten und so weiter. Für einen großartigen Artikel, der die immer komplexeren Funktionen auf verschiedenen Ebenen visualisiert, klicken Sie hier.
Deep Learning Algorithmen, die für Computer Vision verwendet werden, variieren sowohl im Mechanismus als auch in den extrahierten Informationen, wie wir jetzt diskutieren werden.
TL;DR: Convolutional Neural Networks sind eine spezielle Art von Deep Neural Network, das für Computer Vision verwendet wird. Computer Vision ist die Wissenschaft, die Computer dazu bringt, das zu "verstehen", was sie sehen.
Klassifizierung
Eine der ersten Aufgaben, bei denen die Algorithmen des Machine Learning wirklich gut wurden, war die Klassifizierung von Bildern in verschiedene Kategorien. Das bedeutet, dass der Algorithmus ein Foto präsentiert bekommt und als Ausgabe ein Klassenlabel erzeugen muss, d.h. das Bild für einen Hund oder eine Katze oder die Nummer drei deklarieren muss (siehe nächste Abbildung). Fortgeschrittenere Probleme sind die Klassifizierung von Hautkrebs oder die Diagnose anhand von Röntgenbildern. Beide Bereiche werden aktiv erforscht.

Die Klassifikationsaufgabe wird in der Regel in zwei Schritte unterteilt. Zuerst lernen die Convolutional Layers, relevante Merkmale für die Aufgabe zu extrahieren, z.B. verschiedene Formen von Augen, Nasen usw., und dann entscheidet sich ein Klassifizierer für "Hund". / "Katze" / "Person". Dieser Klassifikator kann ein einfaches Neuronales Netzwerk oder ein anderer ML-Algorithmus sein.
Da viele Features für verschiedene Aufgaben teilweise wiederverwendbar sind, hat sich gezeigt, dass das sogenannte Transferlernen sehr hilfreich ist. Transferlernen beschreibt die Praxis, die Convolutional Layers eines Deep Neural Networks, das für eine andere Aufgabe (z.B. Klassifizieren von Blumen) trainiert wurde, einfach zu nehmen und für eine neue Aufgabe zu verwenden, indem die Gewichte auf die jeweilige Aufgabe abgestimmt werden (z.B. Klassifizieren von Tieren). In vielen Szenarien beschleunigt dies den recht aufwendigen Trainingsprozess erheblich.
TL;DR: Bei Klassifizierungsaufgaben wird das gesamte Bild einer Klasse zugeordnet, die mit einem bestimmten Label verbunden ist. Die Wiederverwendung von Schichten aus vortrainierten neuronalen Netzen kann sehr hilfreich sein.
Semantische Segmentierung
Eine weitere Aufgabe, bei der Deep Learning regelmäßig mehr als herkömmliche Ansätze leistet, ist die semantische Segmentierung. Semantische Segmentierung ist die Aufgabe, jedes Pixel in einem Bild zu klassifizieren. Dies ist eine sehr schwierige Aufgabe, da der Kontext des Pixels im Bild berücksichtigt werden muss. Die hier verwendeten Deep Neural Networks bestehen typischerweise ausschließlich aus Convolutional Layers (siehe U-Net). Die Ausgabe erfolgt in Form einer Kopie des Bildes, wobei verschiedene Strukturen und Objekte entsprechend farblich gekennzeichnet sind:

Anwendungen der semantischen Segmentierung sind die Lokalisierung von Anomalien in medizinischen Bildern, die Lokalisierung von Wolken und die Visualisierung von Solarpanels. Bleiben Sie auf dem Laufenden mit dem dida-Blog!
In der obigen Abbildung ist die Wolke mit blau maskiert, die beiden Personen rot und gelb ist der Hintergrund. Die Durchführung dieser Art der Segmentierung bietet die größte Informationstiefe und ist in Szenarien sinnvoll, in denen Rechenzeiten von mehreren Sekunden und mehr akzeptabel sind. In zeitkritischen Anwendungen muss man einen Teil der Informationen für die Geschwindigkeit opfern, was uns zur Objekterkennung führt.
TL;DR: Semantische Segmentierungsalgorithmen klassifizieren jedes Pixel in einem Bild, weshalb sie die meisten Informationen liefern. Die Rechenzeit kann jedoch kritisch sein.
Objekterkennung
Die Objekterkennung ist eine Alternative zur semantischen Segmentierung, wenn eine grobe Lokalisierung schnell durchgeführt werden soll. Deshalb werden diese Algorithmen z.B. in der Videoanalyse und in selbstfahrenden Autos eingesetzt.

Wie in der obigen Abbildung zu sehen ist, werden die Informationen in der Regel durch das Zeichnen von Rahmen um erkannte Objekte angezeigt. Dazu gibt es verschiedene Algorithmen (Schneller-RCNN, YOLO, SSD). Grob zusammengefasst, schlagen diese Algorithmen viele Regionen des Bildes vor und geben ihnen Scores, die die Zugehörigkeit zu bestimmten Klassen quantifizieren. Die resultierende Ausgabe des Netzwerks besteht aus einer Box, die die Region und z.B. die Klasse mit dem höchsten Score markiert. In der obigen Zeichnung wird das rote Kästchen als "Person" klassifiziert, während das grüne Kästchen als "Cloud" klassifiziert wird.
TL;DR: Die Objekterkennung identifiziert Begrenzungsrahmen um Objekte und klassifiziert sie. Die Informationstiefe ist geringer als bei der Segmentierung, aber die Algorithmen sind schnell genug für eine Echtzeitanwendung.
Klingt gut! Wo ist der Haken?
Fast jeden Tag hören wir Erfolgsgeschichten von Deep Learning. Um das Potenzial von DL zu kontextualisieren und realistisch einzuschätzen, könnte es sich lohnen, einige der Probleme in diesem Bereich aufzuzeigen, aber auch, wie Forscher versuchen, sie zu überwältigen.
Trainingsdaten
Der Hauptengpass in der Entwicklungspipeline von Deep Learning ist die Erfassung von Trainingsdaten. Alle oben beschriebenen Algorithmen hängen stark vom Zugriff auf große Mengen von Beispieleingaben ab, bei denen die Bezeichnungen der richtigen Antwort bereits bekannt sind (d.h. alle Algorithmen fallen unter das überwachte Lernparadigma). In einigen Fällen kommen die Labels automatisch mit den Trainingsdaten, z.B. bei der Zeitreihenprognose oder in einigen Anwendungen, wo die Daten über Clustering einfach beschriftet werden können. In den meisten Fällen von Interesse müssen die Labels jedoch von einem Experten angebracht werden. Oftmals kann dies von Einsteigern in einer kurzen Phase mühsamer Arbeit getan werden, während die Kosten mit der erwarteten Produktivitätssteigerung recht gut skalieren. In anderen Fällen erfordert die Kennzeichnung einen hohen Spezialisierungsgrad. Dies ist eines der Probleme, die den Fortschritt von DL z.B. in der medizinischen Bildgebung behindern, da die Kennzeichnung von hochqualifiziertem medizinischem Personal durchgeführt werden müsste.
Der Datenmangel im medizinischen Bereich ist emblematisch für das zweite Problem der Datenerfassung: Bestimmte Daten unterliegen einer sehr strengen Datenschutzgesetzgebung und sind daher für bestimmte Aufgaben nicht verfügbar oder "bis zur Unbrauchbarkeit anonymisiert".
In letzter Zeit gibt es erfolgreiche Versuche, mit generativem Machine Learning Dateneigenschaften neu zu kombinieren und zu mischen, um neue, markierte Trainingsdaten von Grund auf neu zu erstellen. Modelle, die mit künstlichen Trainingsdaten trainiert wurden, haben eine höhere Leistung gezeigt.
TL;DR: Trainingsdaten sind oft schwer zu bekommen, deshalb entwickeln Forscher generative Modelle, um die Anzahl der verfügbaren Beispiele künstlich zu erhöhen.
Workflow-Integration und Ethik
Technisch gesehen nicht Teil der Deep Learning-Forschung an sich, ist eine weitere wichtige Frage die der Integration von DL-Modellen in den Workflow des Endbenutzers. In vielen Jobs, die Deep Learning unterstützen soll, verfügt der jeweilige Mitarbeiter möglicherweise nicht über die erforderliche IT-Schulung oder Computer sind (noch) nicht Teil seiner Toolbox. Einige zu berücksichtigende Fragen sind dann, welche Geräte verfügbar sind und auch in der Lage sind, DL- und CV-Modelle (Smartphones, Digitalkameras usw.) zu betreiben, und wie sich die Benutzeroberfläche mit den Informationen der Algorithmen verbinden würde (siehe Augmented Reality / Virtual Reality).
Sobald Deep Learning Teil des Workflows ist, stellen sich Fragen der Verantwortung. Wer ist verantwortlich für Fehler und Schäden, die durch die KI verursacht werden? Neuronale Netze sind bis heute Blackboxen, in denen die Entwickler wenig bis gar kein Wissen über das Innenleben haben. Die Erklärbarkeit neuronaler Netze ist derzeit ein sehr aktives Forschungsgebiet, und einige nützliche Ergebnisse zur Erklärung des Entscheidungsprozesses eines neuronalen Netzes wurden veröffentlicht, die meisten von ihnen liefern jedoch eher relevante Messungen als kausale Zusammenhänge. Dies wird allgemein als unbefriedigend empfunden.
TL;DR: Die Integration von Deep Learning in den Alltag erfordert clevere Designentscheidungen. Einmal integriert, müssen rechtliche und ethische Fragen aufgrund mangelnder Erklärbarkeit von Deep Learning-Modellen gelöst werden.
Ich hoffe, dass dieser Beitrag einige der Begriffe geklärt hat und Ihnen einen breiten Überblick über Deep Learning und Computer Vision gegeben hat.
Kontakt
Wenn Sie mit uns über dieses Thema sprechen möchten, kontaktieren Sie uns gerne und wir melden uns im Anschluss für ein unverbindliches Erstgespräch.