
Ensembles in Machine Learning: Combining Multiple Models

In the ever-evolving landscape of machine learning, the quest for improved predictive accuracy has led to the development of ensemble methods. These techniques harness the collective power of multiple models to achieve better performance than any single model could on its own. This article delves into ensemble learning, exploring how the combination of diverse algorithms can lead to more robust, generalizable, and accurate machine learning solutions.
Note: If you are interested in a 30min conversation with one of our Machine Learning experts regarding the topic of ensembles in machine learning, please take a look at our ML expert talk offering.
What does ensemble mean in machine learning?
In machine learning, an ensemble refers to a collection of multiple models that work together to make a prediction or classification. The idea is to combine the strengths of individual models to improve overall performance and reduce errors. By aggregating the outputs of multiple models, an ensemble often achieves better predictive performance than any single model within the ensemble.
Simple Analogy
The concept of ensemble learning can be understood through a simple analogy. Imagine you are trying to solve a complex problem, and you have several experts at your disposal. Each expert has their own area of expertise and approach to problem-solving. If you were to ask each of them for a solution and then combine their insights, the resulting solution would likely be more accurate and well-rounded than relying on a single expert. In machine learning, each "expert" is a predictive model trained on your data.
Ensemble Techniques
There are several techniques for creating ensembles, and they can be broadly categorized into three types: bagging, boosting, and stacking.
Bagging
Bootstrap aggregating, commonly known as bagging, is a method that merges the concepts of bootstrapping and aggregation to create a unified ensemble model. This approach involves generating multiple subsets from a data sample, each of which is a bootstrapped replica. On each subset, an individual decision tree is constructed. Once all the decision trees are created from the subsamples, they are then combined through a specific algorithm that integrates their outputs to establish the most effective prediction model.
Bagging adopts the bootstrap distribution for generating different base learners. In other words, it applies bootstrap sampling to obtain the data subsets for training the base learners.
— Zhi-Hua Zhou, "Ensemble Methods: Foundations and Algorithms"
Boosting
Boosting, on the other hand, focuses on training models sequentially, where each new model tries to correct the errors made by the previous ones. Algorithms like AdaBoost and Gradient Boosting are examples of boosting methods. They start with a weak model and iteratively add more models, adjusting the weights of instances that were misclassified by the previous models, aiming to improve the performance incrementally.
The learning algorithm adjusts its focus on the training data by giving more weight to examples that are difficult to predict, effectively learning from the mistakes of earlier models. Boosting was theoretically proposed before it was practically successful, with the AdaBoost algorithm marking its first effective implementation. Since then, boosting has evolved, with techniques like Gradient Boosting Machines and Stochastic Gradient Boosting (such as XGBoost) becoming some of the most powerful methods for handling structured data.
Stacking
Stacking ensemble learning, also known as stacked generalization, is a method that combines multiple different predictive models to improve the overall performance. The approach involves training multiple first-level models, or base learners, on the same data and then using a second-level model, or meta-learner, to synthesize their predictions.
The meta-learner is trained to determine the best way to combine the base learners' predictions, effectively learning from their diverse strengths. This technique allows for the use of various types of machine learning algorithms as base learners, which contributes to a rich diversity in the ensemble and typically results in fewer correlated errors. Stacking is recognized for its ability to harness the predictive power of multiple models and is the foundation for many advanced ensemble techniques.
For example, you could train a decision tree, a support vector machine, and a neural network, and then use a meta-model, such as logistic regression that is used to combine their predictions. The meta-model effectively learns the best way to blend the strengths and predictions of each base model to improve the final prediction accuracy, which can lead to better performance than any of the individual models could achieve on their own.
Why do we use ensemble in machine learning?
One of the most compelling reasons for using ensemble methods is their ability to reduce overfitting, a common problem in machine learning where a model performs well on the training data but poorly on new, unseen data. By aggregating the predictions of multiple models, ensemble methods can smooth out the biases and reduce the variance, leading to a more generalized model. This is particularly useful in applications where the cost of making an incorrect prediction is high, such as in medical diagnosis or the banking and finance industry.
Furthermore, In machine learning, the performance of a model can be decomposed into three components: bias, variance, and irreducible error.
Bias refers to the error due to overly simplistic assumptions in the learning algorithm. High bias can cause the model to miss relevant relations between features and target outputs, leading to underfitting. On the other hand, variance refers to the error due to too much complexity in the learning algorithm. High variance can cause overfitting, where the model learns the random noise in the training data.
Ensemble methods, particularly those that involve randomization like bagging and random forests, offer a way to navigate this trade-off more effectively. By combining multiple models, ensemble methods can increase the bias slightly but often reduce the variance significantly. The key here is the correlation between the models. If the models are uncorrelated, the ensemble can significantly reduce variance without a substantial increase in bias, leading to a more robust model. The amount of randomness introduced in ensemble methods serves as a control knob for this bias-variance trade-off. Too much randomness might increase the bias, while too little randomness might not allow the ensemble to reduce the variance effectively.
When you combine these models into an ensemble, these different errors can cancel each other out, leading to a more robust and accurate model overall. This is where the concept of "variance reduction" comes into play. Variance is essentially how much your model's predictions would change if you used a different training dataset. By introducing randomness, each individual model's predictions are less correlated with each other, which means they are likely to have different variances. When you average these predictions together in an ensemble, the variances also average out, leading to a model with lower overall variance.
Are Ensembles in Machine Learning the Future?
Ensemble methods could be considered the future of machine learning for several reasons.
First, they offer a way to improve model performance without requiring new, more complex algorithms. By combining existing models, ensemble methods often achieve higher accuracy and better generalization to new data. This is crucial for applications where high predictive accuracy is required, such as in healthcare diagnostics, financial forecasting, and autonomous vehicles.
Second, ensemble methods are highly adaptable. They can be applied to both classification and regression problems, and they can incorporate various types of models. This flexibility makes them suitable for a wide range of applications and allows them to adapt to the evolving landscape of machine learning algorithms. As new models are developed, they can easily be incorporated into existing ensembles, thereby continually improving performance.
Third, ensemble methods are particularly good at handling diverse and large datasets. In the era of big data, where datasets can be massive and highly dimensional, ensemble methods can offer a way to make sense of this complexity. They can handle different types of features, missing values, and outliers, making them robust against the many challenges that large datasets present.
Lastly, ensemble learning methods are inherently parallelizable, allowing them to be trained on multiple processors, across multiple machines, or even on multiple distributed machines in environments like Bittensor. By distributing the model inference tasks across a network ensemble methods can perform simultaneous processing. This not only maximizes the efficiency of resource utilization but also aligns with the trend toward more decentralized and collaborative computational frameworks. The parallel nature of ensemble methods makes them particularly well-suited for complex computations that benefit from the robustness and collective intelligence of multiple models working in concert.
What is an example of ensemble learning?
Random Forest Algorithm
One classic example of ensemble learning is the Random Forest algorithm. A Random Forest is an ensemble of Decision Trees, generally trained via the bagging method. The idea is simple yet powerful: create multiple Decision Trees during training and let them vote for the most popular class (or average the results for regression problems) to make a prediction.
In a Random Forest, each Decision Tree is built on a subset of the data, and at each node, a random subset of features is considered for splitting. This introduces diversity among the individual trees, making the ensemble more robust and less prone to overfitting. When a new data point needs to be classified, it is run down each Decision Tree. Each tree gives its own classification, and the class that receives the majority of votes becomes the ensemble's prediction.
The Random Forest algorithm is widely used in both classification and regression tasks. It's known for its simplicity and the fact that it can achieve high accuracy with minimal hyperparameter tuning, making it a good choice for many practical machine-learning problems.
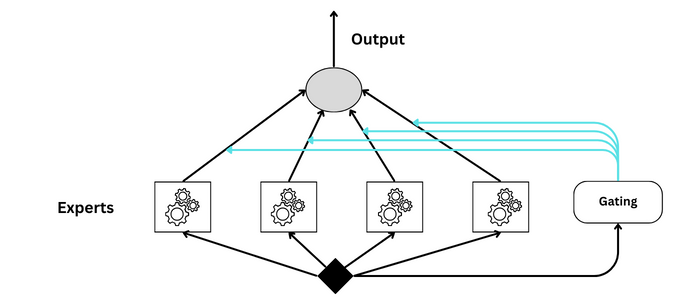
Mixture of Experts
A Mixture of Experts (MoE) is another ensemble example, but it differs from methods like Random Forests or Boosting in its architecture and the way it combines different models. The Mixture of Experts consists of two main components: the "experts," which are individual models trained to make predictions, and a "gating network," which determines how much weight to give to each expert's prediction when making the final prediction.
GPT
While OpenAI has not publicly detailed the use of MoE in GPT-4, the concept aligns well with the goals of creating more adaptable and capable AI systems. By leveraging a diverse set of specialized models, a GPT model with MoE could provide more accurate, contextually appropriate, and nuanced responses across a broader range of topics and languages than a single, monolithic model.
The MoE approach represents a step towards more modular and interpretable AI systems, where the contributions of individual components to the final output are clearer. This could also facilitate debugging and improvement of AI models, as each expert can be independently analyzed and fine-tuned. As AI continues to advance, techniques like MoE could be pivotal in managing the increasing complexity and capability of models like GPT.
Conclusion
In summary, ensemble methods stand out as a significant milestone in the machine learning landscape, offering a synergistic strategy that often surpasses the performance of individual models. By pooling together diverse algorithms, ensemble learning not only strengthens predictive accuracy but also enhances the generalizability of models. This article has traversed the spectrum of ensemble techniques bagging, boosting, and stacking each contributing uniquely to the robustness of machine learning solutions. As we look towards the future, ensemble methods continue to promise advancements in AI, poised to tackle the complexities of big data and the nuances of real-world problem-solving. For practitioners and researchers alike, embracing these techniques could very well be the key to unlocking new levels of AI potential.
Frequently Asked Questions
Is SVM an ensemble algorithm?
Support Vector Machine (SVM) is not considered an ensemble learning method because it does not combine multiple models to make a prediction. Ensemble methods like bagging, boosting, or stacking rely on aggregating the outputs of multiple base learners to improve predictive performance. In contrast, SVM is a single model that works by finding the optimal hyperplane to separate different classes in the feature space. It does not involve the combination of multiple models or any form of model averaging or voting, which are the hallmarks of ensemble learning.
Why is ensemble learning better than machine learning?
Ensemble learning is not inherently "better" than machine learning; rather, it is a specialized technique within the broader field of machine learning. The primary advantage of ensemble learning is its ability to improve the predictive performance of a model by combining multiple weaker models to create a stronger one. This often results in a model that generalizes better to new, unseen data, thereby reducing the likelihood of overfitting.
Contact
If you would like to speak with us about this topic, please reach out and we will schedule an introductory meeting right away.