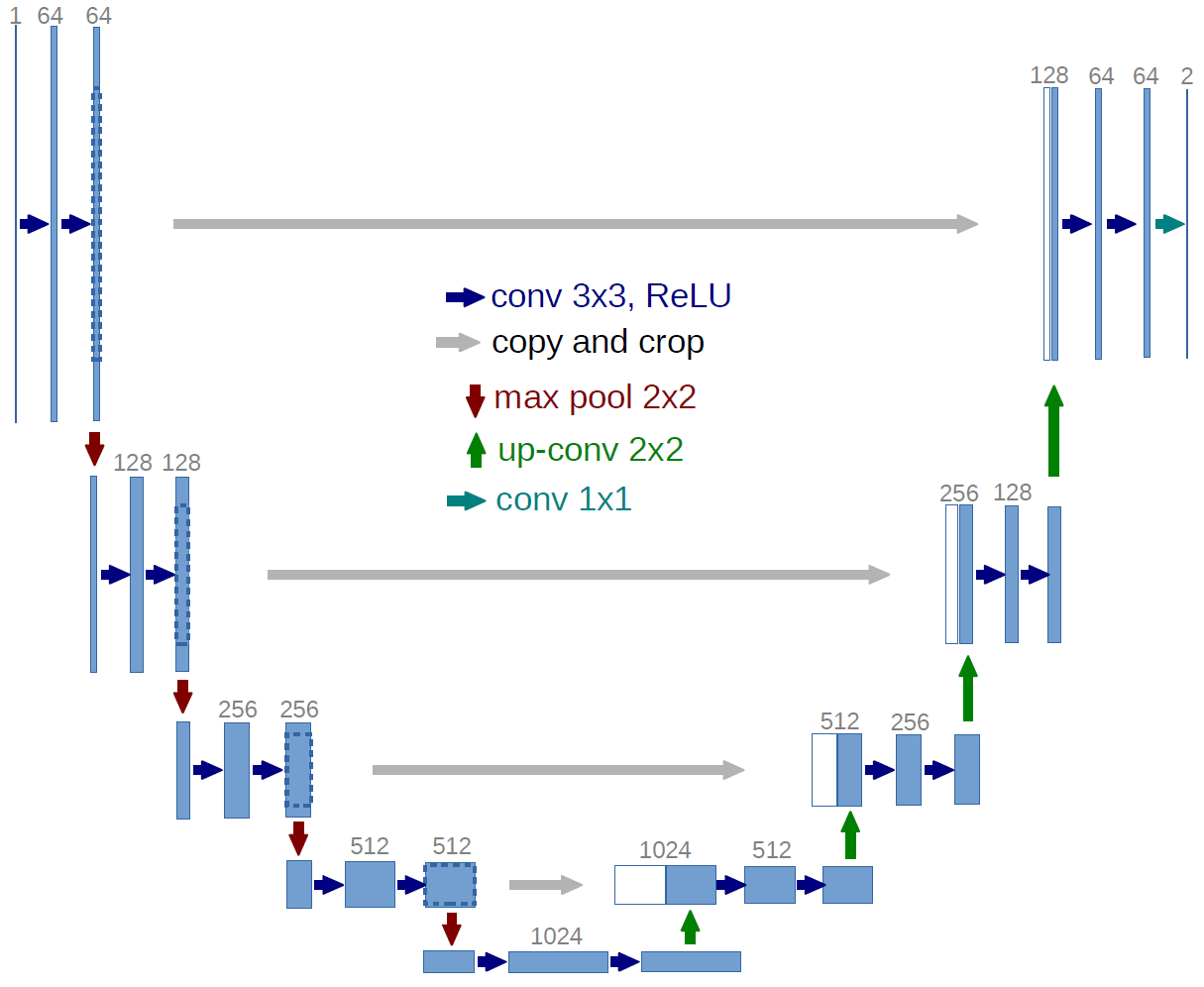
Wir beschlossen, die Herausforderung als eine semantische Segmentierungsaufgabe anzugehen, d.h. wir wollten ein Modell entwickeln, das für jedes Pixel eines gegebenen Satellitenbildes vorhersagt, ob es zu einer ASM gehört oder nicht.
Zunächst einmal mussten wir einen mit Labels versehenen Bild-Datensatz erstellen.
Daten und Labeling
Zu Trainingszwecken verwendeten wir Bilder des Satelliten Planet Scope:
Insgesamt haben wir in ~100 Satellitenbildern ASM-Standorte identifiziert und annotiert. Wegen der Schwierigkeit der Aufgabe mussten die Labels von einem Experten der RWTH Aachen erstellt werden. Da die Originalbilder riesig waren, zerlegten wir sie in kleinere Ausschnitte, bevor wir sie in das Segmentierungsmodell einspeisten, so dass der Trainingsdatensatz aus mehr als 15.000 mit Labels versehenen Bildern mit einer Größe von jeweils 256 x 256 Pixeln bestand.
Um sowohl dem Labeler als auch dem Modell die Arbeit zu erleichtern, berechneten wir aus den vier bereits vorhandenen Kanälen zwei weitere:
Der Normalisierte Differenz-Wasserindex (NDWI) wurde berechnet als