
GPT-3 and beyond - Part 2: Shortcomings and remedies

In the first part of this article I have described the basic idea behind GPT-3 and given some examples of what it is good at. This second and final part is dedicated to the “beyond” in the title.
Here you will learn
in which situations GPT-3 fails and why it is far from having proper natural language understanding,
which approaches can help to mitigate the issues and might lead to the next breakthrough,
what alternatives to GPT-3 there are already,
and, in case you are wondering, what's the connection between GPT-3 and an octopus.
Update February 14th '22: I have also included a section about OpenAI's new InstructGPT.
Model Size
In the first part of the article we have seen that the Generative Pre-Training approach relies on training a huge model on a huge dataset. This comes at a cost: First, the hardware (and energy!) requirements for training the model are gigantic. If Microsoft’s data center is at your disposal as it is for OpenAI, then you should be fine, but if you don’t have access to similar computing power, then don’t even try it.
This is actually not that bad, because why should you train your own GPT-3 model if someone else already did it for you and you can use their model - especially, if GPT-3 is intended to perform well without further fine tuning?
But what is really annoying is that the model is so big that even using it for inference only is impossible with usual computers and most servers: It is estimated that GPT-3 requires at least 350 GB of VRAM just to load the model and run inference at a decent speed. This means that even if OpenAI released the trained GPT-3’s model weights, hardly anyone (including many small to medium-sized tech companies) would be able to use it.
Knowledge Distillation
There is a potential solution to this problem: compressing large models into smaller ones via knowledge distillation, as proposed by Geoffrey Hinton et al. 2015. Currently there is a lot of research going on about how to apply this approach best to large language models. Going into details would go beyond the scope of this article, but the basic idea is the following: Assume we have a well-trained large language model (e.g. GPT-3), additionally a still untrained conveniently small language model (i.e. one that you could do inference with on your machine) and a training example like
I like coffee with [milk]
.jpg)
In order to train the small model, we would usually pose the task: “Predict the next word correctly”, that is the word after “with”. This means the only correct answer is “milk”, and the answer “sugar” just as wrong as extravagances like “champagne”, semantic nonsense (“I like coffee with platitudes”) and even ungrammatical continuations (“I like coffee with early”).
Recall that the large language model has learned the conditional probability of the word following “I like coffee with”, which means it has learned to quantify how well any given word continues the sentence. Since both “milk” and “sugar” make a lot of sense in the above context, it will assign high probabilities to these two, a significantly lower probability to the still more or less reasonable “champagne” and probabilities close to zero to “platitudes” and “early”.
For knowledge distillation, one uses these probabilities as soft labels: This has the effect that during training both “milk” and “sugar” count as similarly good answers, which models much better what we want the small model to learn (i.e. which words generally make sense as continuation, and not which particular word followed in one example sentence). It turns out that via this new task which takes into account soft labels one can train the small model much more efficiently than with the original task.
Of course the knowledge distillation approach presupposes that there is a lot of redundancy in the large model, such that a smaller model with less parameters is generally able to reach a similar performance. In particular, if you want to use GPT-3 only for a very specific task, then you probably don’t need all of the skills stored in its many parameters and you might be able to shrink down the model size without severe deterioration of performance.
Switch Transformers
Knowledge distillation helps to shrink down huge language models and is sometimes necessary to make them usable for practical purposes. But it doesn’t change the fact that increasing model size (i.e. the number of parameters) has proven to be a key factor for improving performance (e.g. see here). This being said, there might be ways to make use of these parameters more efficiently than GPT-3 does (in terms of computational cost).
Earlier this year, Google introduced a variation on classical Transformer architectures, in which for each training and prediction run only a subset of the model parameters is used. The idea is that for each individual input only a small share of the model's parameters needs to be active to process it. Figuratively speaking, the model contains various experts which are specialized to specific input data. Based on the input, the model decides dynamically which experts to consult - the rest stays idle, i.e. their parameters are not used and the corresponding computations saved. This choice of experts does not happen as an initial step, but within each Switch Transformer encoder block (the overall model stacks a lot of these).
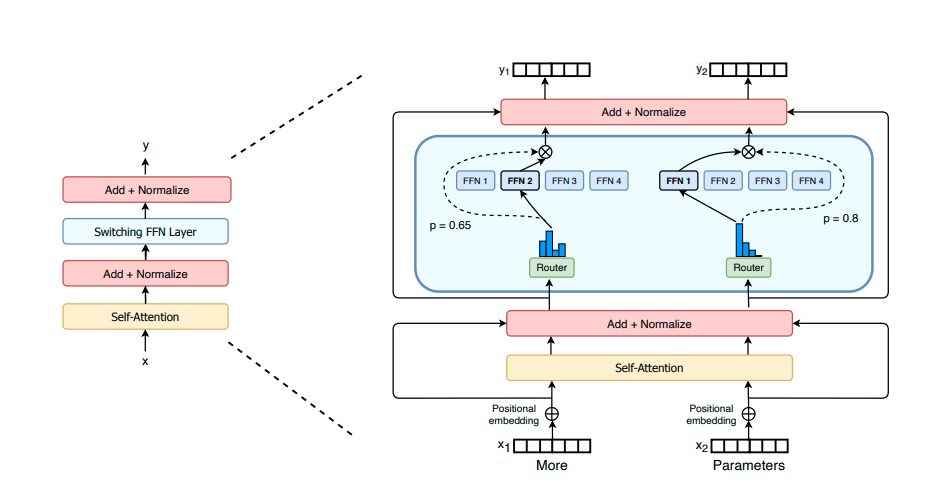
In effect, the Switch Transformers decouple the computational costs of training and inference from the model size and allows to train and use even bigger models than GPT-3. Whether scaling models further up is really the way to go, is an open question.
Language models don’t understand language (or do they?)
There are several natural language processing tasks where GPT-3 is far from the state of the art, e.g. translation. For some of them one can argue that this is due to the composition of the training data. For example, only a small subset of the training set contains German-to-English to translations. Hence performance could probably be improved by adding more translation examples, which means that the gap to the state of the art performance could potentially be closed.
However, there are some deeper issues with GPT-3, which are not due to the composition or amount of training data, but inherent to the language modeling training task. Language models learn to treat language as a game of formal symbols, which can be concatenated according to some rules. These rules include semantic relations between words (e.g. that orange and lemon are somewhat similar), which is why people sometimes say that language models also learn something about the meaning of words. But it is important to realize what they will never learn, because it doesn’t even come into the picture in the training task: That words, sentences and text in general refer to something beyond the text, namely to things/events/facts that exist/take place/hold in reality - or at least possibly could exist/take place/hold. Via this link to reality sentences can be true or false and utterances morally good or bad. But that’s nothing language models know about. They only produce textual output based on the texts they have been trained on, and they do that by emulating the style and content of the training data.
It is a common view that for these reasons language models can only learn the form of language, but not meaning, and hence not acquire anything which resembles human-level understanding of language even remotely. This is not a purely philosophical issue, but has practical consequences: In fact, it seems that GPT-3 performs very poorly in tasks which seem to require some sort of practical acquaintance with the world. An article published in MIT Technology Review presents a couple of interesting cases, for example the following, where GPT-3’s prompt completion is highlighted in bold letters:
You poured yourself a glass of cranberry juice, but then you absentmindedly poured about a teaspoon of grape juice into it. It looks okay. You try sniffing it, but you have a bad cold, so you can’t smell anything. You are very thirsty. So you drink it.
You are now dead.
.jpg)
The authors explain GPT-3’s confusion as follows:
In the cranberry juice example, GPT-3 continues with the phrase “You are now dead” because that phrase (or something like it) often follows phrases like “… so you can’t smell anything. You are very thirsty. So you drink it.” A genuinely intelligent agent would do something entirely different: draw inferences about the potential safety of mixing cranberry juice with grape juice.
The limitations of language models also have very serious ethical implications: Language models might perpetuate biases (e.g. racist prejudices) present in the training data. Since we are going to dedicate a separate blog post to those implications, I won’t delve any further into the ethical dimension here.
Of course there are opposing views, which either deny the thesis that language models don’t acquire proper language understanding or dispute that it would have very serious practical implications if they in fact they don’t (this blog article summing up a twitter debate gives a good idea about the respective arguments). For the second type of objection, compare Bender and Koller 2020, in which the authors use a thought experiment to point out apparently fundamental shortcomings of language models. Bender and Koller compare GPT-2 to a hyperintelligent deep-sea octopus that learned to tap into a underwater communication cable and starts to insert himself into conversations. They claim that their argument implies that language models will never be able to solve even simple arithmetic problems (see page 5198):
[...] we let GPT-2 complete the simple arithmetic problem Three plus five equals. [...] this problem is beyond the current capability of GPT-2, and, we would argue, any pure LM.
But by now GPT-2 successor GPT-3 has proven to be capable of solving one-digit summation problems - although it's still a pure language model.
Symbol Grounding: Fusion of Language and Vision
As OpenAI’s Chief scientist Ilya Sutskever put it in his wishes for 2021,
[t]ext alone can express a great deal of information about the world, but it is incomplete, because we live in a visual world as well. The next generation of models will be capable of editing and generating images in response to text input, and hopefully they’ll understand text better because of the many images they’ve seen.
This ability to process text and images together should make models smarter. Humans are exposed to not only what they read but also what they see and hear. If you can expose models to data similar to those absorbed by humans, they should learn concepts in a way that’s more similar to humans.

CLIP already shows how this could look like. The hope is that images teach the models that language refers to something beyond the text, e.g. that the word “ball” refers to objects of a certain shape present in some images. Once such links are established, i.e. the linguistic symbols grounded, knowledge about the relations between objects can inform the model about how the corresponding words relate and improve its performance in NLP tasks.
Recent Advances
Though probably still the most famous, GPT-3 is not the biggest and not the best-performing language model anymore. Just a couple of days ago, NVidia and Microsoft released Megatron-Turing NLG 530B, which is roughly three times the size of GPT-3 - representing the brute force approach (at least from the perspective of machine learning) of making progress by scaling models further up.
But it gets even larger: In summer the Beijing Academy of Artificial Intelligence (BAAI) presented Wu Dao 2.0, which comes with ten times as many parameters as GPT-3. The BAAI doesn’t share many details regarding the datasets, training and possible applications, but it is known that it uses both Switch Transformers and the symbol grounding approach described above - in fact, it uses 3 terabytes of textual and 90 terabytes of image data.
FLAN is a fine-tuned language model obtained via instruction tuning presented by Google roughly two weeks ago. Instead of training a model only on the language modeling task, they use natural language instructions (as prompts) to make labeled datasets for specific NLP problems available for additional training. For a natural language inference dataset this looks as follows, where the templates correspond to different ways of transforming the instruction into a prompt:
It turns out that the instruction-tuned FLAN outperforms GPT-3 especially in a zero-shot setting (for evaluation unseen tasks are considered, of course).
GPT-3 with Reinforcement Learning: InstructGPT
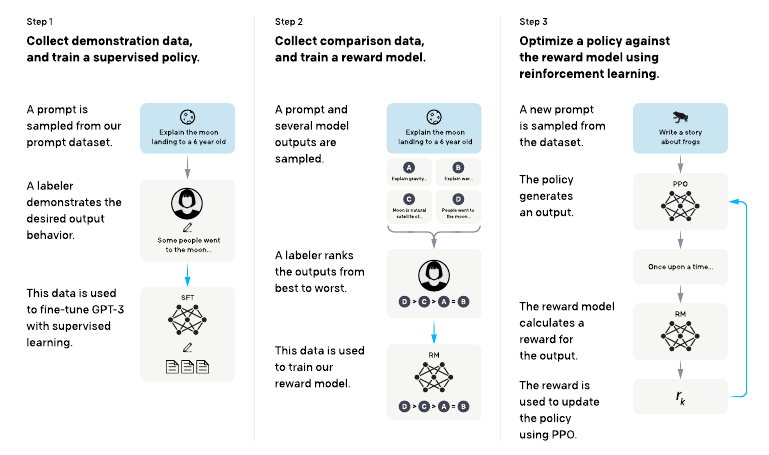
GPT-3 was trained on the classical language modeling task "predict the next word". However, its most interesting applications are of the type "generate text according to the given instruction". Hence it might make sense to fine-tune GPT-3 to real world tasks in order make it align better with user intents. In fact, that is what OpenAI did with InstructGPT: They curated a dataset of instruction-like prompts together with examples of user-desired outputs and used it for fine-tuning. Then they went even a step further: They applied reinforcement learning in order to teach InstructGPT to produce outputs that users would like. In order to obtain the feedback (i.e. reward) necessary for reinforcement learning, they trained a reward model. This model is taught to rank a set of possible outputs for a given prompt from best to worst.
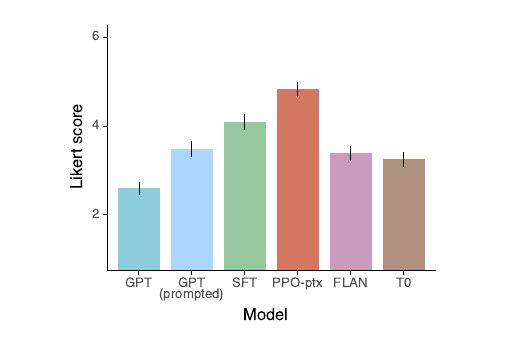
It turns out that labelers prefered InstructGPT's outputs for instruction-like prompts to those of the original GPT-3, FLAN and T0:
Conclusion
We have seen that large language models suffer from exorbitant computational requirements and possibly very fundamental limitations. At the same time, approaches have been suggested and are currently tried out which might mitigate these issues.
While the hype around GPT-3 might have been exaggerated and blind to its persisting shortcomings, it's already safe to say that the success of Transformer-based language models started a new era for NLP.
Contact
If you would like to speak with us about this topic, please reach out and we will schedule an introductory meeting right away.