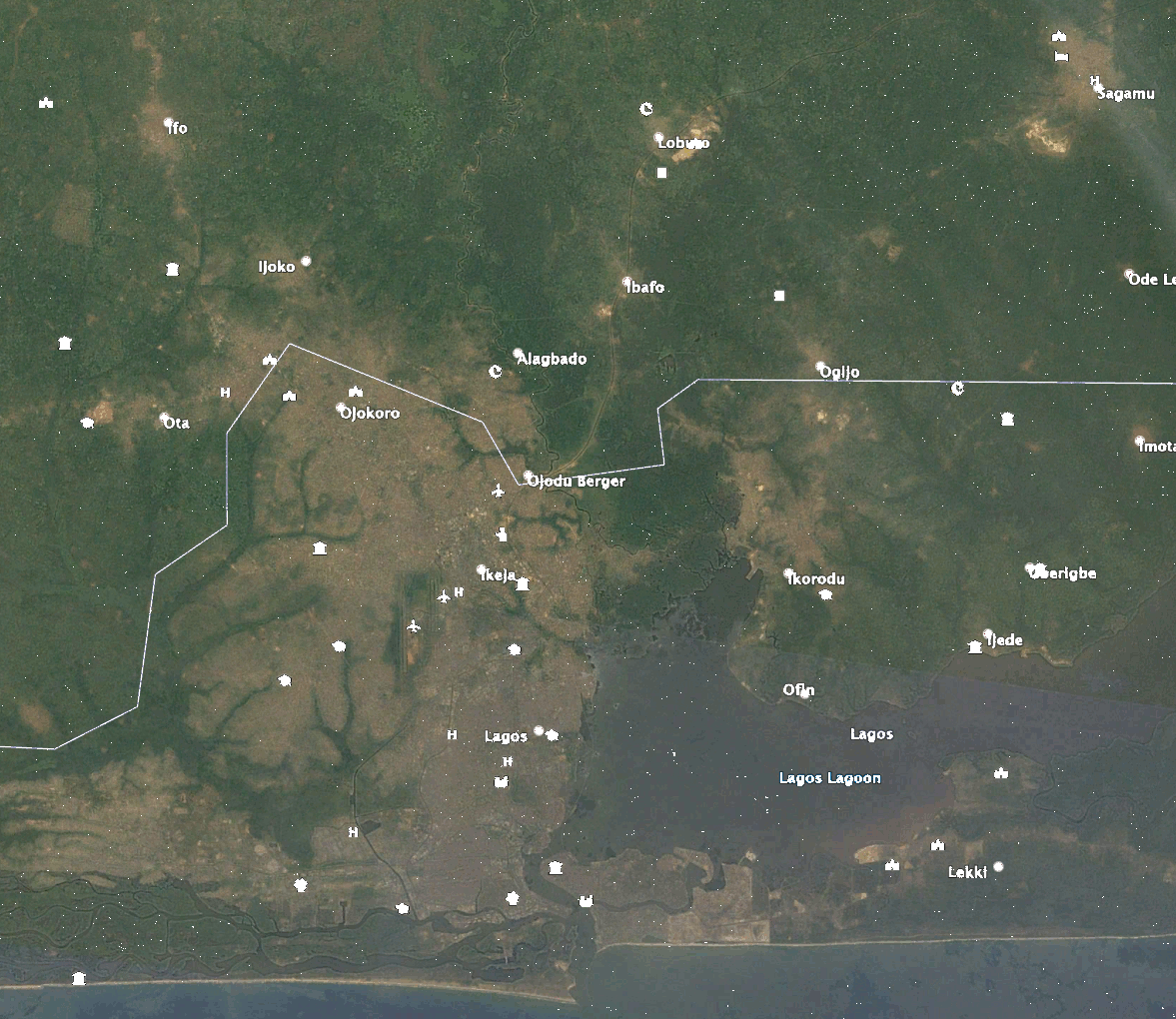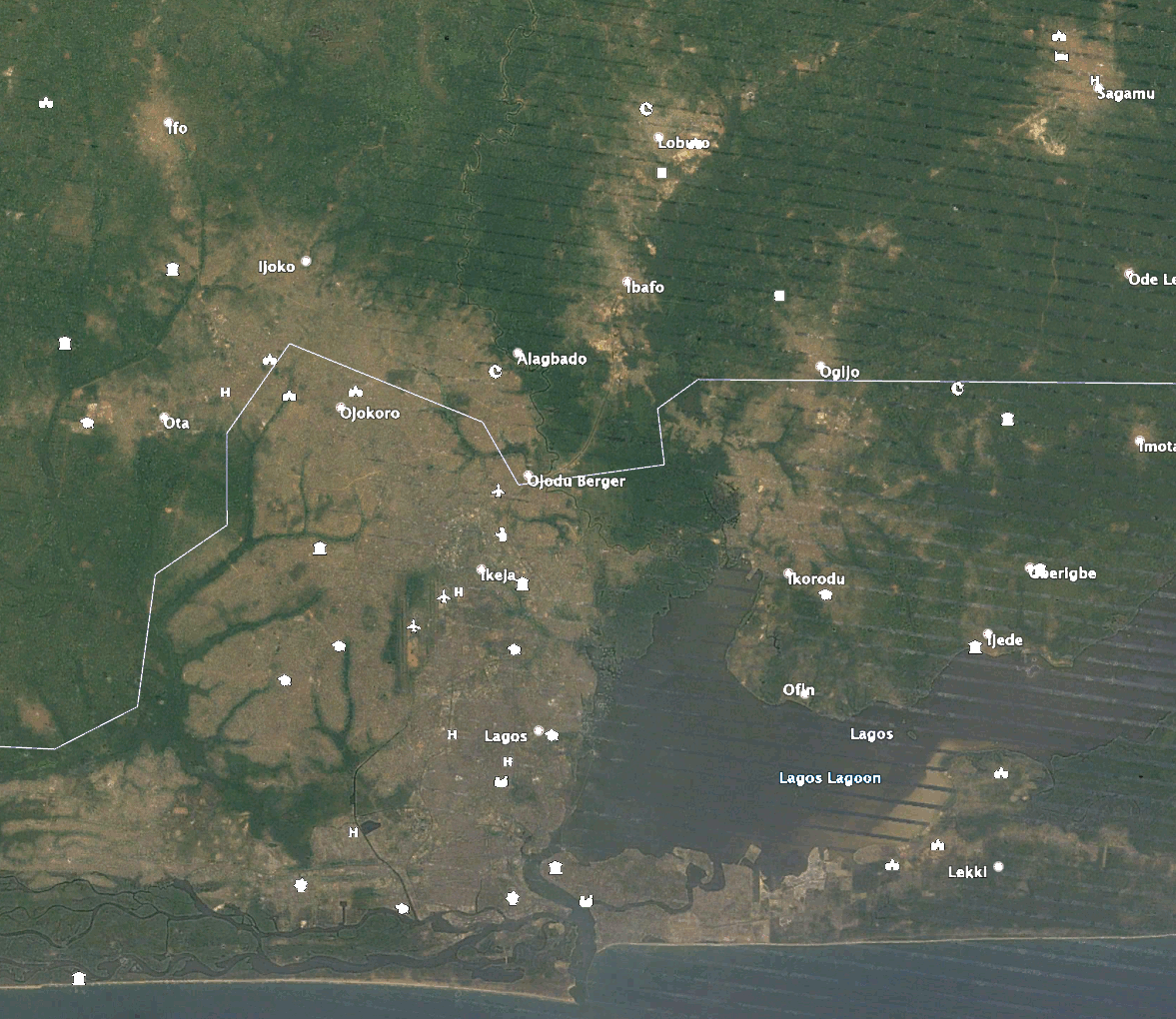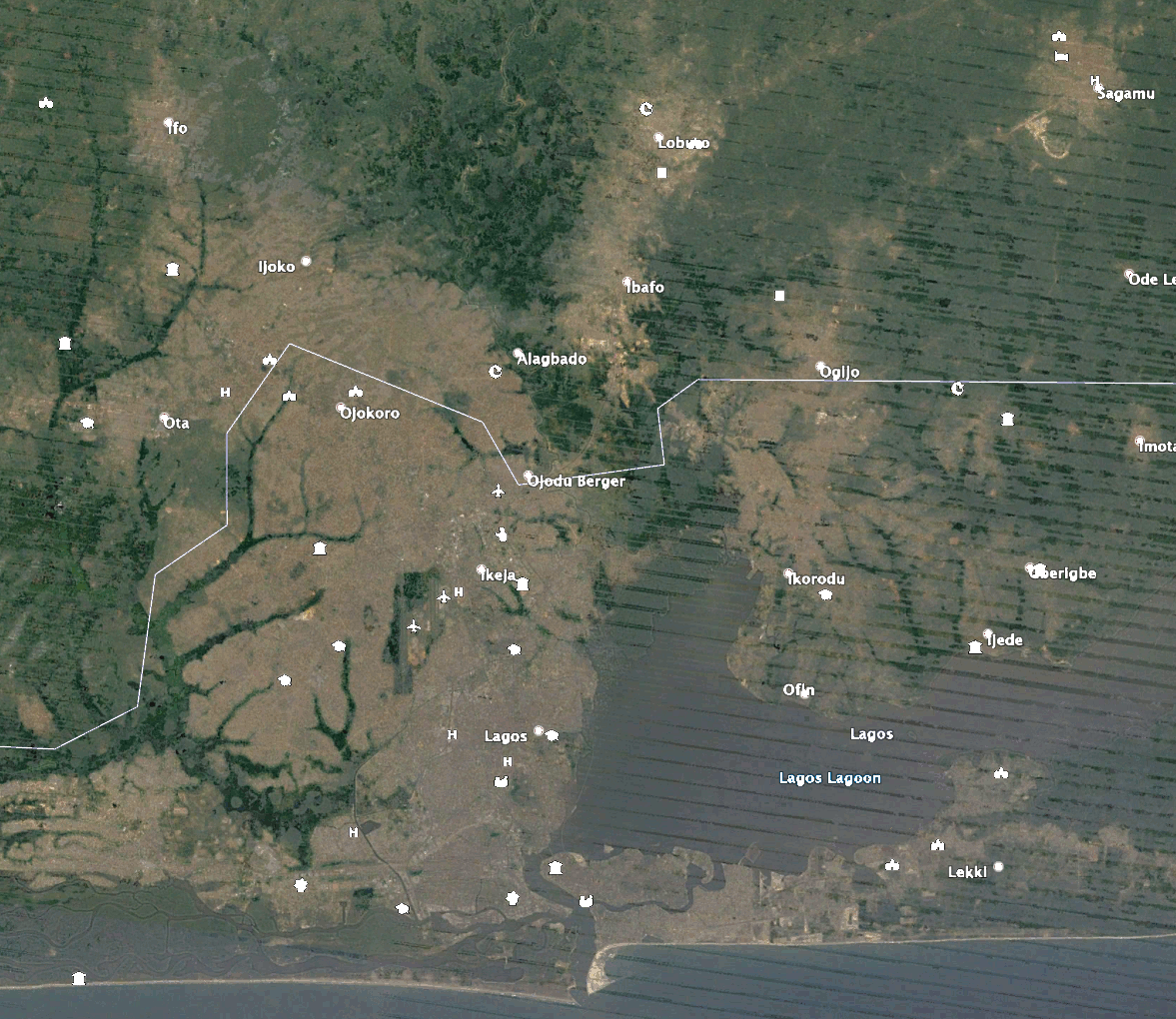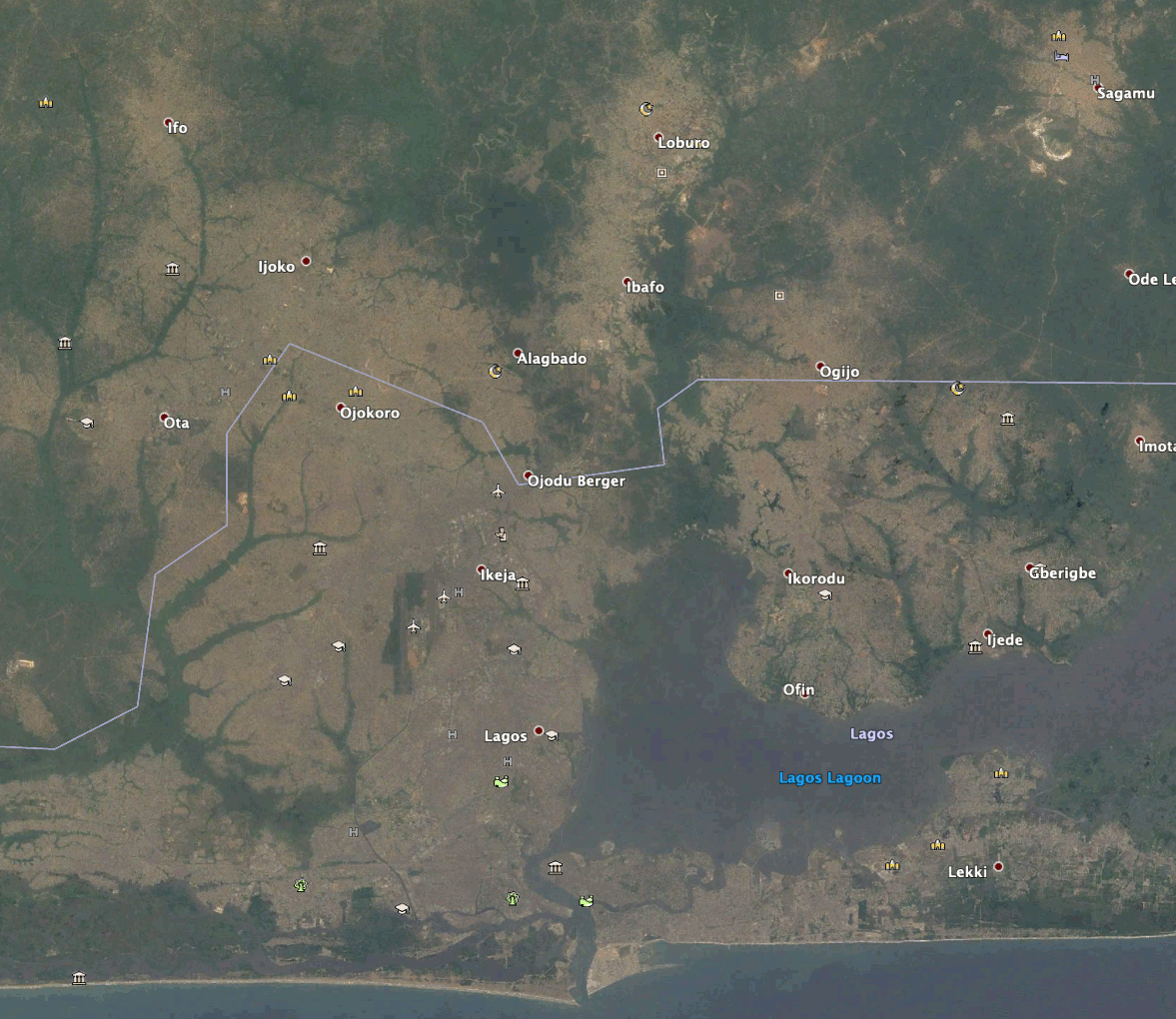
The images visualize the change in urban expansion of Lagos, Nigeria over time. The time steps range from white (2011) to red (2019) as newer and newer predictions have been made. The zoomed in images have the same timesteps as seen in the legend of the overview and are highlighting certain areas of new developments around Lagos.
Having trained the Im2Height-model in numerous different configurations, we draw a couple of conclusions from our results. Training using Structural Similarity Index Measure (SSIM) as the loss function, yield the best results in our experiments. Even though the model outputs some very large errors in some spots, they are often quite easily avoidable with the help of a simple anomaly detection as a post processing step. Using SSIM loss not only gave the best SSIM results (0.5 on training set, 0.03 on test set) in comparison to using the Mean Squared Error (MAE) loss (0.01 on training and 0.001 on test set), but removing the anomalies improves also results in a better MAE in our experiments (training: ±15m, test: ±18m vs ±18m and ±21m respectively).
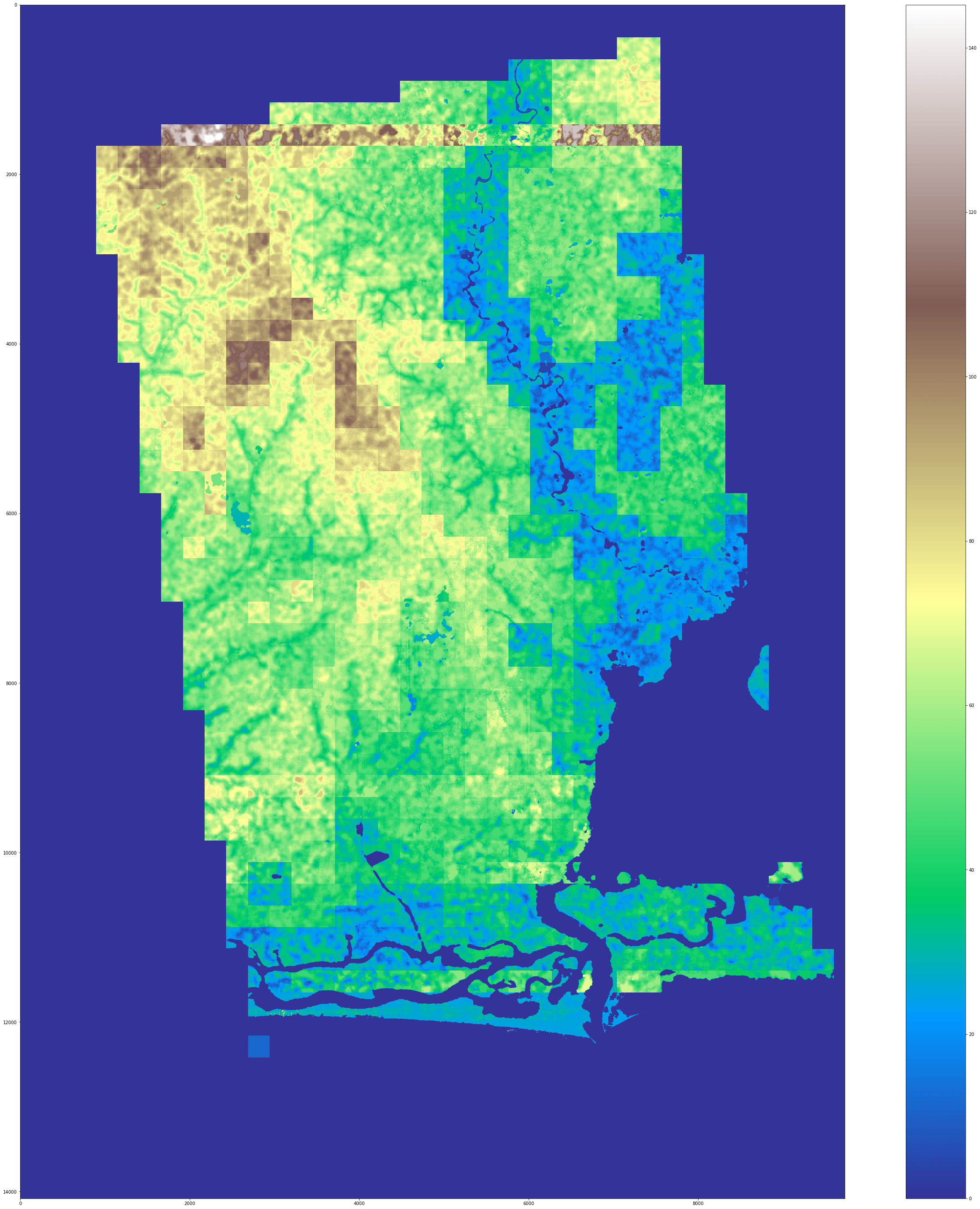
However, these errors are still too large to meaningfully detect smaller changes happening over multiple years (most of which are expected to be well below that error size). Since these results differ from the original paper, we want to outline a few possible reasons for this outcome: the low resolution of the radar data is the most likely source of this error (5x5m compared to 0.7x0.7m in the original paper) which in combination with the lack of visual clues such as shadows, etc. drastically decimate the possibility to learn from the data. Below in the gallery are some visual outputs of the predictions made by Im2Height.