
Empfehlungssysteme - Ein Überblick

Empfehlungssysteme (engl. recommendation systems) sind überall. Wir verwenden sie, um Kleidung zu kaufen, Restaurants zu finden und lassen uns von Ihnen Fernsehsendungen empfehlen. In diesem Blogartikel gebe ich einen Überblick über die zugrundeliegenden Konzepte, häufige Anwendungsfälle und diskutiere einige Einschränkungen. Dies ist der erste Teil einer Reihe von Artikeln über Empfehlungssysteme. Bleiben Sie dran für die Folgeartikel, in denen wir einige der erwähnten Konzepte noch ausführlicher behandeln werden!
Bereits im Jahr 2010 kamen 60 % der Zeit, die auf youtube verbracht wird, von Empfehlungen [1]. Außerdem sollen personalisierte Empfehlungen die Konversionsraten auf E-Commerce Webseiten um das bis zu 5-fache erhöhen [2]. Sicher ist, dass Kunden, denen eine gute Vorauswahl an Produkten präsentiert wird, weniger überwältigt sind, eher etwas konsumieren und insgesamt eine bessere Erfahrung auf der Website machen. Aber wie funktionieren Empfehlungsmaschinen?
Terminologie
Zunächst klären wir ein paar Begriffe, die häufig im Zusammenhang mit Empfehlungsmaschinen auftauchen.
Users, items und queries
Allen Empfehlungssystemen ist gemeinsam, dass sie auf die Modellierung von Interaktionen zwischen Nutzern (engl. users) und Objekten (engl. items) ausgelegt sind. Nutzer sind Personen, die den jeweiligen Dienst nutzen, während Items Produkte in einem Online-Shop, Inhalte auf einer Streaming-Plattform oder Beiträge in sozialen Medien sein können. Als End-to-End-System betrachtet, sollten Empfehlungsmaschinen einfach maßgeschneiderte Empfehlungen als Antwort auf eine Anfrage (engl. query) liefern. Diese Abfrage kann Informationen über den Nutzer enthalten und darüber, wie er zuvor mit anderen Elementen interagiert hat, aber auch zusätzlichen Kontext wie die Tageszeit oder das Gerät, das der Nutzer verwendet.
Je nach dem Inhalt einer Anfrage kann ein Empfehlungssystem darauf abzielen, verschiedene Arten von Fragen zu beantworten:
Inhalt der Anfrage |
Implizit gestellte Frage |
Ausgabe des Empfehlungssystems |
Nutzer-Item Paar |
Wie relevant ist dieses Item für den Nutzer? |
Die Wahrscheinlichkeit, dass das Item relevant ist oder das vorhergesagte Rating. |
Nutzer |
Welche Items sind am relevantesten für diesen Nutzer? |
Eine Menge von Items. ("Das könnte Ihnen gefallen", "Für Sie empfohlen") |
Item |
Welche Items sind diesem ähnlich? |
Eine Menge von Items. ("Weil Sie X angesehen haben", "Wird häufig zusammen gekauft") |
Die erste Zeile dieser Tabelle entspricht der Formulierung von Empfehlungssystemen als Vorhersage-Problem (engl. prediction problem), während die beiden anderen Zeilen das Problem als Ranking-Problem darstellen. Durch die Vorhersage aller möglichen Interaktionen zwischen Nutzern und Objekten wird es trivial, diese auch zu ranken. Es ist jedoch nicht notwendig, dies zu tun, und kann bei großen Korpora von Artikeln sogar undurchführbar sein.
Wenn Sie eine Empfehlungsmaschine in Ihre Website einbauen wollen, kann es sinnvoll sein, an verschiedenen Stellen unterschiedliche Empfehlungen zu geben. Auf der Startseite sind allgemeine Empfehlungen, die auf dem bisherigen Nutzerverhalten basieren, gut platziert, während auf der Kassenseite eine Auswahl an Artikeln angezeigt wird, die die im Warenkorb befindlichen Artikel ergänzen.
Die Bestandteile eines Empfehlungssystems
Als End-to-End-System betrachtet, besteht das Ziel eines Empfehlungssystems darin, die relevantesten Artikel für eine gegebene Anfrage auszugeben. Insbesondere bei einer großen Anzahl von Artikeln ist es jedoch sinnvoll, diesen Prozess in drei Schritte zu unterteilen:
Generierung von Kandidaten (engl. candidate generation): Es wird eine erste Auswahl von potenziell relevanten Elementen getroffen. Was das maschinelle Lernen angeht, ist dies der interessanteste Teil.
.Wertung (engl. scoring): Nachdem die Kandidaten generiert wurden, wird ein weiteres Modell verwendet, um diese zu bewerten und schließlich diejenigen auszuwählen, die angezeigt werden sollen. Da die Anzahl der Elemente nun um mehrere Größenordnungen geringer ist, kann das Modell viel ausgefeilter sein und mehr Merkmale über die Elemente verwenden. Durch die Verwendung eines separaten Modells für die Bewertung ist es außerdem einfach, mehrere Modelle zur Kandidatengenerierung zu kombinieren.
Neueinstufung (engl. re-ranking): In dieser optionalen letzten Phase werden die Kandidaten neu eingestuft, um auch zusätzliche Einschränkungen oder Kriterien zu berücksichtigen. Dies geschieht häufig auf der Grundlage von Regeln, wie zum Beispiel:
neuere Elemente hervorheben
Herausfiltern von Artikeln, die der Nutzer ausdrücklich nicht mag
Einbeziehung beliebter oder im Trend liegender Artikel

Im Großen und Ganzen kann die Kandidatengenerierung mit diesen beiden Methoden (oder einer Kombination davon) erfolgen: Inhaltsbasierte Filterung (engl. content-based filtering) und kollaborative Filterung (engl. collaborative filtering).
Kollaborative Filterung
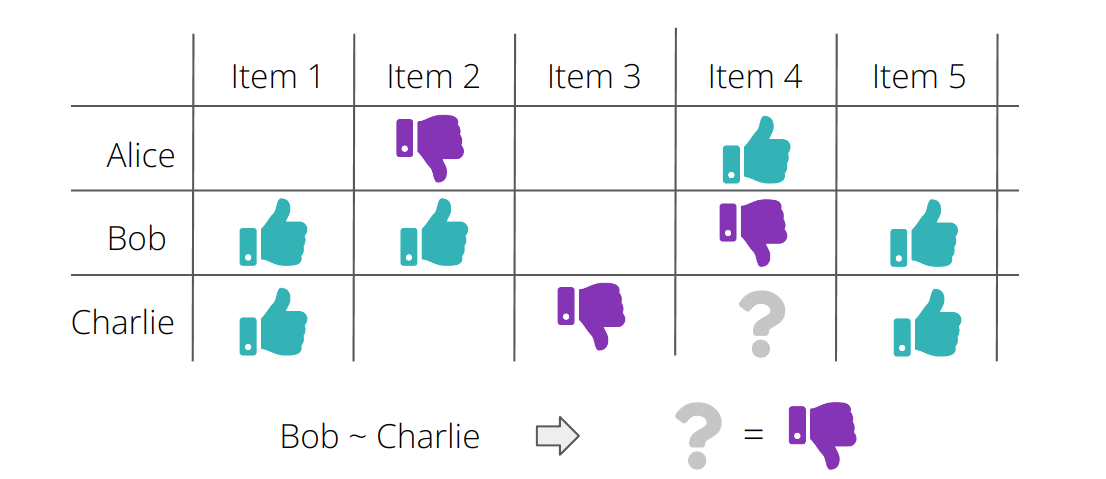
Das Ziel eines kollaborativen Filtersystems ist es, aus der Art und Weise, wie andere Benutzer mit ähnlichem Geschmack mit einem bestimmten Objekt interagiert haben, zu schließen, wie ein Benutzer mit diesem Objekt interagieren könnte. Insbesondere werden die Interaktionen anderer Nutzer bei der Erstellung von Empfehlungen berücksichtigt. Naiv ausgedrückt: Wenn Sie Film A und B mögen und die Mehrheit der anderen Nutzer, die Film A und B mögen, auch Film C mögen, ist es wahrscheinlich, dass auch Sie Film C mögen. Beim kollaborativen Filtern denkt man meist an eine Nutzer-Item-Matrix und an clevere Möglichkeiten, diese Matrix zu faktorisieren. Das führt auf natürliche Art und Weise zu der Idee von Einbettungen (engl. embeddings) - im bald erscheinenden Blogartikel über kollaboratives Filtern erläutere ich detaillert beide Konzepte.
Ein Vorteil dieser Technik ist, dass man im Prinzip nichts über die Nutzer und Items wissen muss, sondern lediglich über ihre Interaktionen.
Der größte Nachteil ist, dass das kollaborative Filtern stark unter dem "cold start"-Problem leidet - es ist kaum möglich, Empfehlungen für einen neuen Benutzer oder über einen neuen Artikel zu geben, der noch nicht bewertet wurde.
In Kürze erscheint ein weiterer Blogeintrag, der das Thema kollaborative Filterung noch wesentlich ausführlicher behandelt.
Inhaltsbasierte Filterung
Im Gegensatz dazu werden bei der inhaltsbasierten Filterung Merkmale von Items verwendet, um Artikel zu empfehlen, die denen ähnlich sind, die einem Nutzer in der Vergangenheit gefallen haben. Diese Merkmale können sehr explizit sein, wie z. B. das Genre oder die Dauer eines Films, aber auch komplexere Merkmale können aus den Daten extrahiert werden, die über das Item verfügbar sind.
Der Vorteil dieser Methode ist, dass sie keine Daten anderer Nutzer benötigt, um einem einzelnen Nutzer Empfehlungen zu geben. Außerdem ist sie gut geeignet, die spezifischen Interessen einzelner Nutzer zu erfassen und Nischenartikel zu empfehlen, die für die große Mehrheit der Nutzer nicht relevant sind.
In der Regel hat jedoch auch dieses System Probleme mit neuen Nutzern, wenn nicht genügend Informationen darüber vorhanden sind, was diese Nutzer mögen. Ein weiterer Nachteil ist, dass inhaltsbasierte Empfehlungssysteme konstruktionsbedingt nur Artikel empfehlen, die denen ähnlich sind, die die Nutzer bereits konsumieren. In diesem Sinne sind sie nicht dazu geeignet, den "Horizont" ihrer Nutzer zu erweitern und "neue" Artikel zu empfehlen.

In Kürze erscheint ein weiterer Blogartikel, in dem ich das Konzept der inhaltsbasierten Filterung noch ausführlicher behandeln werde.
Hybride Systeme
Da inhaltsbasierte und kollaborative Systeme teilweise komplementäre Stärken und Schwächen haben, stützen sich die meisten Systeme zur Kandidatengenerierung auf eine Mischung aus beiden. Tatsächlich beruhen die effektivsten Empfehlungsmaschinen auf einem Ensemble aus vielen verschiedenen Systemen!
Datenerfassung
Ein auf maschinellem Lernen beruhendes System kann nur so gut sein wie die Daten, auf denen es trainiert wurde.
Während die Daten über die Items meist gegeben sind (z. B. durch Produktbeschreibungen, Handlungszusammenfassungen usw.), müssen die Daten über die Nutzer zunächst gesammelt werden. Dies kann explizit oder implizit geschehen: Explizite Daten werden aus Nutzereingaben wie Rezensionen, Bewertungen oder Likes gesammelt. Im Gegensatz dazu können implizit erhobene Daten den Suchverlauf, die Zeit, die mit dem Ansehen von Videos einer bestimmten Kategorie verbracht wird, oder anderes Verhalten im Netz umfassen. Eine große Herausforderung, insbesondere bei der impliziten Datenerfassung, besteht darin, dass eine beobachtete Interaktion eines Benutzers mit einem Gegenstand nicht unbedingt bedeutet, dass der Benutzer diesen Gegenstand mochte. Betrachten Sie das folgende Beispiel:
Vor einiger Zeit schickte mir ein Freund ein Hundevideo auf Instagram. Ich schaute es mir an, und obwohl ich weder ein Like noch einen Kommentar hinterließ, war mein Feed in den nächsten Tagen voll mit Hundevideos. Es bedurfte einer bewussten Anstrengung, diese Videos schnell zu überspringen, um dem Algorithmus zu verstehen zu geben, dass ich nicht an ihnen interessiert bin. Dies illustriert das Problem, dass viele soziale Netzwerke keine Möglichkeit bieten, negatives Feedback zu geben.
Anwendungsfälle
Wann immer es möglich ist, einen business case mit den Begriffen von Nutzern und Items darzustellen, kann eine Empfehlungsmaschine eingesetzt werden. Ich werde hier eine nicht vollständige Liste möglicher Szenarien aufführen:
E-Commerce-Websites - das vielleicht offensichtlichste Beispiel. Werden einem Kunden, der die Website besucht, personalisierte Empfehlungen gegeben, erhöht sich die Wahrscheinlichkeit, dass er etwas kauft.
Streaming-Dienste - Youtube, Netflix, Spotify - sie alle ermöglichen es, neue Inhalte zu entdecken, indem sie personalisierte Empfehlungen anbieten. Ich habe tatsächlich einige wirklich coole Bands entdeckt, indem ich einfach das Spotify-Radio auf der Grundlage von Dingen gehört habe, die ich mag!
Nachrichteninhalte - Die Präsentation von Nachrichtenartikeln, die Sie interessieren könnten, kann bequem sein, aber auch gefährlich, da sie zur Entstehung von so genannten Filterblasen führt. Mehr dazu im Abschnitt über Herausforderungen
Blogs - Wenn Sie diesen Artikel auf Medium lesen, dann wahrscheinlich, weil er Ihnen empfohlen wurde :)
Dating-Apps - Rein semantisch ist es sicher nicht schön, Personen hier als "Items" zu bezeichnen, aber auch dieser Anwendungsfall passt zum Paradigma von Empfehlungssystemen.
Jobportale - Es erspart viel Mühe, wenn irrelevante Jobangebote herausgefiltert werden.
Spam-Filterung - Dies unterscheidet sich ein wenig von den anderen Fällen, da (hoffentlich) die meisten Items relevant sind, kann aber auch von einem Empfehlungssystem abgehandelt werden.
Personalisierte Werbung
Und mehr!
Bei so vielen Anwendungsfällen sind Empfehlungssysteme natürlich nicht allmächtig und stehen vor einigen mehr oder weniger großen Herausforderungen.
Herausforderungen
Das "cold start"-Problem
Stellt sich ein neuer Nutzer einem Empfehlungssystem vor, ist es praktisch unmöglich, ihm maßgeschneiderte Empfehlungen zu geben. Das ist als das cold start problem bekannt. Eine Möglichkeit, hier Abhilfe zu schaffen, besteht darin, den Nutzer ausdrücklich zu fragen, an welcher Art von Produkten er interessiert ist, indem man ihm beispielsweise einige Artikel präsentiert und ihn fragt, ob diese relevant sind oder nicht. Ein anderer, vielleicht pragmatischerer Ansatz besteht darin, nur die beliebtesten Items zu empfehlen.
Long tail
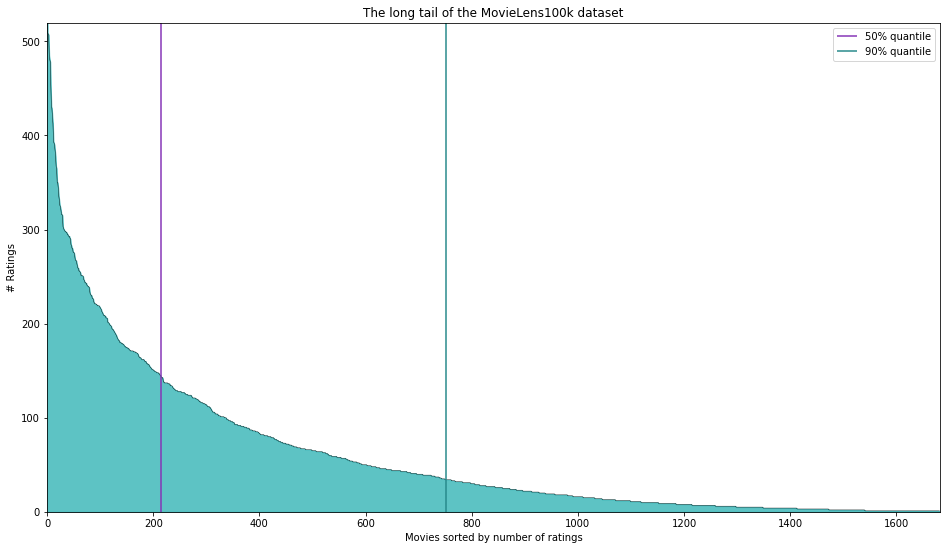
Ein weiteres häufiges Problem bei Empfehlungssystemen ist, dass meist nur sehr wenige Items eine angemessene Anzahl von Bewertungen/Interaktionen aufweisen. Diese so genannten populären Artikel können am Ende die Empfehlungen dominieren, während weniger populäre Items kaum empfohlen werden. Das ist als das long tail problem bekannt und insbesondere kollaborative Filtersysteme leiden darunter.
In der folgenden Abbildung ist das am berühmten MovieLens100k Datensatz illustriert. Dieser besteht aus 100.000 Nutzer-Film Bewertungen von 943 Nutzern für 1682 Filme. Allerdings konzentrieren sich 50% der Bewertungen auf 214 Filme (12,7% aller Filme) und 90% der Bewertungen auf 751 Filme (44,7% aller Filme). Die Mehrheit der Filme hat also sehr wenig Bewertungen und es ist schwierig, sinnvolle Empfehlungen über selten bewertete Filme zu geben!
Skalierbarkeit
Die Skalierung von Empfehlungssystemen auf Millionen von Nutzern und Items kann schnell undurchführbar werden, da sie immer größere Mengen an Rechenleistung erfordert. Einige Tech-Giganten haben das Glück, diese Leistung zur Verfügung zu haben, aber selbst dann kann es schwierig sein, Empfehlungen in Echtzeit zu geben. In dieser extremen Situation besteht eine vernünftige Strategie darin, die Anzahl der Items künstlich zu verringern, indem z.B. nur Artikel aus einer bestimmten Kategorie berücksichtigt werden, oder sogar in einer ersten Phase der Kandidatengenerierung eine Zufallsauswahl zu treffen. Außerdem können die Empfehlungen vorberechnet und gespeichert werden, so dass sie dem Benutzer beim nächsten Einloggen präsentiert werden können.
Evaluierung von Empfehlungssystemen
Eine weitere Herausforderung stellt die Evaluierung von Empfehlungssystemen dar. Aus Sicht des maschinellen Lernens ist es zwar möglich, bestimmte Metriken auf einem eingefrorenen Datensatz auszuwerten (das nennt man auch offline-Evaluierung). Offline-Evaluierung spiegelt jedoch oftmals nur teilweise die tatsächliche Situation wider - es ist schwierig bis unmöglich vorherzusagen, wie sich ein Nutzer verhalten hätte, wenn er andere Empfehlungen gesehen hätte. Außerdem kann eine zu hohe Korrektheit dazu führen, dass die Nutzer das Interesse an den Empfehlungen verlieren. Ein Beispiel für eine zu korrekte Empfehlung wäre, nur Filme zu empfehlen, die der Nutzer ohnehin gerade ansehen wollte. Nehmen wir an, Sie haben gerade die Star Wars-Episoden 4 und 5 gesehen und die einzige Empfehlung ist Episode 6. Das ist sicherlich absolut relevant, allerdings nicht wirklich wertvoll. Tatsächlich sollten gute Empfehlungen nicht nur relevant sein, sondern auch neuartig und vielfältig zugleich.
Schlussendlich wird der Erfolg von Empfehlungssystemen häufig durch A/B-Tests und die Analyse einiger zugrunde liegender Geschäftskennzahlen gemessen, z. B. Klickraten und Verweildauer im Falle eines Video-Streaming-Dienstes oder Käufe im Falle eines Online-Shops. Interessanterweise, so die Forscher in [3], korrelieren die Ergebnisse der A/B-Tests nicht unbedingt mit den vorherigen Offline-Bewertungen! Dies macht es äußerst schwierig, die Leistung eines Empfehlungssystems zu beurteilen, bevor es auf den Prüfstand gestellt wird.
Eine selbsterfüllende Prophezeiung?
Wenn Sie am Ende hauptsächlich die Inhalte konsumieren, die Ihnen empfohlen wurden, liegt das daran, dass die Empfehlungen richtig waren, oder einfach daran, dass es einfacher ist, auf bereits vorhandene Inhalte zu klicken, als aktiv nach neuen Inhalten zu suchen? Forscher haben die Entstehung so genannter Filterblasen kritisiert, am bekanntesten im Zusammenhang mit Newsfeeds von Social Media Plattformen wie Twitter oder Facebook. Gerade in diesem Umfeld ist es daher wichtig, auf Neuheit und Vielfalt bei den Empfehlungen zu achten. Aber auch für einen Online-Shop kann es von Vorteil sein, von Zeit zu Zeit unerwartete Artikel zu empfehlen - wenn sie dem Nutzer gefallen, ist das ein voller Erfolg für das Empfehlungssystem, und wenn nicht, hat das Empfehlungssystem die Chance, noch einmal schlauer zu werden.
Fazit
In diesem Blogartikel haben wir:
einen Überblick über Empfehlungssysteme und deren Relevanz bekommen
grundlegende Konzepte wie kollaboratives und inhaltsbasiertes Filtern kennengelernt
einige Anwendungsfälle erörtert
Herausforderungen und Grenzen diskutiert
Dieser Überblick ist nur der erste Teil einer Reihe von Artikeln über Empfehlungssysteme. Schauen Sie sich auch unseren Artikel über kollaboratives Filtern an, wenn Sie in die Details dieses spannenden Ansatzes eintauchen möchten. Falls Sie weitere Details zu einem Thema im Bereich Machine Learning brauchen, um Ihr Projekt erfolgreich umzusetzen, können Sie einen kostenlosen Tech Lunch mit uns buchen.
Ressourcen und weiterführende Literatur
[1] "The Youtube Video Recommendation System", Davidson et. al, 2010
[2] https://aws.amazon.com/personalize/
[3] "Deep Neural Networks for YouTube Recommendations", Covington et. al 2017
Ein guter (und technischer) Überblick über Empfehlungsmaschinen von Google.