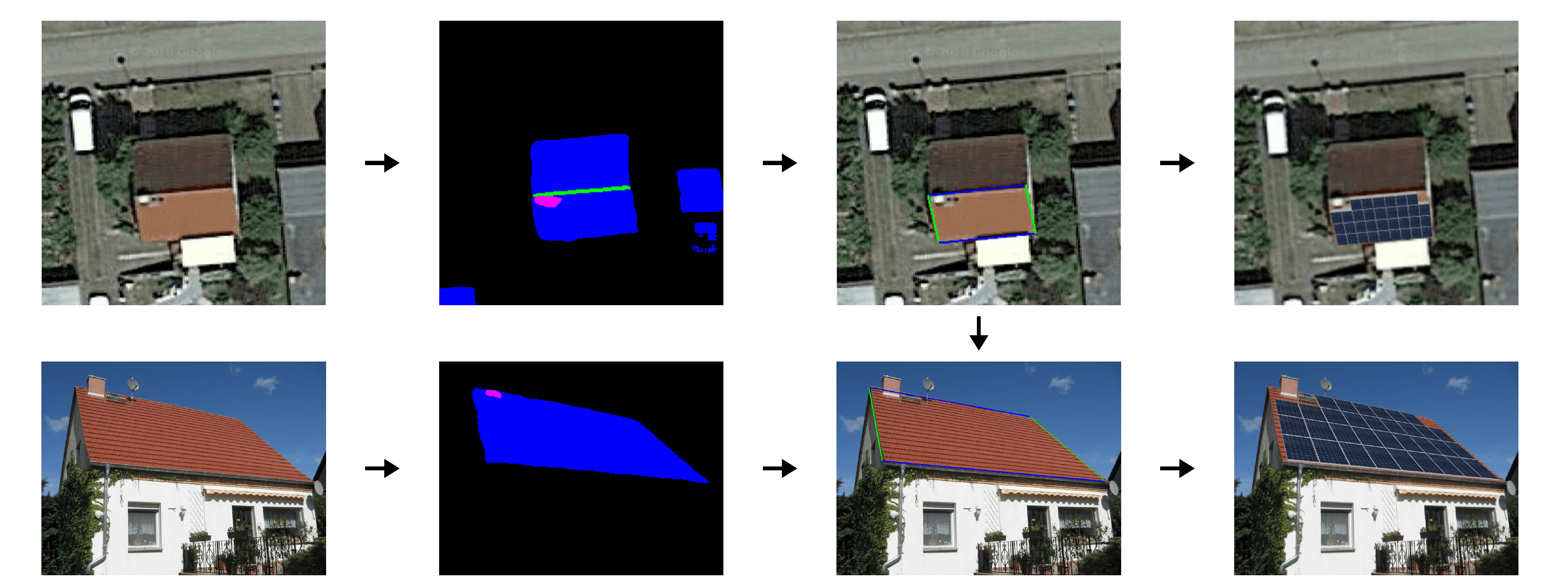
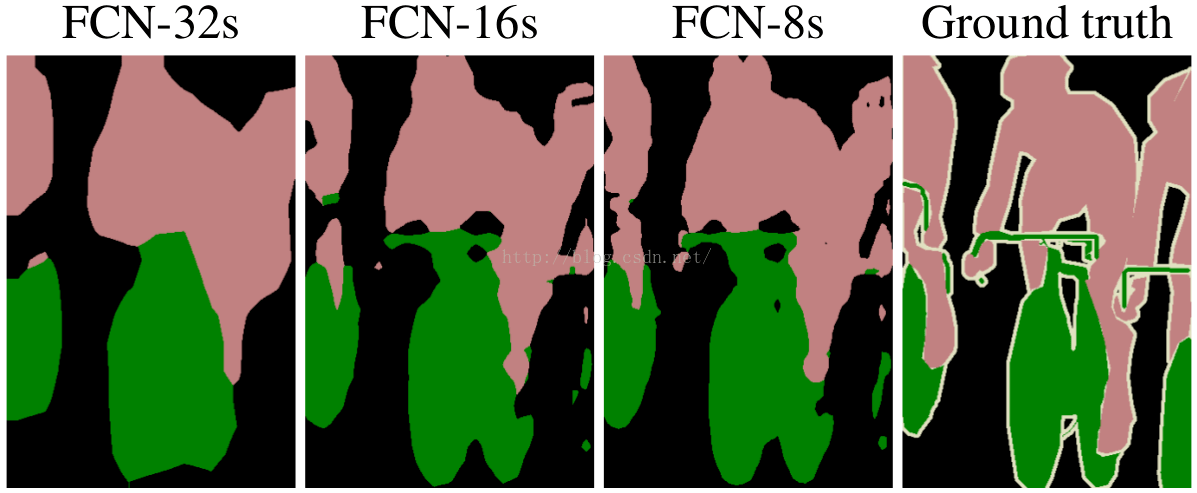
The authors claim that the main advantage of this activation is that it preserves the mean and variance of the previous layers. Moreover, it helps prevent the Dying ReLU problem (and therefore vanishing gradient problems) since its derivative is different from zero for negative values. This work was followed by others that have shown an improvement on the trainings and results. Our preliminary tests confirmed those findings and so we decided to use it.
We also added data augmentation:
Finally, the training hyper-parameters were obtained empirically using greedy optimization:
All of these parameters played an important role in the training process, but the right choice of the loss function turned out to be crucial.
Loss functions
We tested the weighted class categorical cross entropy (wcce) and the dice loss functions.
Weighted class categorical cross entropy:
For an image with $$ d1 \times d2 $$ pixels and $$ K $$ classes the weighted class categorical cross entropy is defined as