
GPT-3 und darüber hinaus - Teil 2: Schwächen und Gegenmittel

Im ersten Teil dieses Artikels habe ich die Grundidee von GPT-3 beschrieben und einige Beispiele dafür gegeben, wozu es gut ist. Dieser zweite und letzte Teil ist dem "darüber hinaus" im Titel gewidmet.
Hier werden Sie erfahren
in welchen Situationen GPT-3 versagt und warum es weit davon entfernt ist, natürliche Sprache richtig zu verstehen,
welche Ansätze helfen können, die Probleme zu beheben und vielleicht zum nächsten Durchbruch zu führen,
welche Alternativen zu GPT-3 es bereits gibt,
und, falls Sie sich sich wundern, was die Verbindung zwischen GPT-3 und einem Oktopus ist.
Modellgröße
Im ersten Teil des Artikels haben wir gesehen, dass der Ansatz des generativen Pre-Trainings auf dem Training eines großen Modells mit einem großen Datensatz beruht. Dies ist mit Kosten verbunden: Erstens sind die Hardware- (und Energie-!) Anforderungen für das Training des Modells gigantisch. Wenn Ihnen das Rechenzentrum von Microsoft zur Verfügung steht, wie es bei OpenAI der Fall ist, sollte das kein Problem sein, aber wenn Sie keinen Zugang zu einer ähnlichen Rechenleistung haben, sollten Sie es gar nicht erst versuchen.
Das ist eigentlich gar nicht so schlimm, denn warum sollten Sie Ihr eigenes GPT-3-Modell trainieren, wenn jemand anderes das bereits für Sie getan hat und Sie dessen Modell verwenden können - vor allem, wenn GPT-3 ohne weitere Feinabstimmung gut funktionieren soll?
Was aber wirklich hinderlich ist, ist die Tatsache, dass das Modell so groß ist, dass selbst die Verwendung nur für Vorhersagen mit normalen Computern und den meisten Servern unmöglich ist: Es wird geschätzt, dass GPT-3 mindestens 350 GB VRAM benötigt, nur um das Modell zu laden und die Vorhersagen mit einer angemessenen Geschwindigkeit durchzuführen. Das bedeutet, dass selbst wenn OpenAI die trainierten Modellgewichte von GPT-3 veröffentlichen würde, kaum jemand (einschließlich vieler kleiner und mittlerer Technologieunternehmen) in der Lage wäre, sie zu nutzen.
Wissensdestillation
Es gibt eine mögliche Lösung für dieses Problem: die Komprimierung großer Modelle in kleinere Modelle durch Wissensdestillation, wie von Geoffrey Hinton et al. 2015 vorgeschlagen. Derzeit wird viel darüber geforscht, wie sich dieser Ansatz am besten auf große Sprachmodelle anwenden lässt. Es würde den Rahmen dieses Artikels sprengen, auf Einzelheiten einzugehen, aber die Grundidee ist die folgende: Nehmen wir an, wir haben ein gut trainiertes großes Sprachmodell (z. B. GPT-3), zusätzlich ein noch untrainiertes, bequem anzuwendendes kleines Sprachmodell (d. h. eines, mit dem Sie auf Ihrer Maschine Vorhersagen durchführen könnten) und ein Trainingsbeispiel wie
Ich mag Kaffee mit [Milch]
.jpg)
Um das kleine Modell zu trainieren, würden wir normalerweise die Aufgabe stellen: "Sage das nächste Wort richtig voraus", also das Wort nach "mit". Das bedeutet, dass die einzig richtige Antwort "Milch" ist, und die Antwort "Zucker" ebenso falsch wie Extravaganzen wie "Champagner", semantischer Unsinn ("Ich mag Kaffee mit Plattitüden") und sogar ungrammatische Fortsetzungen ("Ich mag Kaffee mit früh").
Erinnern Sie sich, dass das große Sprachmodell die bedingte Wahrscheinlichkeit des Wortes nach "Ich mag Kaffee mit" gelernt hat, d.h. es hat gelernt zu quantifizieren, wie gut ein bestimmtes Wort den Satz fortsetzt. Da sowohl "Milch" als auch "Zucker" im obigen Kontext sehr sinnvoll sind, wird es diesen beiden Wörtern hohe Wahrscheinlichkeiten zuweisen, dem immer noch mehr oder weniger sinnvollen "Champagner" eine deutlich geringere Wahrscheinlichkeit und "Plattitüden" und "früh" Wahrscheinlichkeiten nahe Null.
Für die Wissensdestillation verwendet man diese Wahrscheinlichkeiten als Soft Labels: Das hat den Effekt, dass beim Training sowohl "Milch" als auch "Zucker" als ähnlich gute Antworten zählen, was viel besser das modelliert, was das kleine Modell lernen soll (d.h. welche Wörter allgemein als Fortsetzung Sinn machen, und nicht welches bestimmte Wort in einem Beispielsatz folgte). Es zeigt sich, dass man mit dieser neuen Aufgabe, die Soft Labels berücksichtigt, das kleine Modell viel effizienter trainieren kann als mit der ursprünglichen Aufgabe.
Natürlich setzt der Ansatz der Wissensdestillation voraus, dass im großen Modell viel Redundanz vorhanden ist, so dass ein kleineres Modell mit weniger Parametern eine ähnliche Leistung erzielen kann. Insbesondere wenn Sie GPT-3 nur für eine sehr spezifische Aufgabe verwenden wollen, benötigen Sie wahrscheinlich nicht alle in den vielen Parametern gespeicherten Kenntnisse, und Sie können die Größe des Modells ohne gravierende Leistungseinbußen verkleinern.
Switch Transformers
Wissensdestillation hilft bei der Verkleinerung großer Sprachmodelle und ist manchmal notwendig, um sie für praktische Zwecke nutzbar zu machen. Das ändert aber nichts an der Tatsache, dass die Erhöhung der Modellgröße (d.h. der Anzahl der Parameter) sich als Schlüsselfaktor für die Verbesserung der Leistung erwiesen hat (siehe z.B. hier). Allerdings gibt es offensichtlich Möglichkeiten, diese Parameter effizienter zu nutzen als GPT-3 (im Hinblick auf die Rechenkosten).
Anfang dieses Jahres stellte Google eine Variante der klassischen Transformer-Architekturen vor, bei der für jeden Trainings- und Vorhersagelauf nur eine Teilmenge der Modellparameter verwendet wird. Die Idee dahinter ist, dass für jede einzelne Eingabe nur ein kleiner Teil der Parameter des Modells aktiv sein muss, um sie zu verarbeiten. Bildlich gesprochen, enthält das Modell verschiedene Experten, die auf bestimmte Eingabedaten spezialisiert sind. Anhand der Eingabedaten entscheidet das Modell dynamisch, welche Experten zu Rate gezogen werden - die übrigen bleiben untätig, d.h. ihre Parameter werden nicht verwendet und die entsprechenden Berechnungen entfallen. Diese Auswahl der Experten erfolgt nicht in einem ersten Schritt, sondern innerhalb jedes Switch-Transformer-Encoder-Blocks (das Gesamtmodell stapelt eine Menge davon).
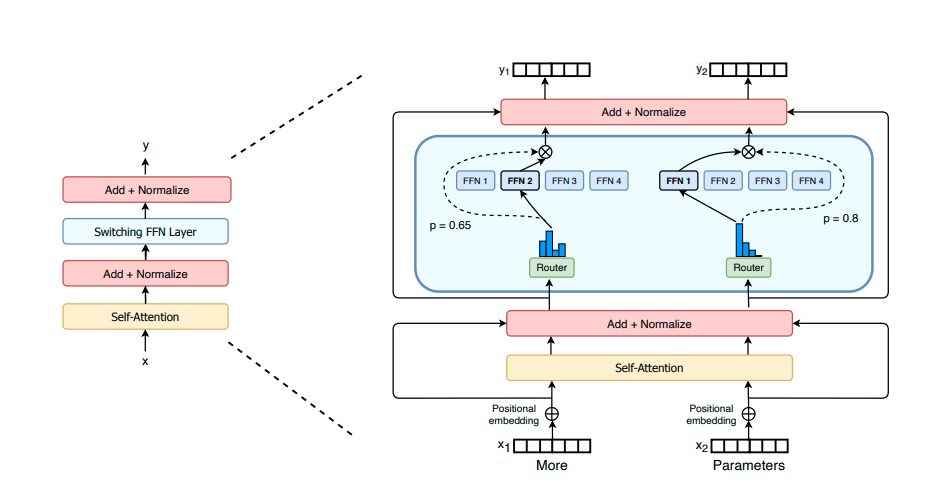
Tatsächlich entkoppeln die Switch Transformers die Rechenkosten für Training und Vorhersage von der Modellgröße und ermöglichen das Training und die Verwendung noch größerer Modelle als GPT-3. Ob eine weitere Skalierung der Modelle allerdings wirklich der richtige Weg ist, ist eine offene Frage.
Sprachmodelle verstehen Sprache nicht (oder doch?)
Es gibt mehrere Aufgaben der natürlichen Sprachverarbeitung, bei denen GPT-3 weit vom Stand der Technik entfernt ist, z.B. bei der Übersetzung. Für einige dieser Aufgaben kann man argumentieren, dass dies auf die Zusammensetzung der Trainingsdaten zurückzuführen ist. Zum Beispiel enthält nur eine kleine Teilmenge der Trainingsdaten Deutsch-Englisch-Übersetzungen. Daher könnte die Leistung wahrscheinlich verbessert werden, indem mehr Übersetzungsbeispiele hinzugefügt werden, was bedeutet, dass die Lücke zum Stand der Technik möglicherweise geschlossen werden könnte.
Es gibt jedoch einige tiefer gehende Probleme mit GPT-3, die nicht auf die Zusammensetzung oder die Menge der Trainingsdaten zurückzuführen sind, sondern mit der Trainingsaufgabe der Sprachmodellierung zusammenhängen. Sprachmodelle lernen, Sprache als ein Spiel von formalen Symbolen zu behandeln, die nach bestimmten Regeln verkettet werden können. Zu diesen Regeln gehören semantische Beziehungen zwischen Wörtern (z. B. dass Orange und Zitrone irgendwie ähnlich sind), weshalb man manchmal sagt, dass Sprachmodelle auch etwas über die Bedeutung von Wörtern lernen. Es ist jedoch wichtig, sich klar zu machen, was sie niemals lernen werden, weil es bei der Trainingsaufgabe gar nicht zum Tragen kommt: Dass Wörter, Sätze und Text im Allgemeinen auf etwas außerhalb des Textes verweisen, nämlich auf Dinge/Ereignisse/Fakten, die in der Realität existieren/stattfinden/bestehen - oder zumindest möglicherweise existieren/stattfinden/bestehen könnten. Durch diese Verbindung zur Realität können Sätze wahr oder falsch und Äußerungen moralisch gut oder schlecht sein. Aber das ist nichts, was Sprachmodelle auf dem Schirm haben. Sie produzieren nur Textausgaben auf der Grundlage der Texte, auf die sie trainiert wurden, und das tun sie, indem sie den Stil und den Inhalt der Trainingsdaten nachahmen.
Es ist eine weit verbreitete Ansicht, dass Sprachmodelle aus diesen Gründen nur die Form der Sprache lernen können, nicht aber die Bedeutung, und dass sie daher nichts erlernen können, was dem menschlichen Sprachverständnis auch nur annähernd ähnelt. Dies ist keine rein philosophische Frage, sondern hat auch praktische Konsequenzen: Es scheint nämlich, dass GPT-3 bei Aufgaben, die eine gewisse praktische Vertrautheit mit der Welt erfordern, sehr schlecht abschneidet. Ein in der MIT Technology Review veröffentlichter Artikel stellt einige interessante Fälle vor, z. B. den folgenden, in dem die Promptkomplettierung von GPT-3 in fetten Buchstaben hervorgehoben ist (hier und im Folgenden meine Übersetzung des englischsprachigen Originals):
Du hast dir ein Glas Cranberrysaft eingeschüttet, aber dann hast du geistesabwesend einen Teelöffel Traubensaft hineingeschüttet. Es sieht ok aus. Du versuchst, daran zu riechen, aber du bist stark erkältet und kannst nichts riechen. Du bist sehr durstig. Also trinkst du es.
Jetzt bist du tot.
.jpg)
Die Autoren erklären den Irrtum von GPT-3 wie folgt:
Im Beispiel mit dem Cranberrysaft fährt GPT-3 mit dem Satz "Jetzt bist du tot." fort, weil dieser Satz (oder etwas Ähnliches) oft auf Sätze wie "... kannst nichts riechen. Du bist sehr durstig. Also trinkst du es." folgt. Ein wirklich intelligenter Akteur würde etwas ganz anderes tun: Er würde Schlussfolgerungen über die potenzielle Sicherheit des Mischens von Cranberrysaft mit Traubensaft ziehen.
Die Grenzen von Sprachmodellen haben auch sehr ernste ethische Auswirkungen: Sprachmodelle könnten in den Trainingsdaten vorhandene Voreingenommenheiten (z. B. rassistische Vorurteile) verewigen. Da wir diesen Implikationen einen eigenen Blogbeitrag widmen werden, werde ich hier nicht weiter auf die ethische Dimension eingehen.
Natürlich gibt es auch gegenteilige Ansichten, die entweder die These bestreiten, dass Sprachmodelle kein richtiges Sprachverständnis erwerben, oder bestreiten, dass es sehr schwerwiegende praktische Auswirkungen hätte, wenn sie dies tatsächlich nicht täten (dieser Blogartikel, der eine Twitter-Debatte zusammenfasst, vermittelt einen guten Eindruck von den jeweiligen Argumenten). Für die zweite Art von Einwand vgl. Bender und Koller 2020, in dem die Autoren ein Gedankenexperiment verwenden, um auf scheinbar grundlegende Mängel von Sprachmodellen hinzuweisen. Bender und Koller vergleichen GPT-2 mit einem hyperintelligenten Tiefseekraken, der gelernt hat, ein Unterwasserkommunikationskabel anzuzapfen und beginnt, sich in Gespräche einzuschalten. Sie behaupten, ihr Argument impliziere, dass Sprachmodelle niemals in der Lage sein werden, selbst einfache arithmetische Probleme zu lösen (siehe Seite 5198):
[...] lassen wir GPT-2 das einfache arithmetische Problem Drei plus fünf ist gleich vervollständigen. [...] dieses Problem übersteigt die derzeitigen Fähigkeiten von GPT-2 und, so würden wir argumentieren, jedes reinen Sprachmodells.
Aber GPT-3 hat inzwischen bewiesen, dass es in der Lage ist, einstellige Additionsprobleme zu lösen.
Symbol Grounding: Verschmelzung von NLP und Computer Vision
Der Chefwissenschaftler von OpenAI, Ilya Sutskever, formulierte Folgendes in seinen Wünschen für 2021:
[T]ext allein kann viele Informationen über die Welt ausdrücken, aber er ist unvollständig, weil wir auch in einer visuellen Welt leben. Die nächste Generation von Modellen wird in der Lage sein, Bilder als Reaktion auf Texteingaben zu bearbeiten und zu erzeugen, und hoffentlich werden sie Texte aufgrund der vielen Bilder, die sie gesehen haben, besser verstehen.
Diese Fähigkeit, Text und Bilder gemeinsam zu verarbeiten, dürfte die Modelle intelligenter machen. Menschen sind nicht nur dem ausgesetzt, was sie lesen, sondern auch dem, was sie sehen und hören. Wenn man Modelle mit Daten konfrontiert, die denen ähnlich sind, die der Mensch aufnimmt, sollten sie Konzepte auf eine Weise lernen, die der des Menschen ähnlicher ist.

CLIP zeigt bereits, wie dies aussehen kann. Die Hoffnung ist, dass Bilder den Modellen beibringen, dass sich Sprache auf etwas bezieht, das über den Text hinausgeht, z. B. dass sich das Wort "Ball" auf Objekte einer bestimmten Form bezieht, die in einigen Bildern vorkommen. Sobald solche Verbindungen hergestellt sind, d. h. die sprachlichen Symbole "geerdet" sind, kann das Wissen über die Beziehungen zwischen den Objekten das Modell darüber informieren, wie die entsprechenden Wörter zusammenhängen, und seine Leistung bei NLP-Aufgaben verbessern.
Jüngste Fortschritte
Obwohl wahrscheinlich immer noch das bekannteste, ist GPT-3 nicht mehr das größte und leistungsstärkste Sprachmodell. Erst vor wenigen Tagen haben NVidia und Microsoft Megatron-Turing NLG 530B veröffentlicht, das etwa dreimal so groß ist wie GPT-3 - ein Beispiel für den Brute-Force-Ansatz (zumindest aus der Sicht des maschinellen Lernens), bei dem Fortschritte durch eine weitere Vergrößerung der Modelle erzielt werden.
Aber es geht noch größer: Im Sommer stellte die Beijing Academy of Artificial Intelligence (BAAI) Wu Dao 2.0 vor, das zehnmal so viele Parameter wie GPT-3 enthält. Die BAAI verrät nicht viele Details zu den Datensätzen, dem Training und den möglichen Anwendungen, aber es ist bekannt, dass es sowohl Switch Transformers als auch den oben beschriebenen Symbol-Grounding-Ansatz verwendet - in der Tat verwendet es 3 Terabyte Text- und 90 Terabyte Bilddaten.
FLAN ist ein fine-getuntes Sprachmodell, das durch Instruction Tuning gewonnen wurde und von Google vor etwa zwei Wochen vorgestellt wurde. Anstatt ein Modell nur auf der Sprachmodellierungsaufgabe zu trainieren, werden natürlichsprachliche Anweisungen (als Prompts) verwendet, um gelabelte Datensätze für bestimmte NLP-Probleme für zusätzliches Training zur Verfügung zu stellen. Für einen NLI-Datensatz sieht das wie folgt aus, wobei die Vorlagen verschiedenen Möglichkeiten entsprechen, die Anweisung in einen Prompt umzuwandeln:
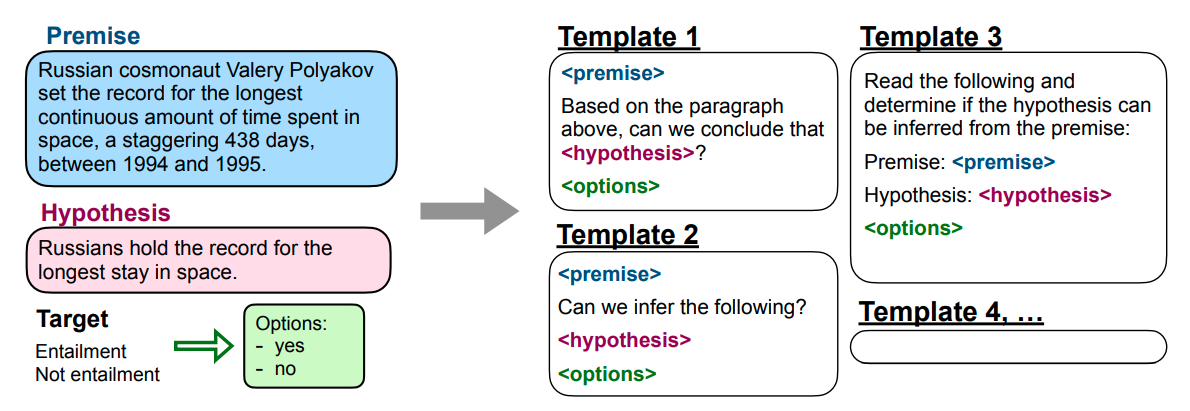
Es stellt sich heraus, dass der FLAN mit Instruction Tuning GPT-3 vor allem in einem Zero-Shot-Setting übertrifft (bei der Evaluation werden natürlich Aufgaben berücksichtigt, auf die FLAN nicht finegetunt wurde).
GPT-3 mit Reinforcement Learning: InstructGPT
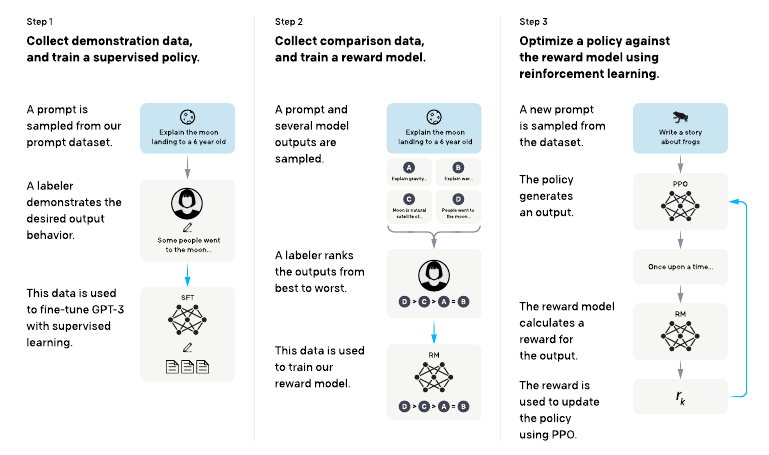
GPT-3 wurde auf die klassische Sprachmodellierungsaufgabe "Vorhersage des nächsten Wortes" trainiert. Seine interessantesten Anwendungen sind jedoch vom Typ "Text entsprechend der gegebenen Anweisung generieren". Daher könnte es sinnvoll sein, GPT-3 auf die tatsächlichen Aufgaben abzustimmen, damit es besser mit den Absichten der Benutzer übereinstimmt. Genau das hat OpenAI mit InstructGPT getan: Sie haben einen Datensatz von anweisungsähnlichen Prompts zusammen mit Beispielen für die vom Benutzer gewünschten Ergebnisse zusammengestellt und für das Fine-Tuning verwendet. Dann gingen sie sogar noch einen Schritt weiter: Sie wendeten Reinforcement Learning an, um InstructGPT beizubringen, die von den Nutzern gewünschten Ergebnisse zu produzieren. Um das für das Reinforcement Learning notwendige Feedback (d.h. die Belohnung) zu erhalten, trainierten sie ein Belohnungsmodell. Diesem Modell wird beigebracht, eine Reihe möglicher Outputs für einen bestimmten Prompt vom besten zum schlechtesten zu ordnen.
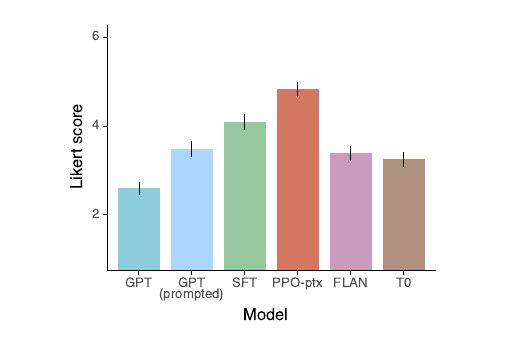
Labeler bevorzugten die Outputs von InstructGPT für anweisungsähnliche Prompts gegenüber denen von GPT-3, FLAN und T0 :
Fazit
Wir haben gesehen, dass große Sprachmodelle unter exorbitanten Rechenanforderungen und möglicherweise sehr grundlegenden Einschränkungen leiden. Gleichzeitig wurden Ansätze vorgeschlagen und werden derzeit erprobt, die diese Probleme abmildern könnten.
Auch wenn der Hype um GPT-3 vielleicht übertrieben war und über die fortbestehenden Unzulänglichkeiten hinwegtäuscht, so kann man doch mit Sicherheit sagen, dass der Erfolg der Transformer-basierten Sprachmodelle eine neue Ära im Bereich NLP eingeleitet hat.
Kontakt
Wenn Sie mit uns über dieses Thema sprechen möchten, kontaktieren Sie uns gerne und wir melden uns im Anschluss für ein unverbindliches Erstgespräch.