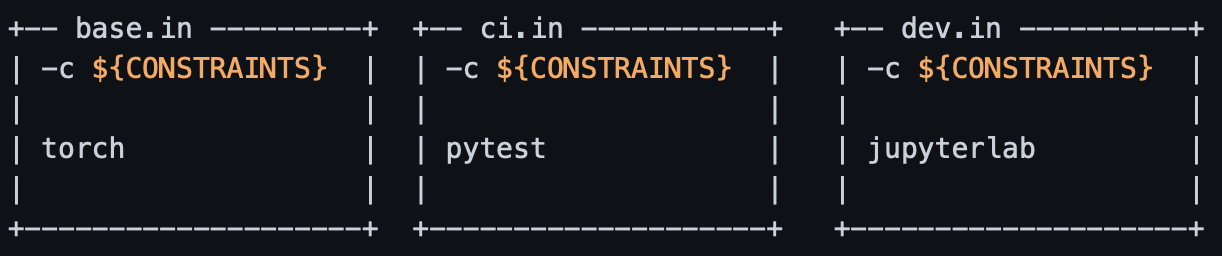
In production, we only need to install the “base” requirements; on the CI, we need the base as well as the CI set; and for local development, all three requirement sets are needed.
The pip-tools documentation already suggests a procedure to compile the above .in files into a collection of pinned .txt requirements. The idea is to first compile base.in, then use base.txtin conjunction with ci.in to produce ci.txt, and so on.
The problem with this approach is that PyTorch and Pytest have dependencies in common; when we compile base.in with no regard to ci.in, we may end up selecting a package version that conflicts with Pytest. As a project (and its list of requirements) grows, the potential for conflicts and the effort needed to manually resolve them grow exponentially (literally!).




.png)