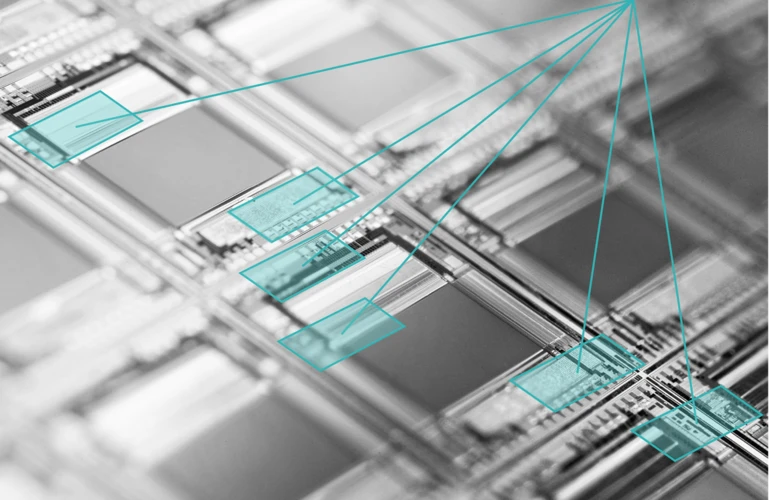
Da die Performance bestehender kommerzieller und Open-Source-Lösungen zur Tabellenextraktion in Tests nicht ausreichend war (nur 60-70% der Tabellen wurden korrekt erkannt), haben wir uns zu einer Eigenentwicklung entschlossen:
Wir nutzen ein CascadeTabNet, um Bereiche des Dokuments zu identifizieren, in denen sich Tabellen befinden. Diese Identifikation vollzieht sich ausschließlich auf der Bildebene.
Anschließend analysieren wir innerhalb dieser Bereiche die Positionen der Zeichenketten und ihre relative Anordnung zueinander, um Spalten und Reihen der Tabellen zu erkennen und ihren Inhalt strukturiert auslesen zu können.
Mithilfe dieses Ansatzes konnten wir die Genauigkeit der Tabellenerkennung auf 93% steigern.
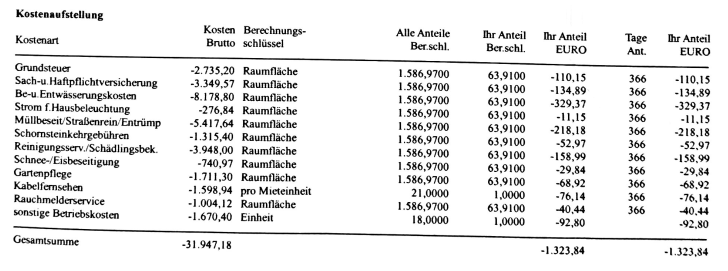
Überprüfung der Kostenpositionen
Auf Grundlage der extrahierten Tabelle lassen sich aufgeführten Kostenpositionen auslesen und bewerten. Bewertet wird, ob sie tatsächlich auf die Mieter umlegbar sind.
Aufgrund der oftmals schlechten Qualität der hochgeladenen Dokumente haben wir uns für einen Ansatz entschieden, der robust gegenüber OCR-Fehlern ist: Die einzelnen Kostenpositionen werden als Zeichenketten mit Listen
bekannter zulässiger und
bekannter unzulässiger Positionen verglichen.
Der Vergleich erfolgt über eine Fuzzy-String-Suche, welche für ein Paar zu vergleichender Zeichenketten einen Ähnlichkeitswert ausgibt:
>>> fuzz.ratio("cable fees", "cable fees") -> 100
>>> fuzz.ratio("cable fees", "cable/TV fees") -> 87
>>> fuzz.ratio("cable fees", "property tax") -> 18
Da es eine Vielzahl unterschiedlicher Algorithmen für die Fuzzy-String-Suche gibt (die unterschiedlichen Definitionen der Ähnlichkeit von Zeichenketten entsprechen), haben wir einen Machine-Learning-Classifier trainiert, um mehrere Ähnlichkeitswerte zu berücksichtigen und zu gewichten. Auf Basis der zugehörigen Ähnlichkeitswerte trifft der Classifier eine Einschätzung, ob eine gegebene Position umlegbar ist oder nicht:



.png)