
Recommendation systems - an overview

Recommendation systems are everywhere. We use them to buy clothes, find restaurants and choose which TV show to watch. In this blog post, I will give an overview of the underlying basic concepts, common use cases and discuss some limitations. This is the first of a series of articles about recommendation engines. Stay tuned for the follow-ups, where we will explore some of the mentioned concepts in much more detail!
Already in 2010, 60 % of watch time on Youtube came from recommendations [1] and personalized recommendations are said to increase conversion rates on e-commerce sites by up to 5 times [2]. It is safe to say that if customers are presented with a nice pre-selection of products they will be less overwhelmed, more likely to consume something and have an overall better experience on the website. But how do recommendation engines work? Let's dive right in.
Terminology
We first clarify a few terms, which often pop up in the context of recommendation engines.
Users, items and queries
What all recommendation systems have in common, is that they are designed to model interactions between users and items (or documents). Users are simply the people using the particular service while items can be products in an online store, content on a streaming platform or posts on social media. Viewed as an end-to-end system, recommendation engines should simply provide customized recommendations in response to a query. This query can contain information about the user and how the user interacted with other items previously, but also additional context like the time of the day or the device the user is using may also be included.
Depending on the contents of a query, a recommendation system can aim to answer different kinds of questions:
Query contents |
Implicit question asked |
Recommendation system return |
User-item pair |
How relevant is this item to this user? |
The probability, that the item is relevant or the predicted rating. |
User |
Which items are the most relevant to this user? |
A set of items. ("You might like", "Recommended for you") |
Item |
Which items are similar to this item? |
A set of items. ("Because you watched X", "Frequently bought together") |
The first row of this table corresponds to formulating recommendation systems as a prediction problem, while the other two rows frame it as a ranking problem. By predicting all possible interactions between users and items it becomes trivial to also rank them. However, it is not necessary to do this and may even be infeasible with large corpora of items.
If you want to include a recommendation engine in your website, it might make sense to provide different recommendations at different places. On the start page general recommendations based on past user behaviour are well placed, while on the checkout page a selection of items which supplement the ones in your cart.
The pieces of a recommendation system
Viewed as an end-to-end system, the goal of a recommendation system is simply to put out the most relevant items to a given query. But in particular when there is a large pool of items available, it makes sense to split this process into 3 steps:
Candidate Generation: A first selection of potentially relevant items is selected. From the ML perspective, this is the most interesting part.
Scoring: After candidates are generated, another model is used to score the generated candidates, to ultimately select the ones to display. Since the amount of items is now multiple orders of magnitude smaller, the model can be much more sophisticated and use more features about the items. Also by using a separate model for scoring it is easy to combine multiple candidate generation models.
Re-ranking: In this optional final stage, candidates are re-ranked to also incorporate additional constraints or criteria. This often happens rule-based and examples include:
put emphasis on newer items
filter out items which the user explicitly disliked
include popular or trending items

Broadly speaking, candidate generation can be achieved using these two methods (or a combination thereof): Content-based filtering and collaborative filtering
Collaborative filtering
The goal of a collaborative filtering system is to infer how a user might interact with some item based on how other users with similar tastes interacted with this item. In particular, interactions of other users are taken into account to produce recommendations. Naively put: if you like Movie A and B and the majority of other users who like Movie A and B also like Movie C, you are likely to like movie C as well. When thinking about collaborative filtering, one mostly thinks of a user-item matrix and of clever ways to factorize this matrix. This idea naturally leads to embeddings of users and items - check out the upcoming blog post about collaborative filtering where I'll cover these concepts thoroughly.
An advantage of this technique is, that in principle one does not need to know anything about the users and items, just how users interacted with items.
The main disadvantage is, that collaborative filtering suffers heavily from the cold start problem - it is hardly possible to make recommendations to a new user or about a new item, which was not rated yet.
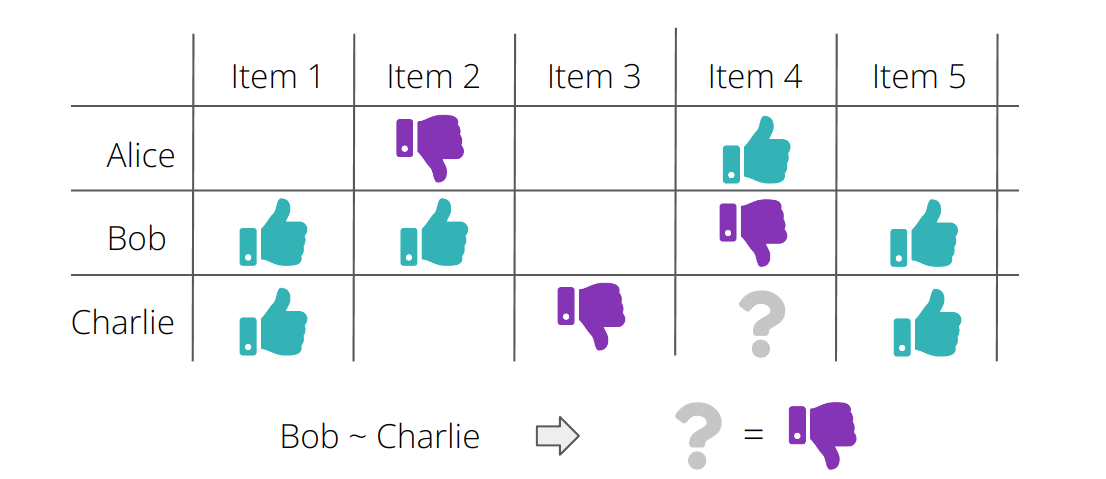
Stay tuned for the blog post about collaborative filtering to learn more!
Content-based filtering
In contrast, content-based filtering uses features of items to recommend items which are similar to those a user liked in the past. These features may be very explicit, like genre or duration of a movie, but also more complex features can be extracted from data which is available about the item.
The advantage of this method is that it does not require other users' data to make recommendations to a single user. Further, it is well suited to capture the specific interests of single users and recommend niche items which are not relevant to the vast majority of users.
However, this type of system generally still struggles with new users if there is not enough information about what these users like. Another disadvantage is that by design content-based recommenders will only recommend items which are similar to the ones the users already consume. In this sense, it is not well suited for "broadening the horizons" of its users and recommending "new" items.

Stay tuned for the blog article about content-based filtering, where I will cover the concept in much more detail.
Hybrid systems
Because content-based and collaborative systems partly have complementary strengths and weaknesses, most systems for candidate generation rely on a mixture of both. In fact, the most effective recommendation engines rely on an ensemble of many different systems!
Data collection
A machine learning system can only be as good as the data it was trained on.
While the data about the items is mostly given (e.g. through product descriptions, plot summaries, tags etc.), data about users first needs to be collected. This can happen explicitly or implicitly: Explicit data is gathered from user inputs like reviews, ratings or likes. In contrast, implicitly collected data may include the search history, time spend watching videos of a certain category or even more abstract behavior on the web. A major challenge, especially with implicit data collection, is that an observed interaction of a user with an item does not necessarily mean that the user liked this item. Consider the following example:
A while ago, a friend sent me a dog video on Instagram. I watched it, and even though I did not leave a like or a comment my feed was full of dog videos for the next days. It took a conscious effort of quickly skipping these videos to make the algorithm understand that I am not interested in them since many social media networks don't offer the possibility to provide negative feedback.
Use Cases
A recommendation engine can be applied whenever it is possible to frame a business case with a notion of users and items. Here I will give a non-exhaustive list of possible scenarios:
E-Commerce websites - perhaps the most obvious one. Offering personalized recommendations to a customer visiting the website and showing products which are similar to the ones he is looking at at the moment increases the chance that he will buy something.
Streaming services - Youtube, Netflix, Spotify - all let you discover new content by offering personalized recommendations. I have actually discovered some really cool bands by just listening to the Spotify radio based on things I like!
News content - Being presented with news articles which might interest you can be convenient, but also can be dangerous as it leads to the emergence of so-called filter bubbles. More on that in the section on Challenges
Blogs - If you are reading this article on medium, it's probably because it was recommended to you. :)
Dating apps - It is obviously wrong to call possible matches "items" in this case, but also this use case fits the paradigm of recommendation systems.
Job portals - It saves a lot of struggle if irrelevant job offers are filtered out.
Spam filtering - This differs a bit from the other cases as (hopefully) most items are relevant, but can also be handled by a recommendation system.
Personalized advertising.
And more!
Having this many use cases, recommendation engines are of course not almighty and face some more or less serious challenges.
Challenges
The cold start problem
If a new user presents himself to a recommendation system, it is virtually impossible to provide him with customized recommendations. This is known as the cold start problem. One way to remedy this is to explicitly ask the user what kind of items he is interested in, for example by presenting him with a few items and asking if they are relevant or not. Another, maybe more pragmatic approach, is to just recommend the most popular items.
Long tail
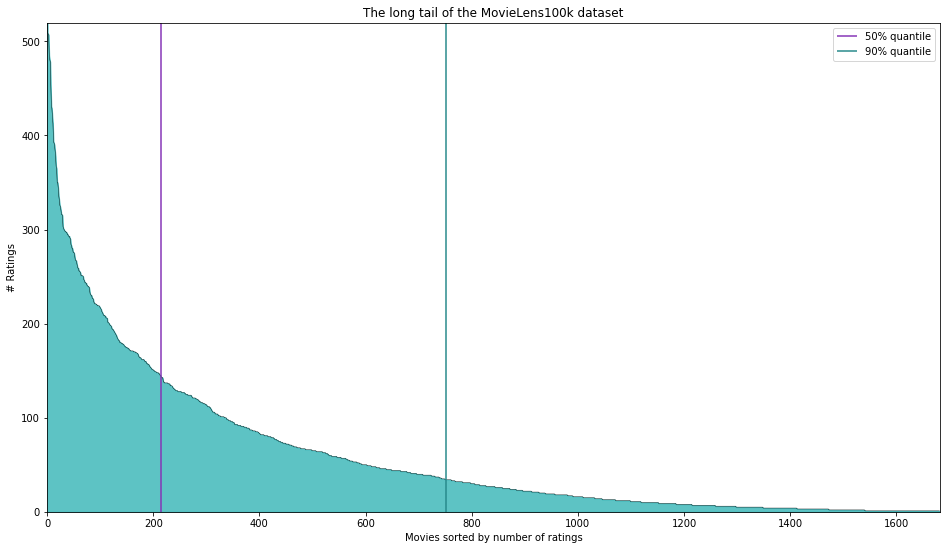
Another common problem with recommendation systems is that mostly only very few items have a decent amount of ratings/interactions. These so-called popular items can end up dominating the recommendations, while less popular items do not get recommended a lot. This is known as the long tail problem and is more prevalent in collaborative methods than in their content-based counterparts.
In the following figure, this is illustrated by the famous MovieLens100k dataset. It consists of 100.000 user-movie ratings from 943 users on 1682 movies. However, 50% of the ratings are concentrated on 214 movies (12.7% of all movies) and 90% of the ratings are concentrated on 751 movies (44.7% of all movies). Hence, the majority of movies have very few ratings and it is difficult to make meaningful recommendations about those rarely rated movies!
Scalability
Scaling recommendation systems to millions of users and items can quickly become infeasible, as it requires ever larger amounts of computing power. Some tech giants are lucky enough to have this power at their disposal, but even then providing real-time recommendations can be tricky. In this extreme setting, a reasonable strategy is to artificially lower the number of items by only considering those belonging to certain categories or even to sample items randomly in a first stage of candidate generation. Also, recommendations can be precomputed and saved somewhere, such that they are ready to be presented to the user when he logs in the next time.
Evaluating recommendation systems
Another challenge is the evaluation of recommendation systems. From a machine learning perspective one might come up with metrics for offline evaluation (offline evaluation, in this case, means using a fixed observed dataset from the past), however, these evaluations often do not tell the whole story. Note for example, that it is not possible to know how a user would have behaved if he was shown different recommendations. Further, being too correct can lead to users losing interest in the recommendations. An example of being too correct would be to only recommend movies the user was about to watch anyway. Say, you just watched Star Wars episodes 4 and 5 and the only recommendation is episode 6. This is surely a relevant recommendation, but it is not really valuable. In fact, good recommendations should not only be relevant but also novel and diverse at the same time.
Ultimately, the success of recommendation systems is often measured via A/B testing and analyzing some underlying business metrics, e.g. click rates and watch time in the case of a video streaming service or purchases in the case of an online shop. Interestingly, as the researchers in [3] point out, the results of the A/B tests do not necessarily correlate with prior offline evaluations! This makes it extremely difficult to judge the performance of a recommendation system before putting it to the test.
Self-fulfilling prophecy?
If you end up consuming mostly the content that was recommended to you, is it because the recommendations were on point or simply because it is easier to click on content that is already there than to actively search for new content? Researchers have criticized the emergence of so-called filter bubbles, most famously in the context of news feeds of social media platforms like Twitter or Facebook. Especially in this setting, it is therefore crucial to ensure novelty and diversity in the recommendations. But also for an online shop it might be beneficial to recommend some unexpected items from time to time - if the user ends up liking them, it is a full success for the recommendation system and if not, the recommendation system has the chance to get smarter once again.
Conclusion
In this article, we have
provided an overview of recommendation systems and seen that they are more relevant than ever,
introduced core concepts like collaborative and content-based filtering,
covered some basic use cases,
discussed challenges and limitations of recommendation engines.
This high-level overview is just the first of a series of articles about recommendation engines. Check out our article about collaborative filtering, if you want to dive into the details of this technique! If you want to dive into the details of various other machine learning subtopics to successfully realize your project, feel free to book a Tech Lunch with us!
Resources and further reading
[1] "The Youtube Video Recommendation System", Davidson et. al, 2010
[2] https://aws.amazon.com/personalize/
[3] "Deep Neural Networks for YouTube Recommendations", Covington et. al 2017
A good (slightly technical) overview of recommenders by Google.
Contact
If you would like to speak with us about this topic, please reach out and we will schedule an introductory meeting right away.