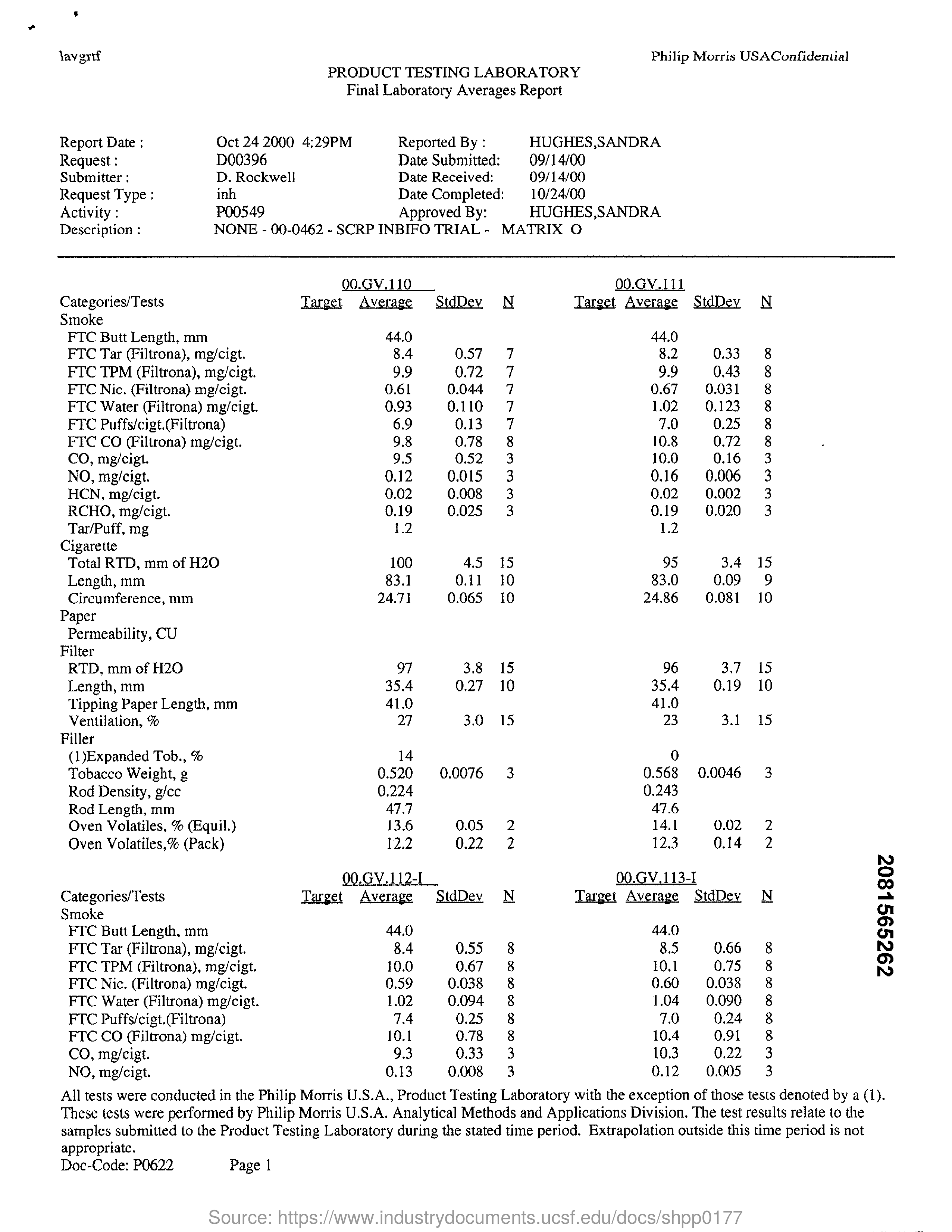
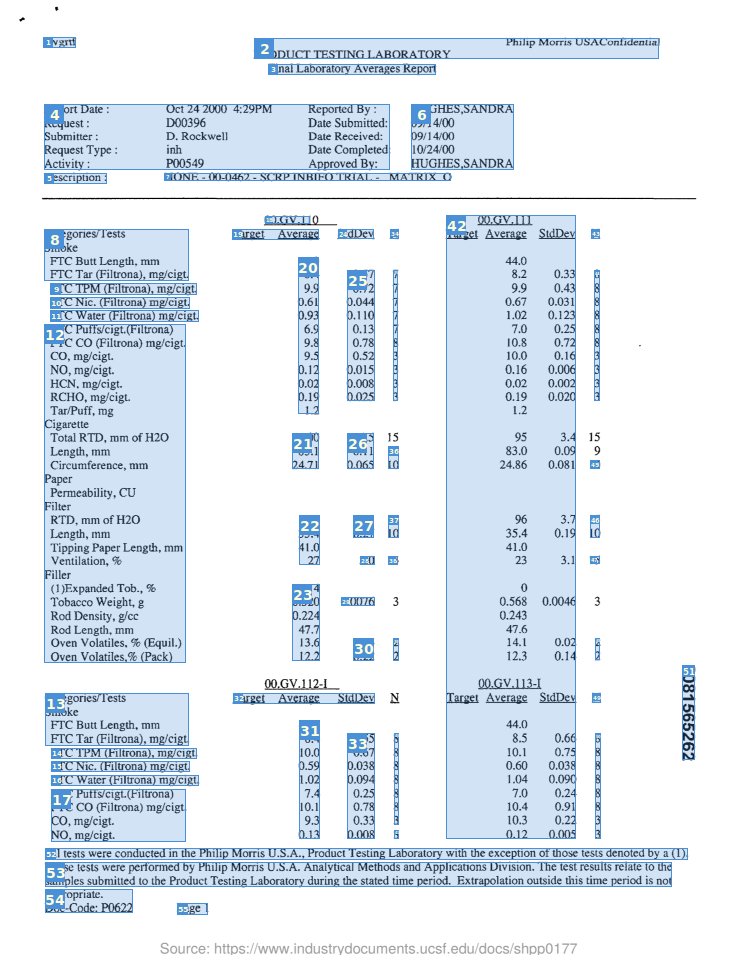
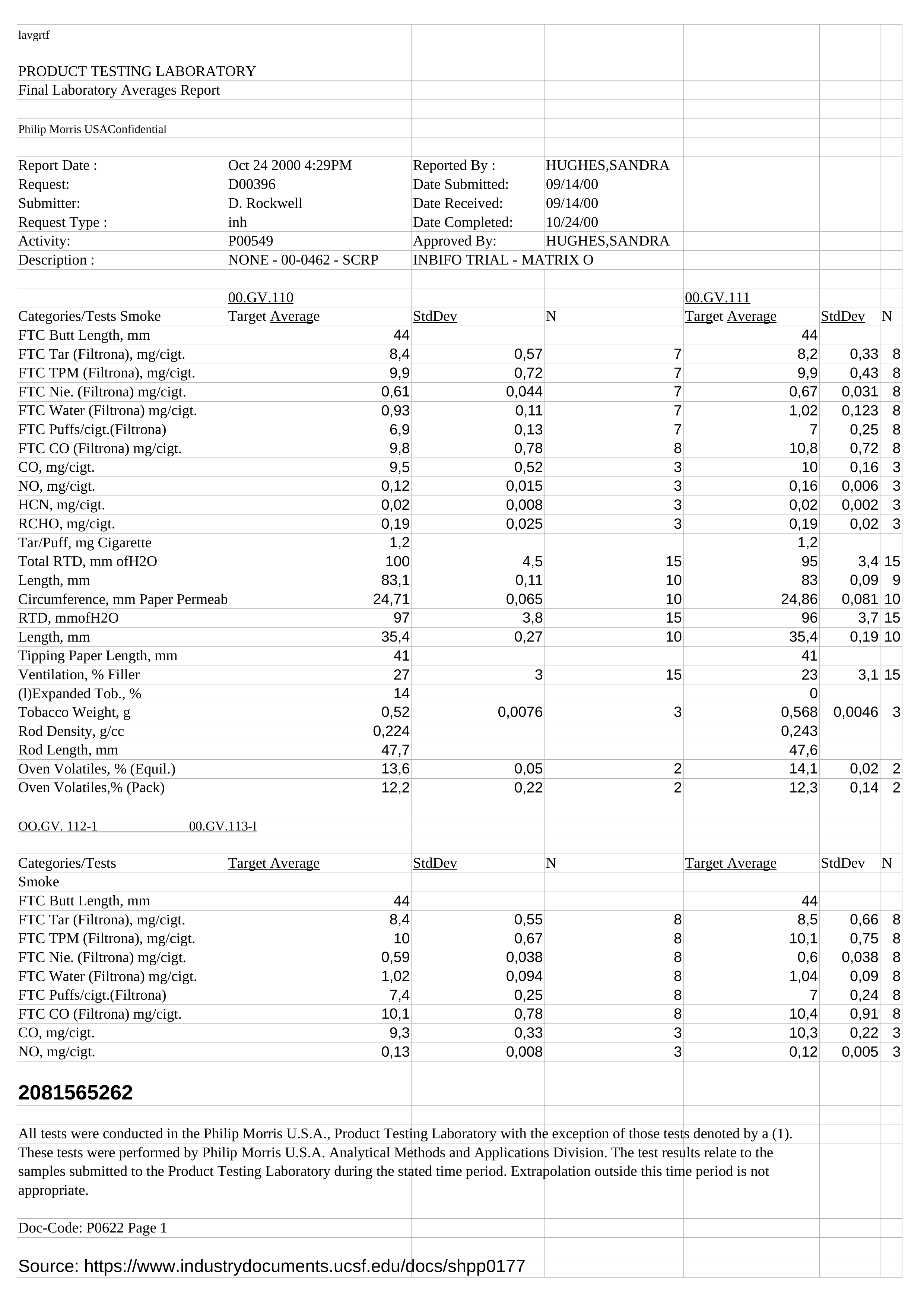
Die optische Zeichenerkennung (kurz: OCR) hat die Aufgabe, Text automatisch aus Bildern zu extrahieren (die in typischen Bildformaten wie PNG oder JPG vorliegen können, aber auch als PDF-Datei). Heutzutage gibt es eine Vielzahl von Werkzeugen und Diensten zu Texterkennung, die einfach zu bedienen sind und diese Aufgabe zu einem Kinderspiel machen. In diesem Blogbeitrag werde ich vier der beliebtesten Tools vergleichen:
Tesseract-OCR
ABBYY FineReader
Google Cloud-Vision
Amazon-Textrakt
Ich werde zeigen, wie man sie einsetzt und ihre Stärken und Schwächen auf der Grundlage ihrer Leistung bei einer Reihe von Aufgaben bewerten kann. Nach der Lektüre dieses Artikels werden Sie in der Lage sein, ein OCR-Tool auszuwählen und anzuwenden, das den Anforderungen Ihres Projekts entspricht.
Beachten Sie, dass wir uns auf die OCR nur für Dokumentenbilder konzentrieren, im Gegensatz zu Bildern, die lediglich nebenbei auch Text enthalten.