
Mehrschichtige Requirements mit pip-tools verwalten

Bei der Erstellung von Python-Anwendungen für die Produktion ist es eine gute Praxis, alle Abhängigkeitsversionen zu fixieren, ein Prozess, der auch als "Einfrieren der Requirements" bekannt ist. Dies macht die Deployments reproduzierbar und vorhersehbar. (Bei Bibliotheken und Benutzeranwendungen sind die Anforderungen ganz anders; in diesem Fall sollte man eine große Bandbreite an Versionen für jede Abhängigkeit unterstützen, um das Konfliktpotenzial zu verringern.)
In diesem Beitrag erklären wir, wie man ein mehrschichtiges Requirements-Setup verwaltet, ohne auf den verbesserten Konfliktlösungsalgorithmus zu verzichten, der kürzlich in pip eingeführt wurde. Wir stellen ein Makefile zur Verfügung, das Sie sofort in jedem Ihrer Projekte verwenden können!
Das Problem
Im Python-Ökosystem gibt es viele Werkzeuge zur Verwaltung von gepinnten Paketlisten. Das einfachste ist vielleicht der Befehl pip freeze, der eine Liste der aktuell installierten Pakete und ihrer Versionen ausgibt. Sein Output kann dann an pip install -r weitergegeben werden, um die gleiche Sammlung von Paketen erneut zu installieren.
Ein ausgefeilterer Ansatz, der auf dieser Idee aufbaut, wird von den Werkzeugen pip-compile und pip-sync aus dem Paket pip-tools bereitgestellt. Der Prozess ist in diesem Bild zusammengefasst:

Wenn also zum Besipiel requirements.in die folgenden Abhängigkeiten enthält
torch
pytest
jupyterdann wird das resultierende requirements.txt eine Liste aller Abhängigkeiten dieser Pakete enthalten, plus die Abhängigkeiten der Abhängigkeiten, und so weiter - alle mit kompatiblen Versionswahlen.
Nehmen wir nun an, dass pytest und jupyter in der Produktion nicht wirklich benötigt werden; typischerweise wird letzteres nur für die lokale Entwicklung benötigt und ersteres sowohl für das CI als auch für die lokale Entwicklung. Wir würden also unsere Requirements in drei Dateien aufteilen:

In der Produktion müssen wir nur die "Basis"-Requirements installieren; auf der CI benötigen wir sowohl das Basis- als auch das CI-Set; und für die lokale Entwicklung werden alle drei Requirementsätze benötigt.
Die pip-tools-Dokumentation schlägt bereits ein Verfahren vor, um die oben genannten .in-Dateien in eine Sammlung von gepinnten .txt-Requirements zu kompilieren. Die Idee ist, zuerst base.in zu kompilieren, dann base.txt in Verbindung mit ci.in zu verwenden, um ci.txt zu erzeugen, und so weiter.
Das Problem bei diesem Ansatz ist, dass PyTorch und Pytest gemeinsame Abhängigkeiten haben; wenn wir base.in ohne Rücksicht auf ci.in kompilieren, kann es passieren, dass wir eine Paketversion auswählen, die in Konflikt mit Pytest steht. Wenn ein Projekt (und seine Liste der Requirements) wächst, wächst das Konfliktpotenzial und der Aufwand für die manuelle Lösung exponentiell (buchstäblich!).
Die Lösung
Hier ist ein Makefile, mit dem Sie ein mehrschichtiges Requirements-Setup einrichten und trotzdem die Vorteile der automatischen Konfliktauflösung nutzen können. Wir gehen davon aus, dass es im requirements/-Verzeichnis Ihres Projekts platziert ist, neben den Dateien base.in, ci.in und dev.in, ähnlich wie die oben genannten.
## Summary of available make targets:
##
## make help -- Display this message
## make all -- Recompute the .txt requirements files, keeping the
## pinned package versions. Use this after adding or
## removing packages from the .in files.
## make update -- Recompute the .txt requirements files files from
## scratch, updating all packages unless pinned in the
## .in files.
help:
@sed -rn 's/^## ?//;T;p' $(MAKEFILE_LIST)
PIP_COMPILE := pip-compile -q --no-header --allow-unsafe --resolver=backtracking
constraints.txt: *.in
CONSTRAINTS=/dev/null $(PIP_COMPILE) --strip-extras -o $@ $^
%.txt: %.in constraints.txt
CONSTRAINTS=constraints.txt $(PIP_COMPILE) --no-annotate -o $@ $<
all: constraints.txt $(addsuffix .txt, $(basename $(wildcard *.in)))
clean:
rm -rf constraints.txt $(addsuffix .txt, $(basename $(wildcard *.in)))
update: clean all
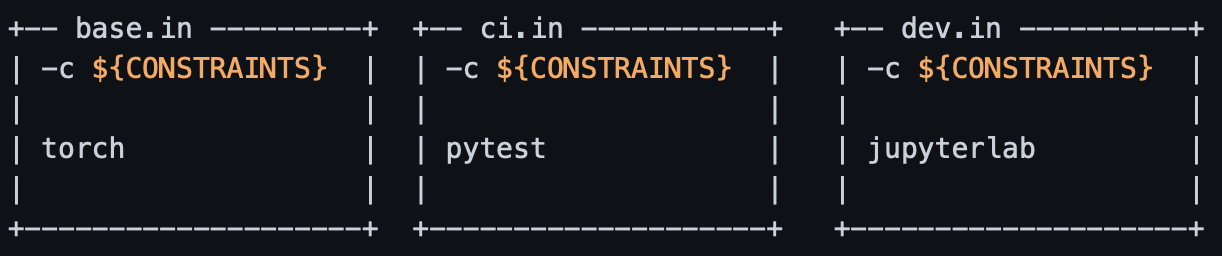
.PHONY: help all clean updateUm dies zu verwenden, sollten Sie auch die Zeile
-c ${CONSTRAINTS}am Anfang jeder .in-Datei hinzufügen. Unser einfaches Beispiel sieht nun wie folgt aus:
Gehen wir nun unser Makefile Zeile für Zeile durch. Das help-Target gibt nur den Kommentar am Anfang der Datei aus. Als nächstes definieren wir die Variable PIP_COMPILE, um Tipparbeit zu sparen. Sie können die Parameter hier nach Belieben anpassen, zum Beispiel um Hash-Checks hinzuzufügen. Beachten Sie, dass die Option --allow-unsafe überhaupt nicht unsicher ist und in einer zukünftigen Version von pip-compile zum Standard wird.
Die ersten wirklich interessanten Zeilen lauten:
constraints.txt: *.in
CONSTRAINTS=/dev/null $(PIP_COMPILE) --strip-extras -o $@ $^Dabei wird eine constraints.txt-Datei berechnet, die als Eingabe alle .in-Dateien des Projekts verwendet. Der wesentliche Punkt hierbei ist, dass pip's Resolver die Möglichkeit bekommt, alle Pakete im Projekt auf einmal zu sehen. Die Einstellung CONSTRAINT=/dev/null ist ein Trick, um die Direktive -c ${CONSTRAINTS} zu ignorieren, die wir an den Anfang unserer .in-Dateien gesetzt haben. Die Makefile-Syntax $@ steht für den Namen der Zieldatei, in diesem Fall contraints.txt, und $^ steht für ihre Voraussetzungen, in diesem Fall alle .in-Dateien.
Als nächstes haben wir
%.txt: %.in constraints.txt
CONSTRAINTS=constraints.txt $(PIP_COMPILE) --no-annotate -o $@ $<Das bedeutet, dass wir für die Erstellung von <Datei>.txt als Eingabe <Datei>.in und constraints.txt benötigen. Die hier verwendete Makefile-Syntax $< steht für die erste Voraussetzung des Make-Targets. Daher lautet der Befehl zur Erzeugung von <Datei>.txt im Wesentlichen
pip-compile -o .txt .in aber zusätzlich stellen wir sicher, dass pip die Direktive -c constraints.txt am Anfang von <file>.in sieht. (Nebenbei bemerkt, pip-compile hat eine --pip-args Kommandozeilenoption, die eine alternative Möglichkeit zu bieten scheint, dies zu erreichen; leider funktioniert sie hier nicht, da pip nicht als Unterprozess aufgerufen wird).
Die nächste Zeile
all: constraints.txt $(addsuffix .txt, $(basename $(wildcard *.in)))sagt, dass make all bedeutet, <file>.txt (mit dem obigen Rezept) für jede <file>.in in unserem Requirements-Verzeichnis zu erzeugen. Wenn einige .txt-Dateien bereits existieren, werden die in ihnen aufgeführten gepinnten Versionen nicht aktualisiert - dies ist das übliche und gewünschte Verhalten von pip-compile. Sie sollten dies jedes Mal ausführen, wenn Sie etwas zu den .in-Dateien hinzufügen oder entfernen, aber alle anderen Paketversionen unverändert lassen wollen.
Der Befehl make clean entfernt alle .txt-Dateien, die aus einer .in-Datei stammen.
Der Befehl make update schließlich ist genau wie make all, vergisst aber zunächst alle angehefteten Versionsnummern. Im Endeffekt wird jede Requirements auf die neueste brauchbare Version aktualisiert.
Bonus: die effizienteste vorkompilierte PyTorch-Version erhalten
Einige Pakete stellen besondere Anforderungen an die Paketierung, und eine schöne Sache an unserem maßgeschneiderten Ansatz ist die Flexibilität, mit der wir mit diesen Sonderfällen umgehen können.
Nehmen Sie zum Beispiel PyTorch. Wenn Sie einen Grafikprozessor verwenden, müssen Sie eine Version besorgen, die Ihrer CUDA-Version entspricht. Wenn Sie auf einer CPU arbeiten, können Sie eine Menge Bandbreite und Speicherplatz sparen, indem Sie die reine CPU-Version erwerben. Jede dieser Varianten ist über eine spezielle PyPA-Index-URL verfügbar.
Ab PyTorch Version 1.13 installiert pip install torch auf Linux die für CUDA 11.7 kompilierten Binärdateien. Um die CPU- oder CUDA 11.6-Versionen zu erhalten, können Sie die folgenden Requirements-Dateien verwenden:
.png)
Beachten Sie, dass im Gegensatz zu base.txt die beiden obigen .txt-Dateien statisch sind und nicht von pip-compile aus den .in-Eingaben erstellt werden.
Um Ihre Entwicklungsumgebung in Gang zu bringen, können Sie nun einen dieser Befehle eingeben:
pip-sync base-cpu.txt ci.txt dev.txt # If working on the CPU
pip-sync base-cu116.txt ci.txt dev.txt # If working on the GPU with CUDA 11.6
pip-sync base.txt ci.txt dev.txt # If working on the GPU with CUDA 11.7Wenn Ihnen dieses Makefile zur erfolgreichen Umsetzung Ihres Machine Learning Projekts nicht ausreicht sondern weitere Expertise von Nöten ist, können Sie einen kostenlosen Machine Learning Experten-Talk mit uns buchen.
[Bild eines Regenbogenkuchens von Marco Verch, gefunden auf https://ccnull.de/foto/rainbow-cake/1012324.]