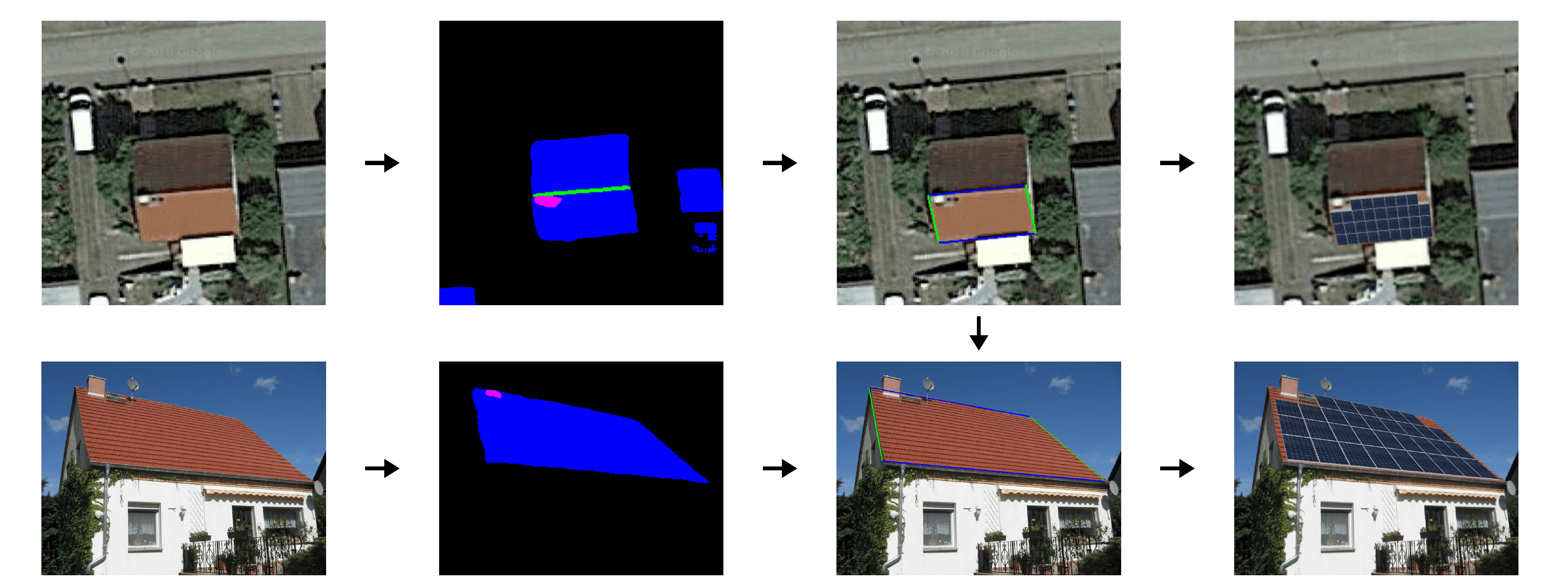
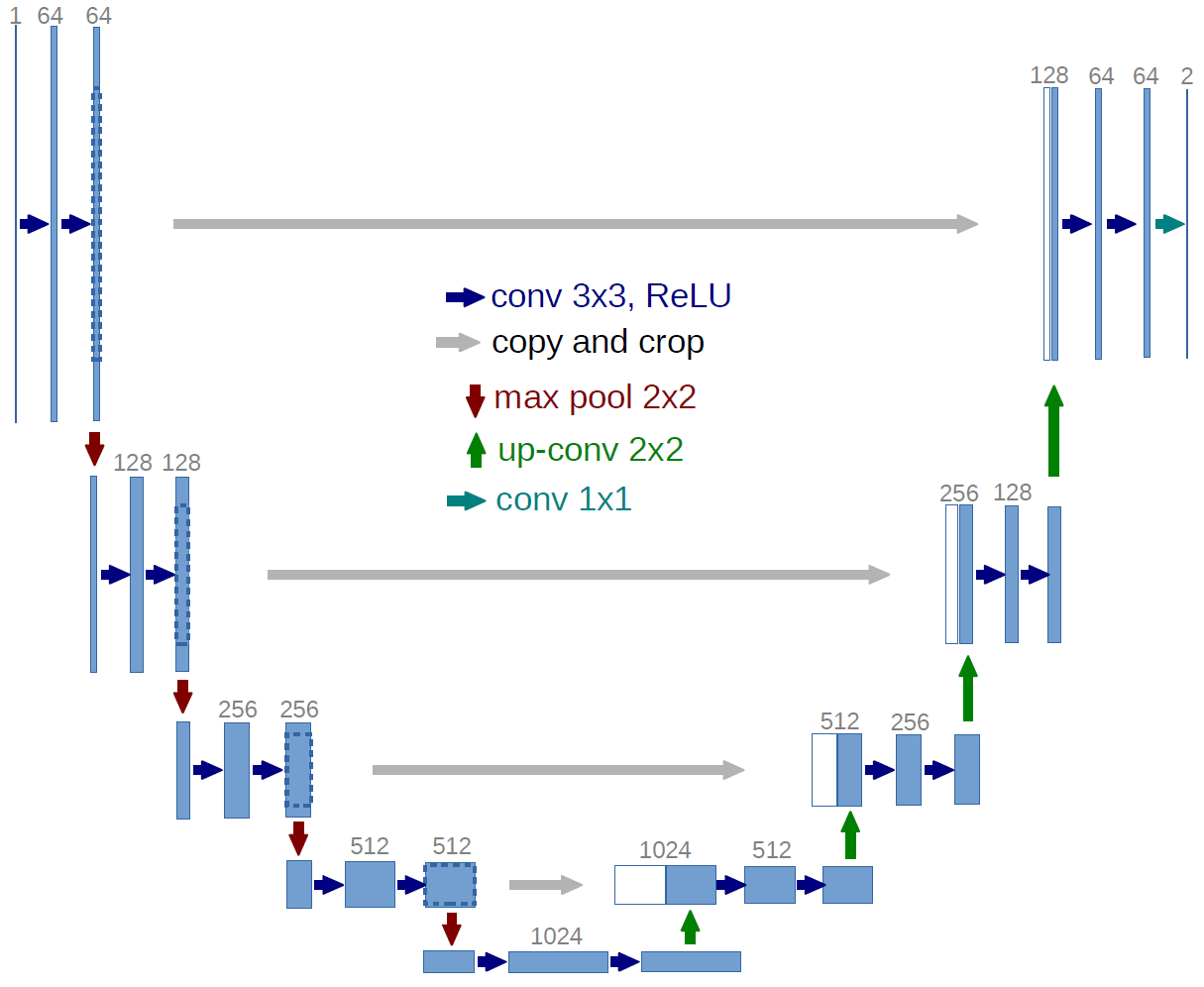
Die Autoren behaupten, dass der Hauptvorteil dieser Aktivierung darin besteht, dass sie den Mittelwert und die Varianz der vorherigen Schichten beibehält. Darüber hinaus trägt sie dazu bei, das Dying ReLU-Problem (und damit das Verschwinden von Gradienten) zu verhindern, da ihre Ableitung bei negativen Werten von Null verschieden ist. Dieser Arbeit folgten andere, die eine Verbesserung der Trainings und der Ergebnisse gezeigt haben. Unsere Vorversuche bestätigten diese Ergebnisse und so entschieden wir uns für ihren Einsatz.
Wir haben auch Datenaugmentation verwendet:
Schließlich wurden die Trainingshyperparameter empirisch mit dem greedy-Algorithmus ermittelt:
Alle diese Parameter spielten eine wichtige Rolle im Trainingsprozess, aber die richtige Wahl der Verlustfunktion erwies sich als entscheidend.
Verlustfunktionen
Wir haben die klassengewichtete kategorische Kreuzentropie (wcce) und die Würfelverlustfunktionen getestet.
Klassen-gewichtete kategorische Kreuzentropie:
Für ein Bild mit $$ d1 \times d2 $$ Pixeln und $$ K $$ Klassen ist die gewichtete Klasse kategorische Kreuzentropie definiert als