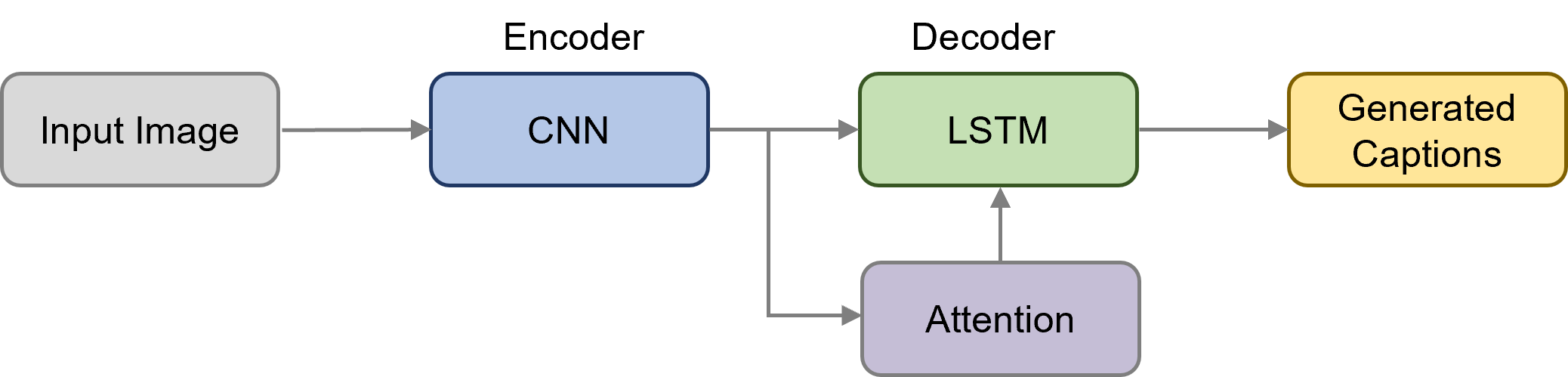
Um Bildmerkmale zu extrahieren, müssen wir nicht von Grund auf ein CNN-Modell trainieren. Methoden zur Erzeugung von Bildunterschriften verwenden Transfer Learning (zu Deutsch: Transfer-Lernen), um visuelle Informationen auf der Grundlage von vortrainierten Convolutional Neural Network-Modellen zu extrahieren. Vorgefertigte Modelle sind zuvor in der ILSVRC ImageNet Challenge trainierte Netzwerke. Bildklassifizierungsmodelle, die auf dem ImageNet-Datensatz trainiert wurden, lassen sich in der Regel gut verallgemeinern und können effektiv als generische Bildmerkmalsextraktion für verschiedene Aufgaben in der Computer Vision eingesetzt werden. Aus diesem Grund ist es ein gängiger Ansatz, vortrainierte CNNs zu verwenden, um visuelle Merkmale für Bildbeschriftungen zu erhalten. Hier sind einige beliebte Modelle, die auf dem ImageNet vortrainiert wurden:
Da diese Modelle für die Klassifizierung von Objekten in Bildern trainiert werden, wird die Klassifizierungsschicht übersprungen und die Feature-Map-Darstellung extrahiert, wenn sie für Bildbeschriftungen verwendet wird. Wir gehen hier nicht im Detail auf CNNs ein. Schauen Sie sich diesen Artikel an, wenn Sie wissen wollen, wie sie funktionieren.
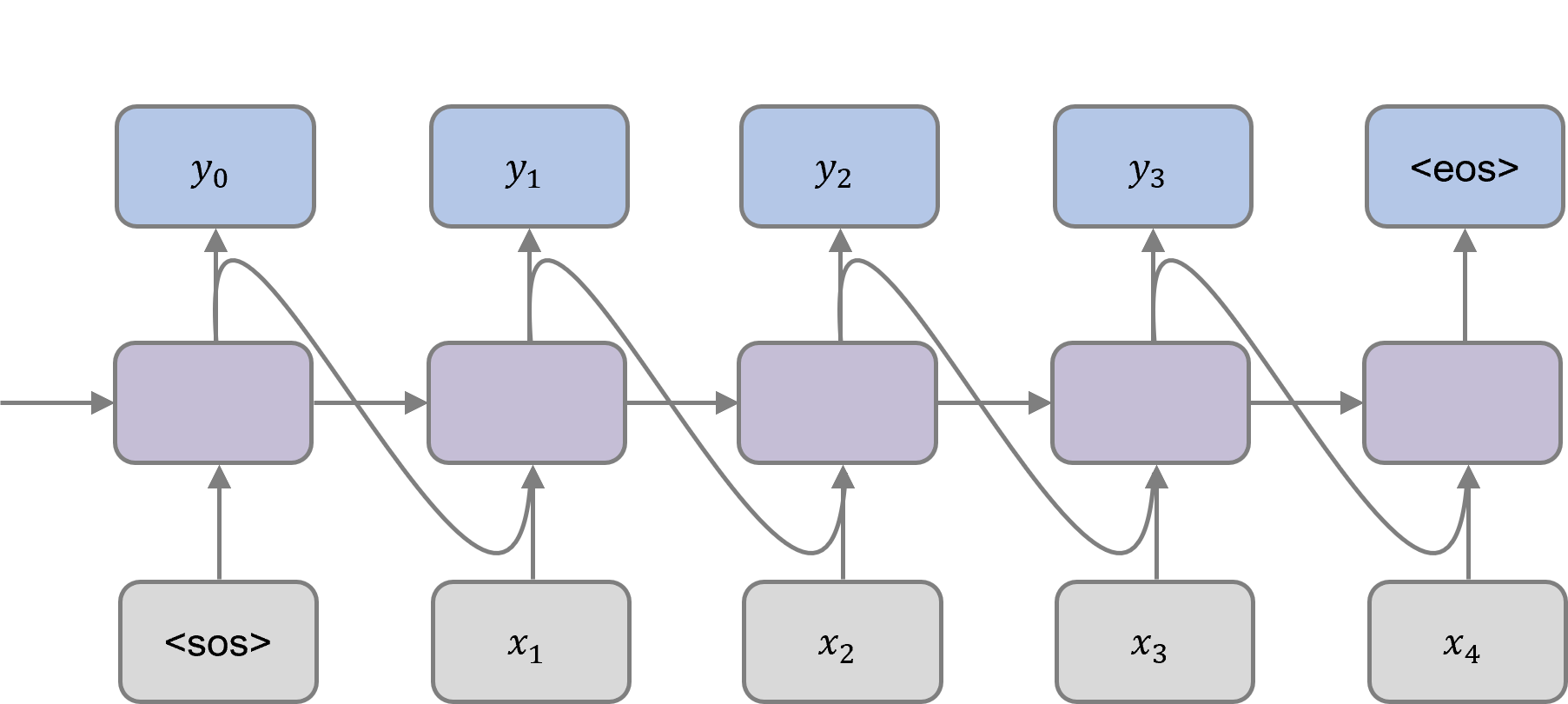
Bildmerkmale in Form eines Vektors fester Länge werden dem Sprachdecoder als Eingabe zusammen mit dem speziellen "<sos>"- (Sequenzanfang) Token, das den Beginn der Sequenz anzeigt, zugeführt. Der Decoder verwendet den verborgenen Zustand des vorherigen Zeitschritts und das vorhergesagte Wort in jedem Zeitschritt, um das Ausgangswort für den aktuellen Zeitschritt zu generieren. Dieser Prozess wird so lange fortgesetzt, bis das "<eos>"-Zeichen (Ende der Sequenz) vorhergesagt wird.