
Supervised vs Unsupervised Learning
.jpg)
Supervised and unsupervised learning are fundamental concepts in the field of machine learning, playing crucial roles in the development of artificial intelligence (AI) systems. In this blog article, we will delve into the principles of supervised and unsupervised learning, providing a comprehensive understanding of their key characteristics, differences, and their respective applications within the realm of AI.
Note: If you are interested in a 30min conversation with one of our Machine Learning experts, please take a look at our free ML expert talk offering.
What is Supervised Machine Learning?
Supervised learning involves training a model using labeled data, where the desired outputs are explicitly provided. By learning from these labeled examples, the model can generalize and make predictions on new, unseen data. This learning paradigm can be likened to a learning process that occurs in the presence of a supervisor or a teacher. The labeled training data enables the supervised learning algorithm to learn patterns and relationships, ultimately allowing it to make predictions or classify new, unseen data accurately.
How does Supervised Learning work?
In supervised learning, we have a dataset consisting of input samples and corresponding output labels. The goal is to train a model that can generalize from the provided examples and accurately predict labels for unseen inputs. The process can be broken down into the following 5 key steps:
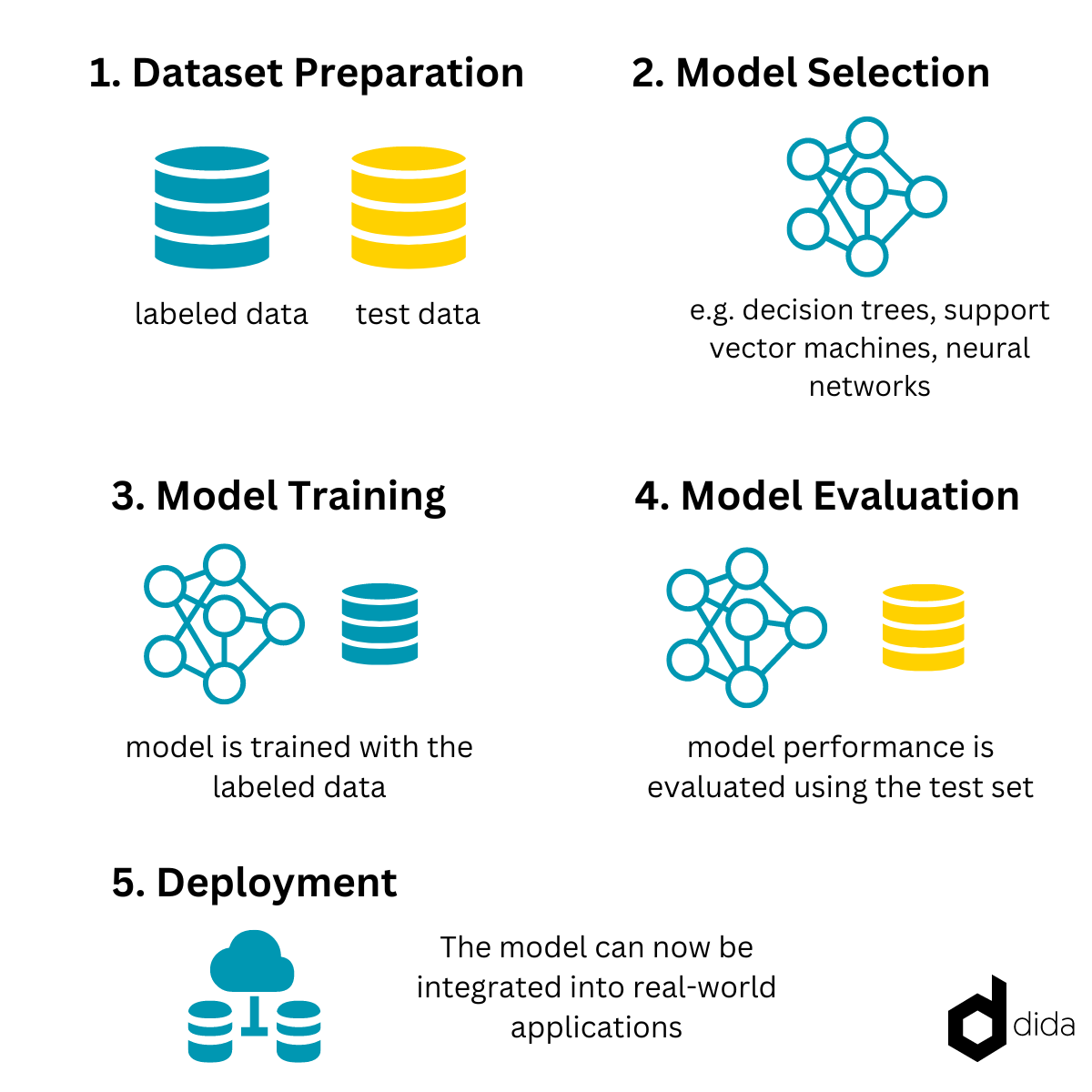
Dataset Preparation: The labeled dataset is divided into two parts: the training set and the test set. The training set is used to teach the model, while the test set is used to evaluate its performance on unseen data.
Model Selection: A suitable model architecture or algorithm is chosen based on the nature of the problem and available data. There are various algorithms to choose from, including decision trees, support vector machines, neural networks, and many others.
Model Training: The selected model is trained using the labeled examples from the training set. During training, the model learns to map input features to the corresponding output labels by adjusting its internal parameters. This adjustment is typically done through an optimization algorithm that minimizes a predefined loss or error function.
Model Evaluation: Once the model is trained, its performance is evaluated using the test set. Various evaluation metrics are used to measure the model's accuracy, such as accuracy, precision, recall, and F1-score. These metrics provide insights into how well the model generalizes to unseen data.
Deployment: If the model meets the desired performance criteria, it can be deployed to make predictions on new, unlabeled data. The model can be integrated into real-world applications to assist in decision-making or automate certain tasks.
What is Unsupervised Machine Learning?
Unsupervised machine learning allows models to uncover hidden patterns and insights from unlabeled data. Unlike supervised learning, where models learn from labeled examples, unsupervised learning enables models to identify structures and relationships within the dataset without any explicit guidance or supervision.
In unsupervised learning, the goal is to explore the underlying structure of the data, discover inherent patterns, and represent the dataset in a compressed or simplified format. Unsupervised learning models are given an unlabeled dataset and are tasked with finding meaningful representations and clusters within the data.
Supervised vs unsupervised learning compared
Supervised learning focuses on training models using existing knowledge to make accurate predictions or classifications. It relies on labeled data to learn patterns and relationships between input features and target outputs. In contrast, unsupervised learning operates on unlabeled data, allowing models to discover hidden structures and relationships autonomously. It emphasizes exploring the underlying patterns and similarities within the data without predefined guidance. While supervised learning excels at making precise predictions, unsupervised learning provides valuable insights into complex datasets, enabling data exploration, clustering, and anomaly detection.

Supervised Learning |
Unsupervised Learning |
|
Data |
Labeled data |
Unlabeled data |
Learning Task |
Predicting or classifying based on labeled examples |
Discovering patterns, structures, or relationships in the data |
Goal |
Generalization to predict labels for unseen data |
Extraction of hidden patterns, clusters, or relationships |
Algorithms |
Decision trees, support vector machines, neural networks |
Clustering, dimensionality reduction, anomaly detection |
Use Cases |
Image recognition, text classification, sentiment analysis, Fraud Detection |
Pattern Recognition in DNA Sequences, Recommendation Systems, Data Preprocessing |
Summary
To conclude, supervised and unsupervised learning are two fundamental pillars of machine learning. Supervised learning relies on labeled data to train models for accurate predictions or classifications, while unsupervised learning discovers hidden patterns in unlabeled data without explicit guidance. Both approaches have their respective applications and algorithms, such as decision trees, support vector machines, and clustering techniques. Supervised learning is useful for tasks like image recognition and fraud detection, while unsupervised learning is valuable for pattern recognition and recommendation systems. Understanding and leveraging both supervised and unsupervised learning techniques empower researchers and practitioners to tackle a wide range of real-world challenges and unlock valuable insights from their data.
Frequently Asked Questions
What is an example of unsupervised learning?
One example of unsupervised learning is clustering. Clustering algorithms aim to group similar data points together based on their intrinsic characteristics or patterns without any prior knowledge of their labels or categories. The goal is to discover inherent structures or relationships within the data.
What is easier - supervised or unsupervised learning?
Determining whether supervised or unsupervised learning is easier depends on the specific problem and data characteristics. In supervised learning, having labeled data provides explicit guidance and simplifies the learning process, making it relatively easier. In contrast, unsupervised learning relies on discovering patterns and structures in unlabeled data, which can be more challenging due to the absence of direct supervision.
Contact
If you would like to speak with us about this topic, please reach out and we will schedule an introductory meeting right away.