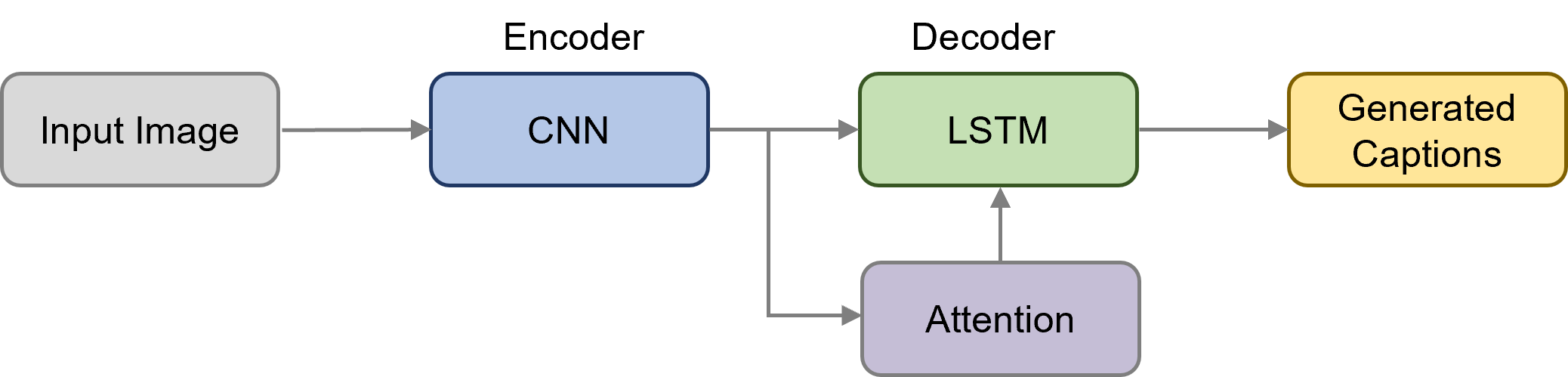
In order to extract image features, we don't have to train a CNN model from scratch. Image caption generation methods use transfer learning to extract visual information based on pre-trained Convolutional Neural Network models. Pre-trained models are previously trained networks on the ILSVRC ImageNet challenge. Image classification models trained on the ImageNet dataset usually generalize well and can be effectively applied as generic image feature extraction for various tasks in computer vision. For this reason, it is a common approach to use pre-trained CNNs to obtain visual features for image captioning. Here are some popular models pre-trained on the ImageNet:
Since those models are trained to classify objects in images, the classifier layer is skipped, and the feature map representation is extracted when applying for image captioning. We are not going into details about CNNs here. Check out this article if you want to learn how they work.
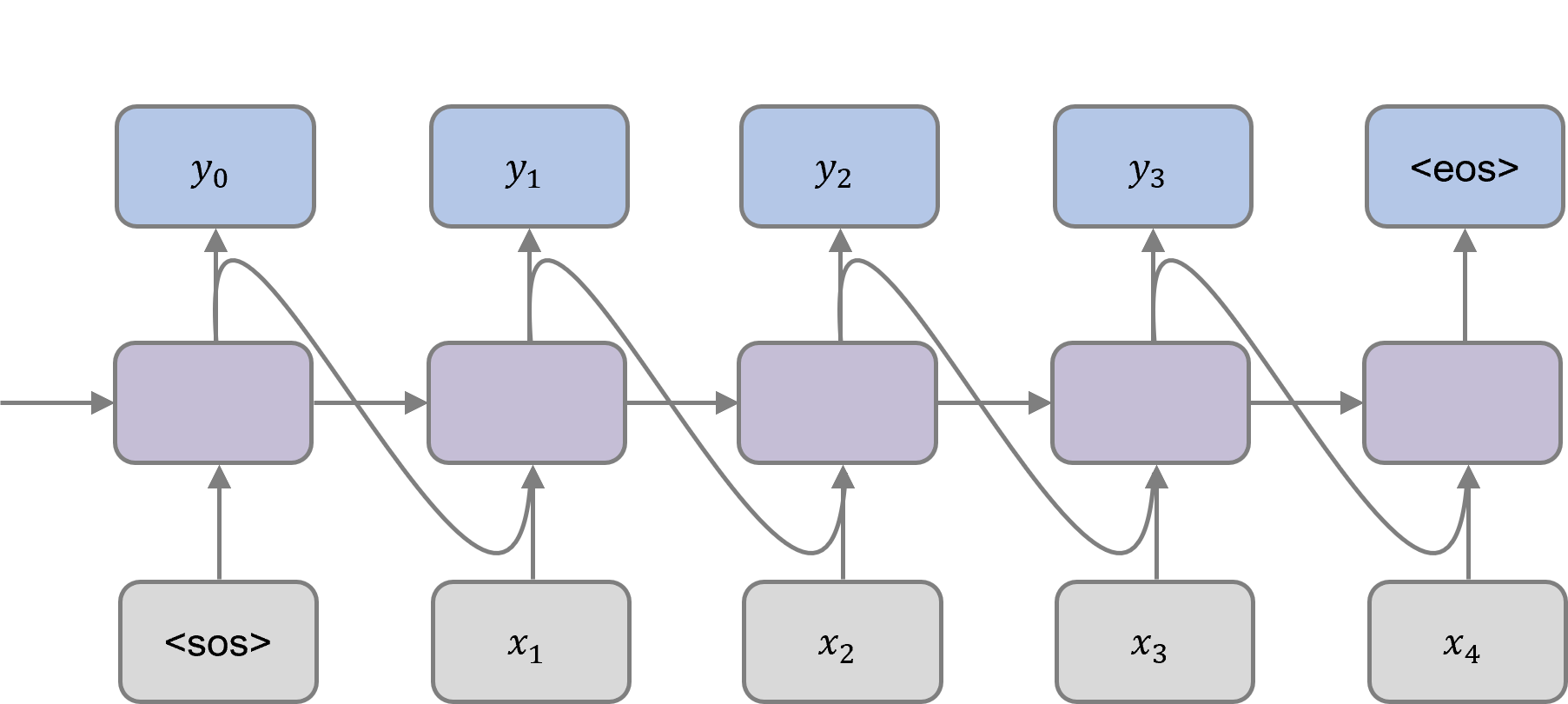
Image features in the form of a fixed-length vector are fed to the language decoder as input along with the special "<sos>" (start of sequence) token that indicates the beginning of the sequence. The decoder takes the hidden state from the previous time step and the previous predicted word at each time step to generate the output word for the current time step. This process continues until the "<eos>" (end of sequence) token is predicted.