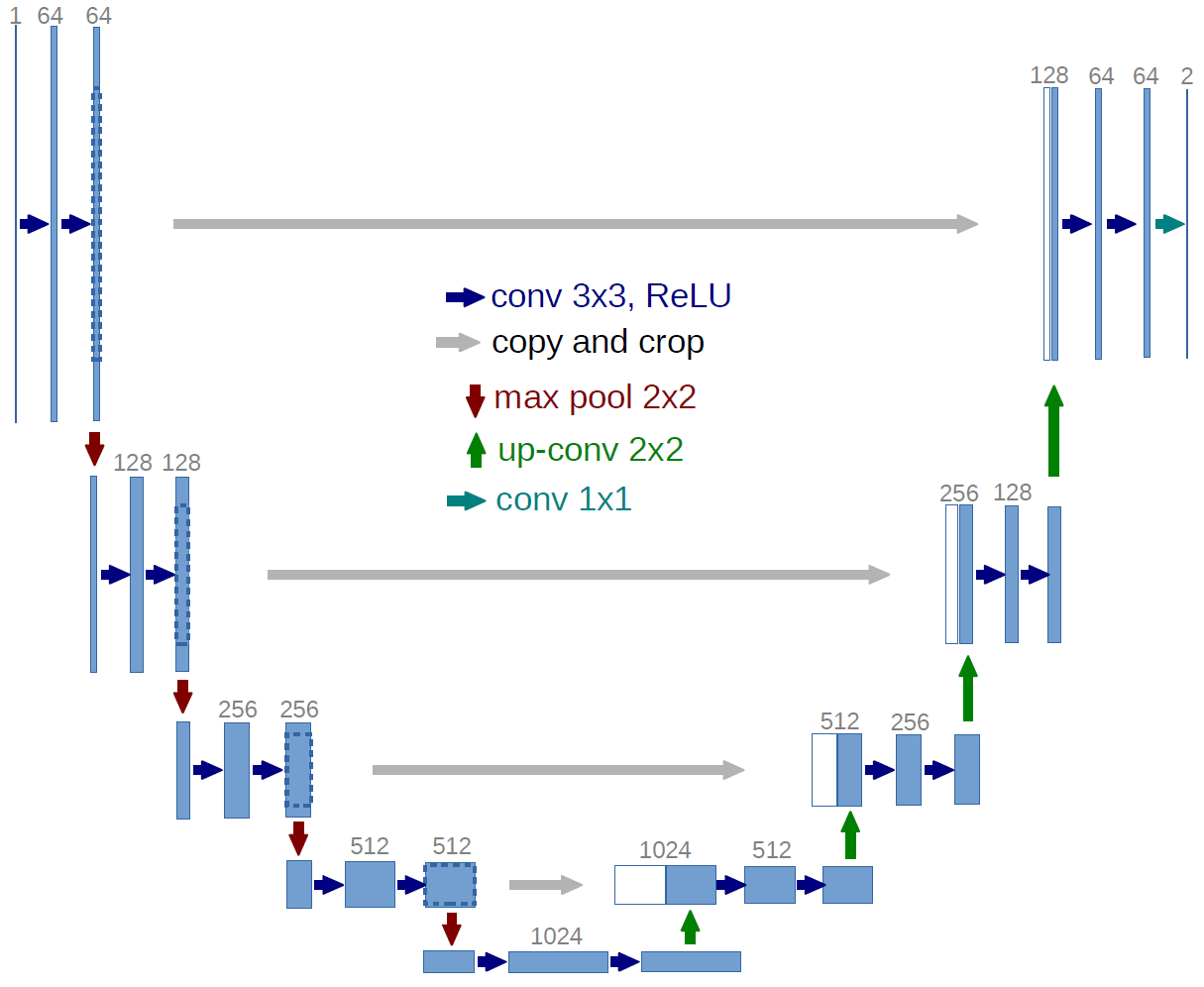
We decided to tackle the challenge as a semantic segmentation task, i.e. we wanted to develop a model that predicts for each pixel of a given satellite image whether it belongs to an ASM or not.
First of all, we had to get a labeled data set.
Data and labeling
For training purposes, we used images from the Planet Scope satellite:
In total, we identified and labeled ASM sites in ~100 satellite images. Because of the difficulty of the task the labels had to be provided by an expert from RWTH Aachen. Since the original images were huge, we chopped them into smaller patches before feeding them into the segmentation model, so that the training data set consisted of more than 15,000 labelled images, 256-by-256 pixels each.
To make both the annotator's and the model's job easier, we computed two more channels from the four already existing ones:
The normalized difference water index (NDWI) was computed as