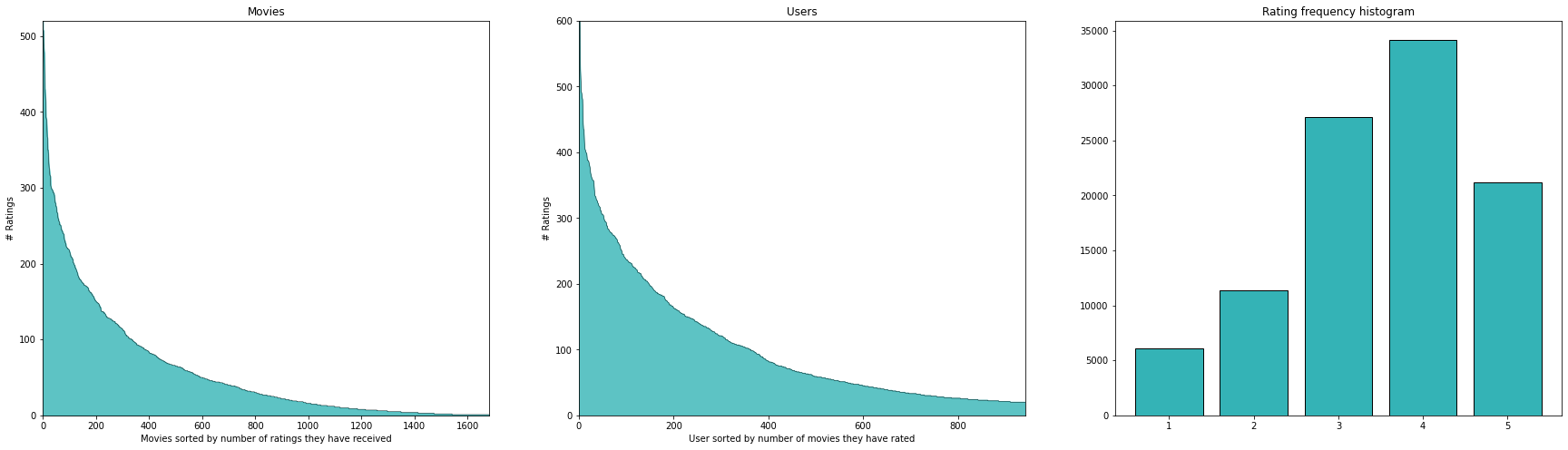
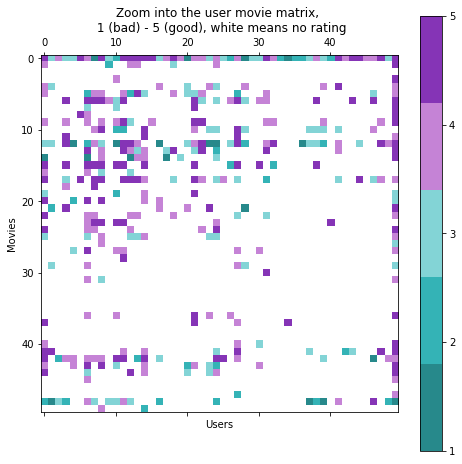
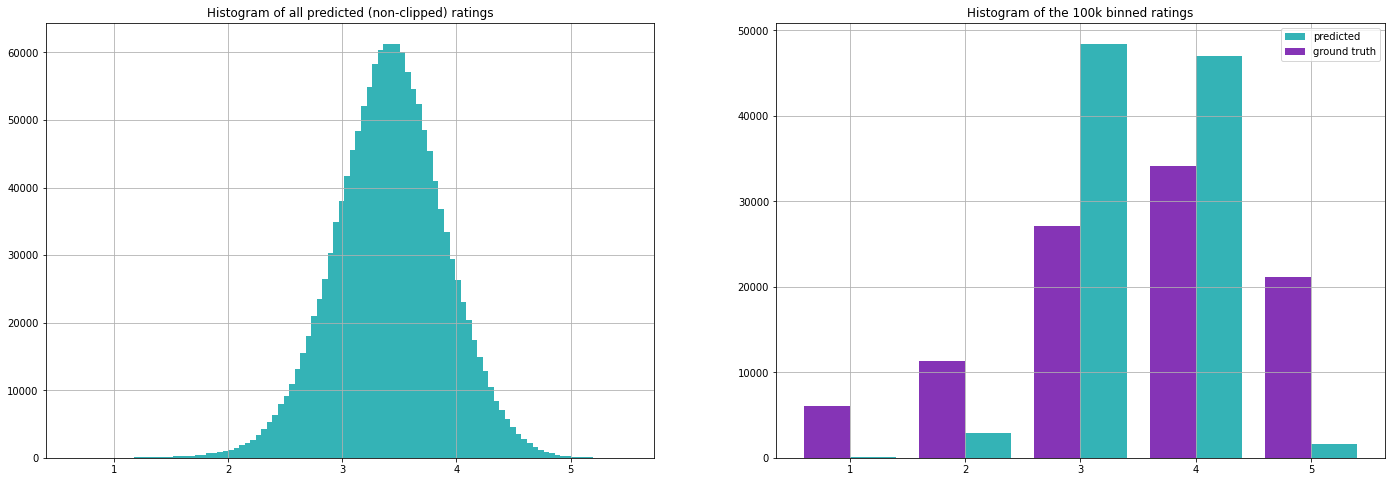
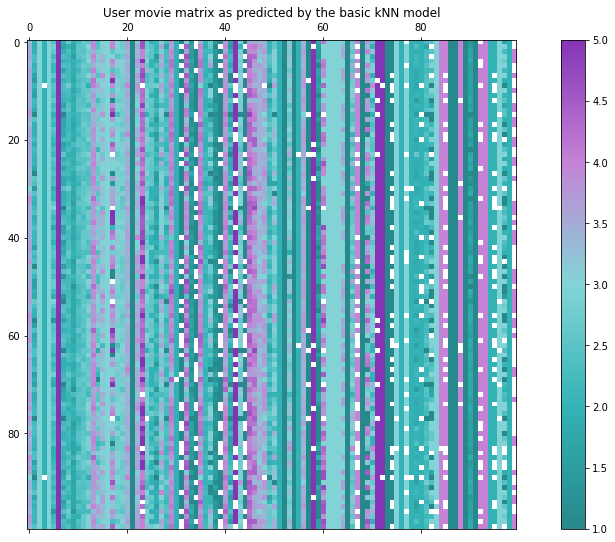
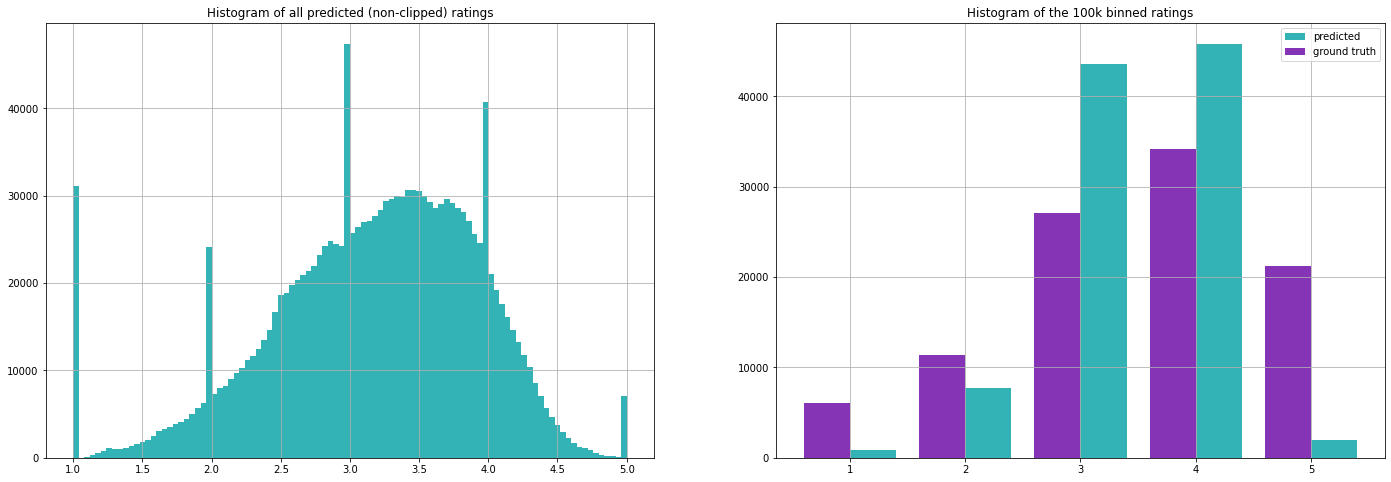
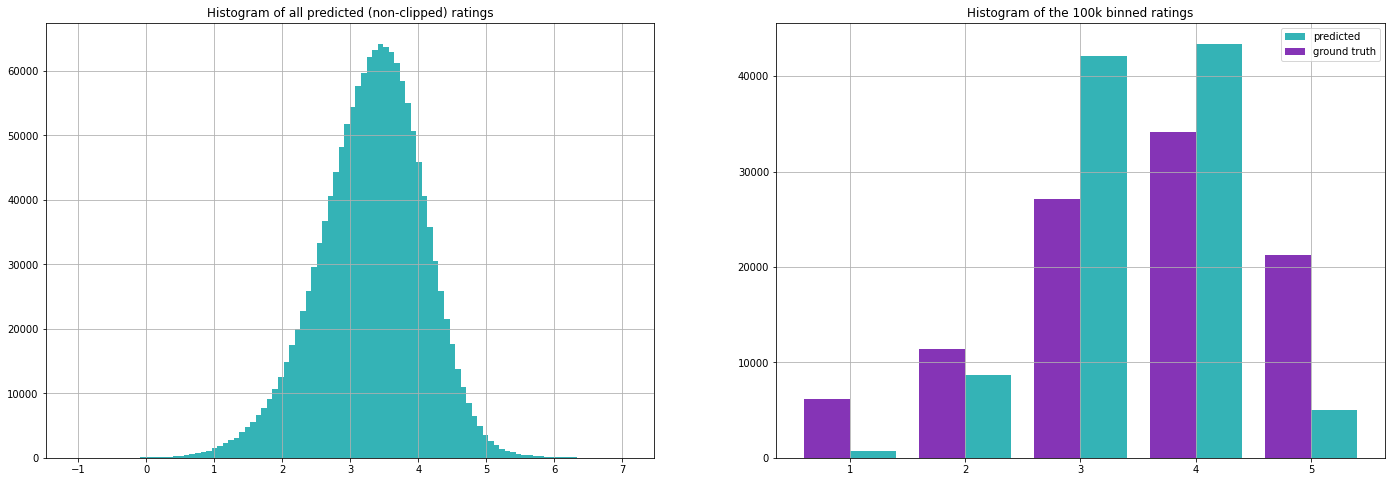
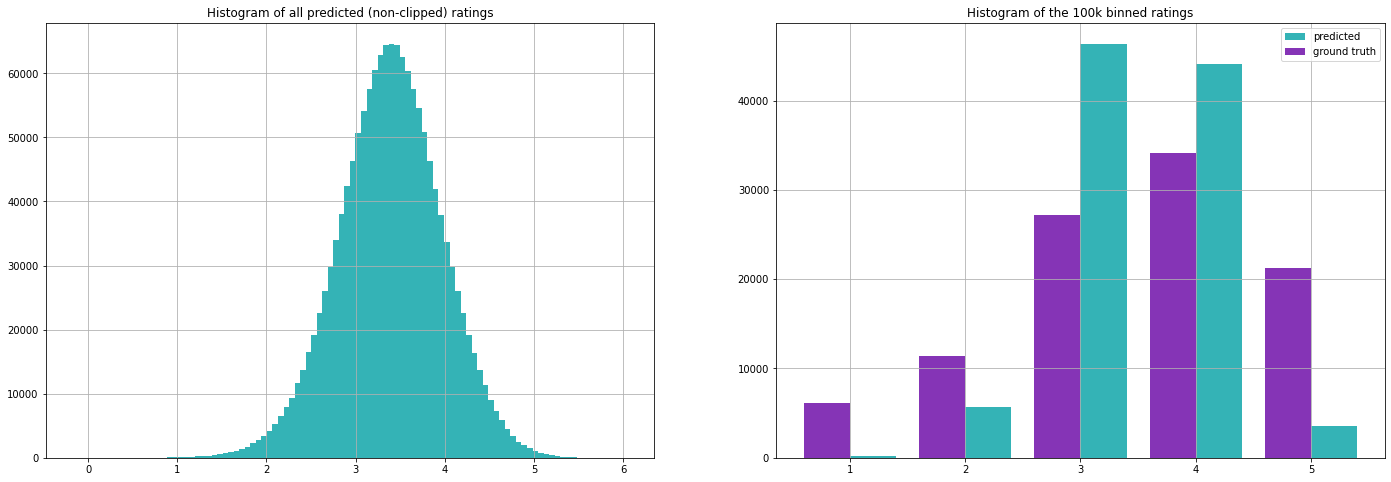
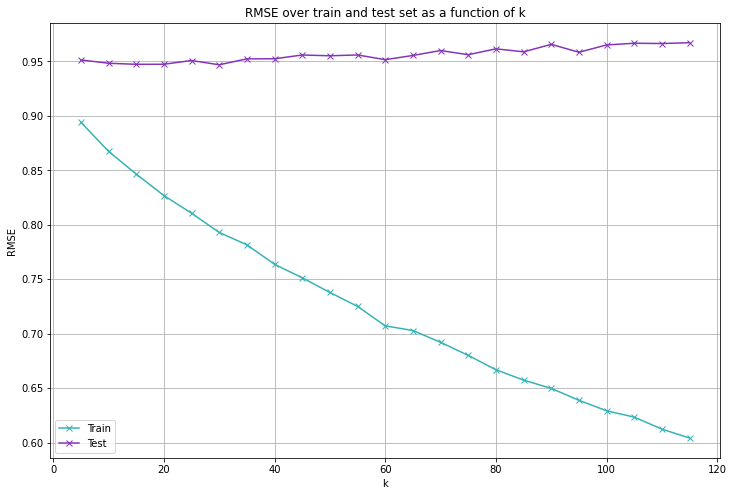
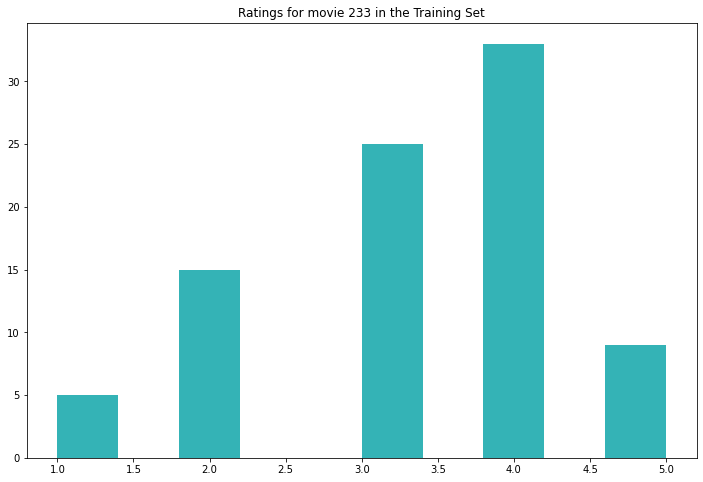
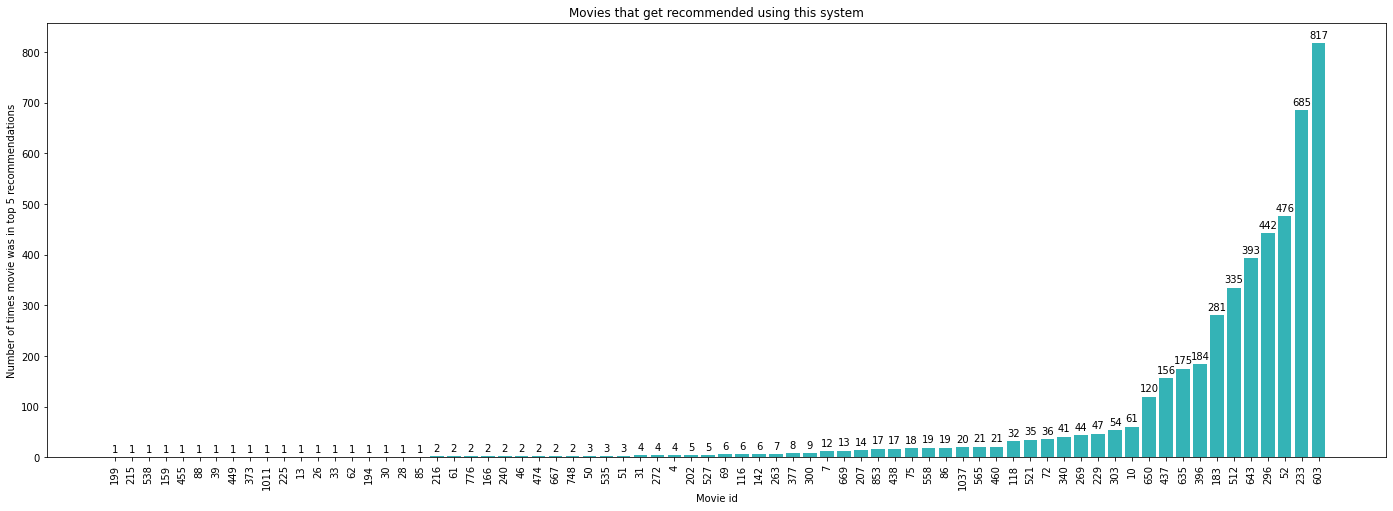
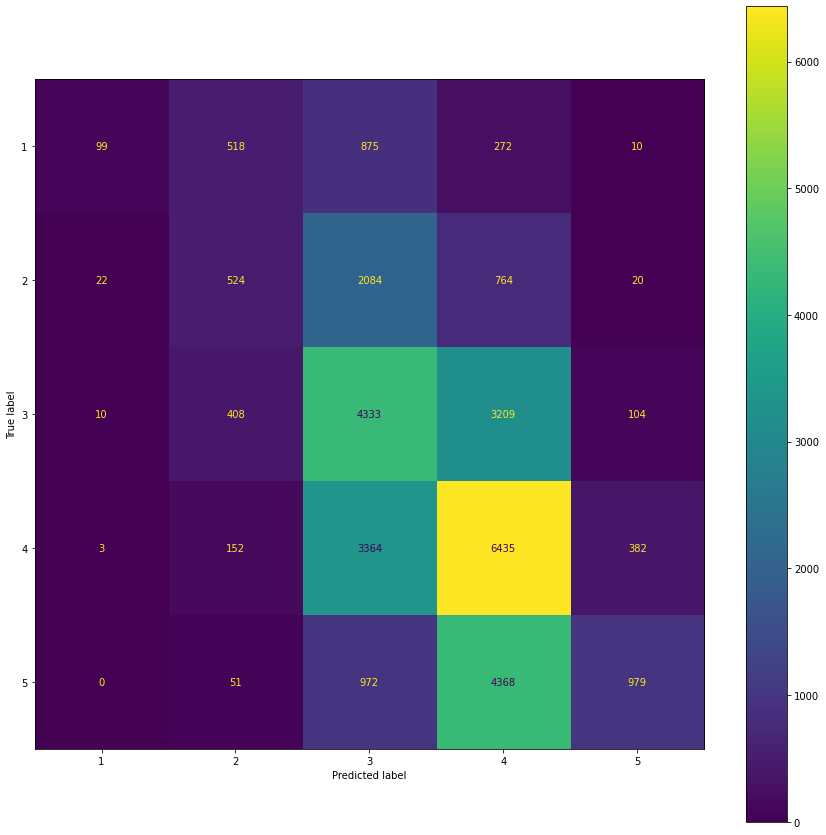
Evaluating on our test set we get the following metrics (note that we have calculated the mean values on the training set only).
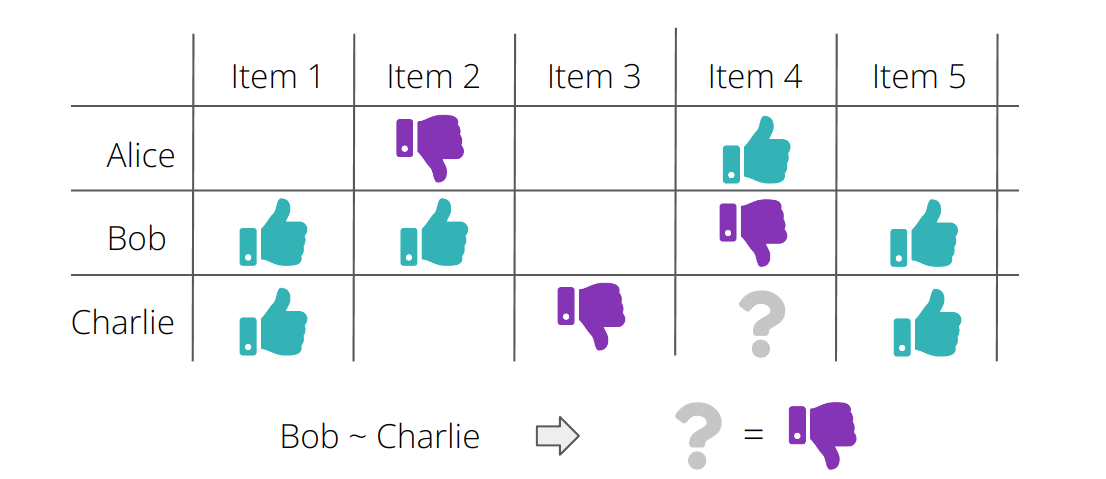
This approach is not the smartest. We have not considered any information about the users at all, so we cannot expect personalized recommendations. The rank of this user-movie matrix is one, as all columns are constant!
Just out of curiosity, we may do the same for the users. Note, however, that from a recommendation engine perspective this is useless, as by construction for each user all movies will have the same rating. We obtain the following metrics:
As we will see later, these metrics are not too bad. This illustrates an important challenge in evaluating recommendation systems, as both approaches are basically useless in providing personalized recommendations but still give decent results when evaluated with these metrics. The first approach however is quite common when there is simply no information available, i.e. when a new user signs up for a streaming service!
The algorithm, that is proposed as a baseline from the surprise library is a bit more sophisticated. For each user and each item, it introduces a (scalar) bias, $$b_u$$ and $$b_i$$, respectively. These biases are learnable parameters. The prediction is then defined as