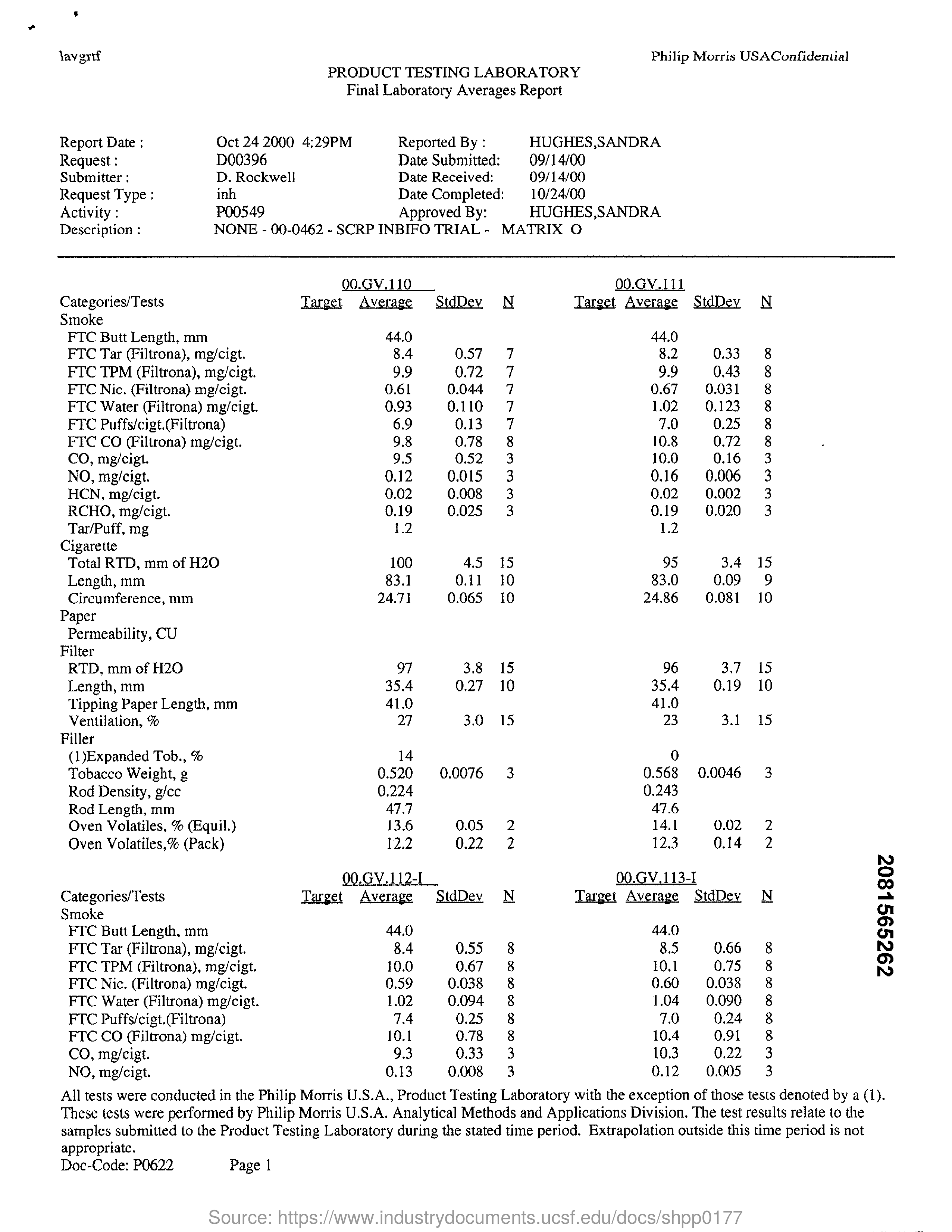
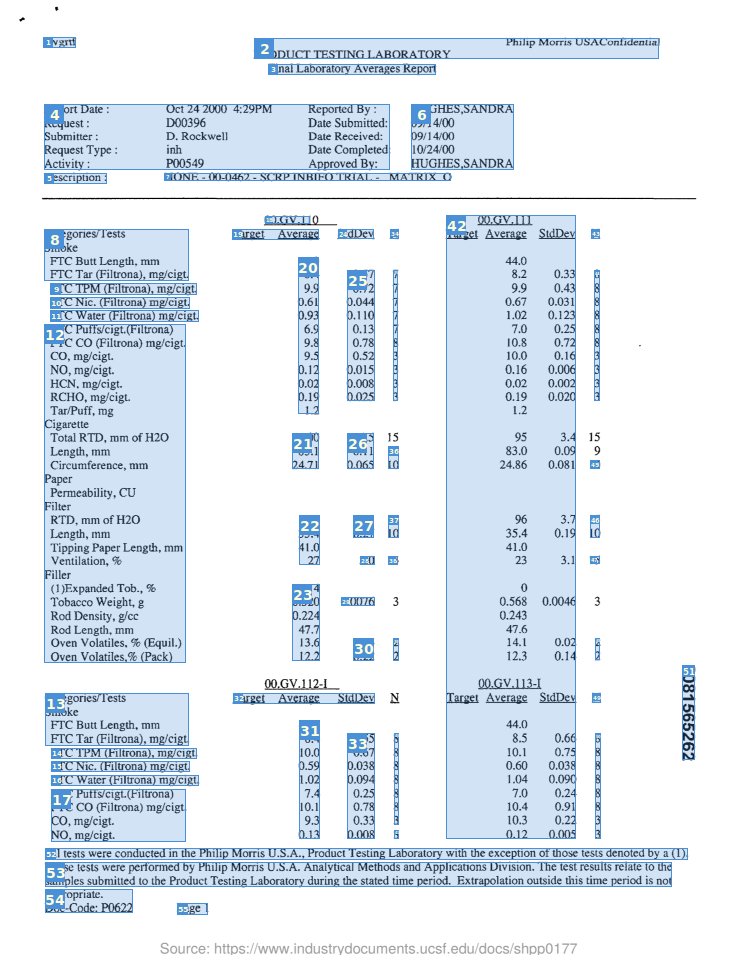
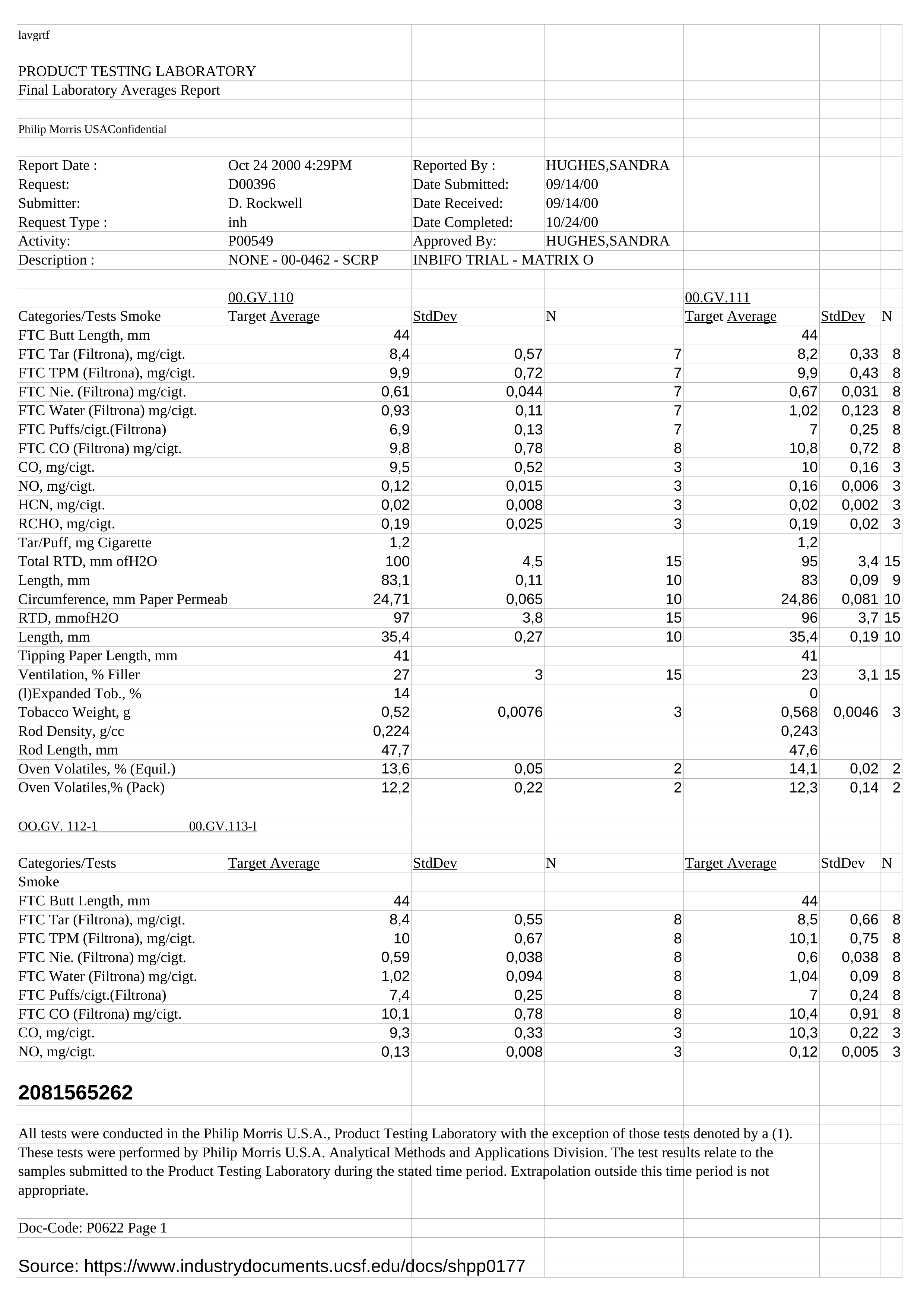
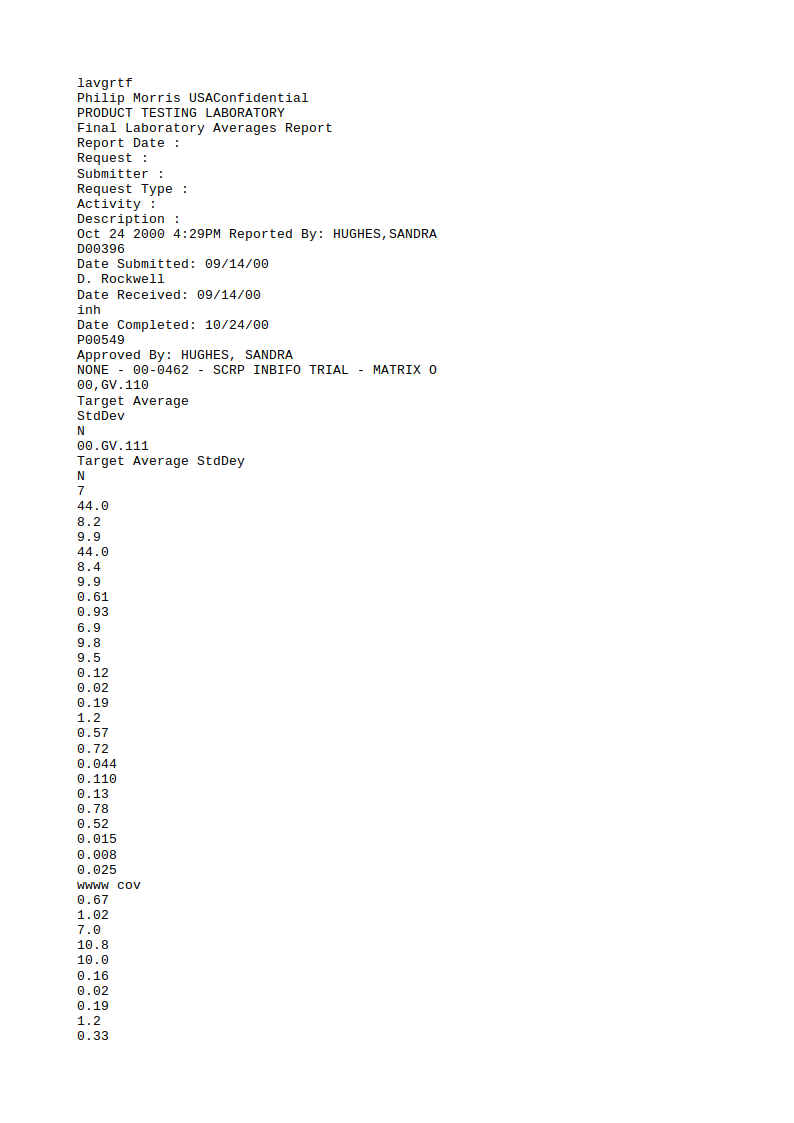
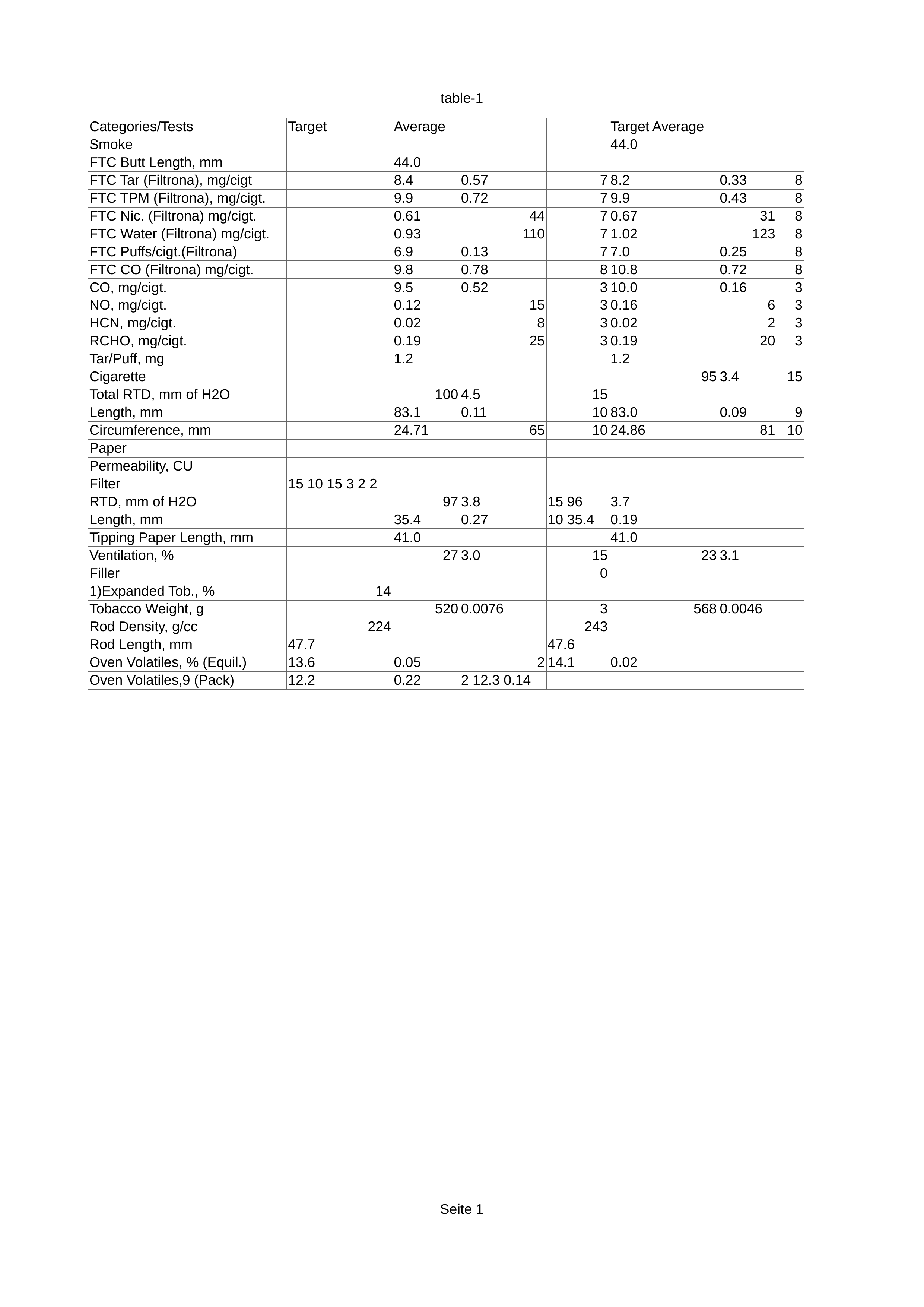
Google does well on the scanned email and recognizes the text in the smartphone-captured document similarly well as ABBYY. However it is much better than Tesseract or ABBYY in recognizing handwriting, as the second result image shows: still far from perfect, but at least it got some things right. On the other hand, Google Cloud Vision doesn't handle tables very well: It extracts the text, but that's about it.
In fact, the original Cloud Vision output is a JSON file containing information about character positions. Just as for Tesseract, based on this information one could try to detect tables, but again, this functionality is not built in.
Note that there is also a Google Document Understanding AI beta version out now, which we haven't tested as of this point.