
How to distribute a Tensorflow model as a JavaScript web app

Anyone wanting to train a Machine Learning (ML) model these days has a plethora of Python frameworks to choose from. However, when it comes to distributing your trained model to something other than a Python environment, the number of options quickly drops.
Luckily there is Tensorflow.js, a JavaScript (JS) subset of the popular Python framework with the same name. By converting a model such that it can be loaded by the JS framework, the inference can be done effectively in a web browser or a mobile app. The goal of this article is to show how to train a model in Python and then deploy it as a JS app which can be distributed online.
Intro
We will build a handwriting-to-text feature for a website or app using Tensorflow.js (demo link). This means in practice that a user will draw a character (using the fingers on a phone or the mouse on a computer), the image will then be passed into our model which predicts a character, directly in the browser without having to do round trips via the server.
Although it is technically possible to also train the model in JS using Tensorflow.js, this is usually not the most suitable solution due to the fact that the client (the browser) will perform the computations, which is usually is run on a laptop or a mobile phone with limited hardware in terms of computational power. Therefore the training will first be performed using the Python library Tensorflow which supports model training on a larger GPU which is available through Google Colab for quicker training sessions. Once the training is done we export the model using another Python library tensorflowjs converter, so that it can be loaded in a web browser where the predictions will be made.
Dataset
As is often the case with ML, in order to produce a model with a decent accuracy, we need a sufficiently large data set to train the model on. We decided to go with a data set EMNIST, a super set if you will to the popular MNIST data set. EMNIST contains not only the characters 0-9 like it's cousin MNIST, but also the latin ascii characters a-z and A-Z, which makes it applicable to our problem.
The EMNIST dataset has multiple different categorizations depending on your choice, see the histogram below from the original paper for a visual comparison.
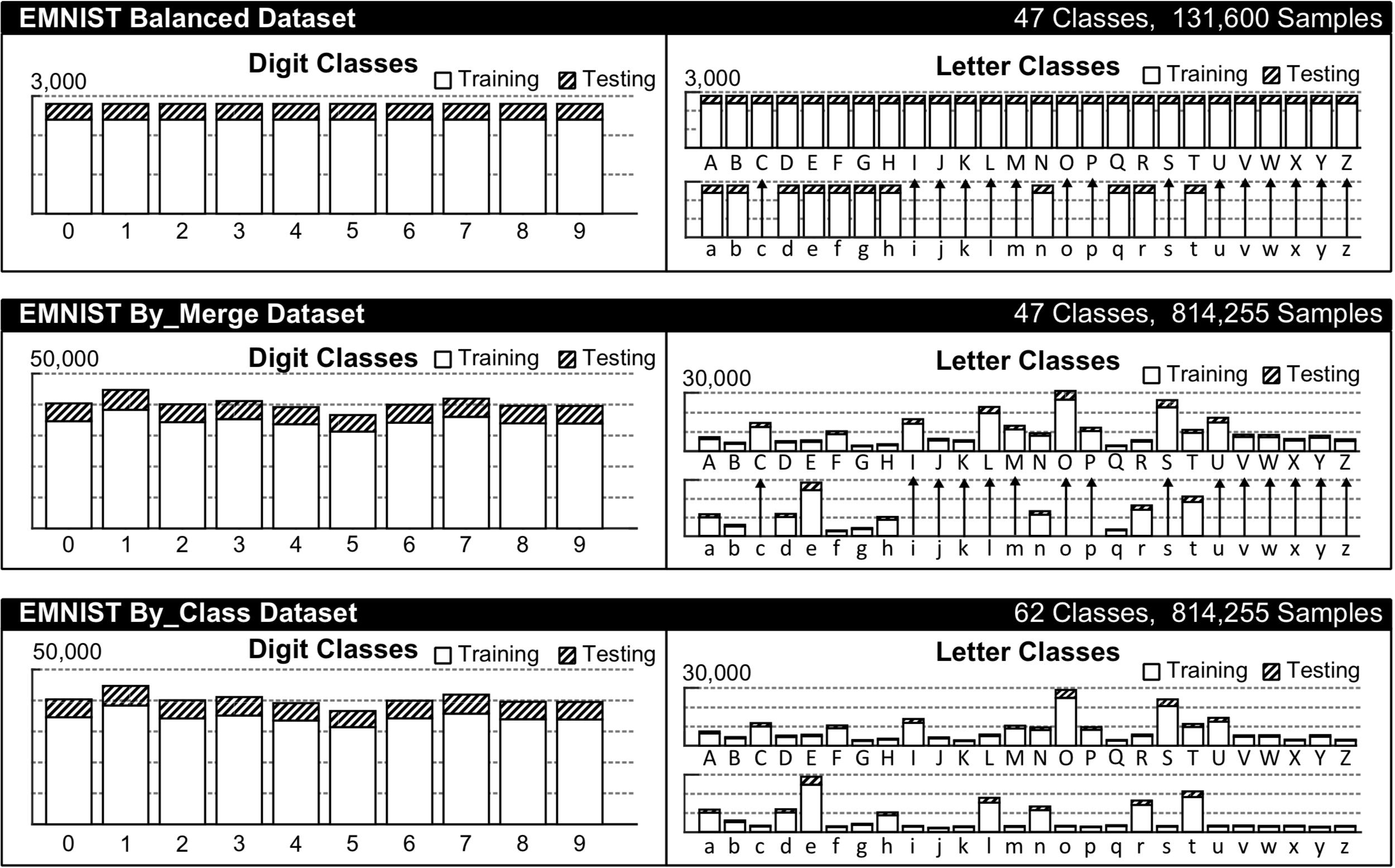
We're going to choose the categorization called By_Class for this task, since we want to be able to predict both upper and lower case characters as well as digits. Although the data set is fairly large (62 classes with 814 255 samples in total, where 697 932 of them are for training) it is quite heavily imbalanced, which can often lead to unwanted biases in the ML model towards the majority classes. However, for the purposes of this article, which is rather focused on how to get a model deployed in JS we'll have to live with these potential biases for now and move on to the training.
Downloading and extracting the EMNIST data set to your machine is done as follows:
!wget http://www.itl.nist.gov/iaui/vip/cs_links/EMNIST/gzip.zip
!unzip gzip.zip
!rm gzip.zipNote that the leading "!" is only necessary if you run it in a Jupyter environment.
Loading your data set into memory for further processing is easily done with the help of the python library called python-mnist. To install run pip install python-mnist. Then we're ready to import the python packages and load the data set:
import numpy as np
from mnist import MNIST
# load the entire EMNIST dataset as numpy arrays (this might take a while)
emnist_data = MNIST(path='gzip', return_type='numpy')
emnist_data.select_emnist('byclass')
x_train, y_train = emnist_data.load_training()
x_test, y_test = emnist_data.load_testing()
# print the shapes
x_train.shape, y_train.shape, x_test.shape, y_test.shape
>>> ((697932, 784), (697932,), (116323, 784), (116323,))As you can see, we have 697 932 training samples and 116 323 test samples, which are 784-dimensional vectors. We want to transform these into 28281 3-dimensional tensors and normalize them (which can speed up training).
img_side = 28
# Reshape tensors to [n, y, x, 1] and normalize the pixel values between [0, 1]
x_train = x_train.reshape(-1, img_side, img_side, 1).astype('float32') / 255.0
x_test = x_test.reshape(-1, img_side, img_side, 1).astype('float32') / 255.0
x_train.shape, x_test.shape
>>> ((697932, 28, 28, 1), (116323, 28, 28, 1))That looks better. Now for the target vectors. As you can see above, there are two lists of 697 932 and 116 323 scalars representing the different classes. Since the model we're creating is going to perform a multi class classification task, we need to one-hot encode these values (also known as dummy variables):
num_classes = len(np.unique(y_train))
y_train = tf.keras.utils.to_categorical(y_train, num_classes)
y_test = tf.keras.utils.to_categorical(y_test, num_classes)
y_train.shape, y_test.shape
>>> ((697932, 62), (116323, 62))Training
For image classification tasks such as this one Convolutional Neural Networks (CNNs) are often the best performing models, thus we will use one here.
Since the model will be deployed and used on the web, the smaller file size the better, therefore we restrict the amount layers in the model. This kind of model size- vs. accuracy-trade off has to be considered carefully. In our tests, we found that the following settings gave us a good enough performance while keeping the model under 0.5 MB when converted.
import tensorflow as tf
def createmodel():
return tf.keras.models.Sequential([
tf.keras.layers.Convolution2D(16, (3, 3), padding='same', input_shape=input_shape, activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=(2, 2)),
tf.keras.layers.Convolution2D(32, (3, 3), padding='same', activation= 'relu'),
tf.keras.layers.MaxPooling2D(pool_size=(2, 2)),
tf.keras.layers.Convolution2D(64, (3, 3), padding='same', activation= 'relu'),
tf.keras.layers.MaxPooling2D(pool_size =(2,2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(num_classes, activation='softmax'),
])
model = createmodel()
model.compile(loss="categorical_crossentropy",
optimizer="adam",
metrics=["accuracy"])For a graphical overview our model, there's a nice helper method (click on the image below to enlarge it):
python tf.keras.utils.plot_model(model, show_shapes=True)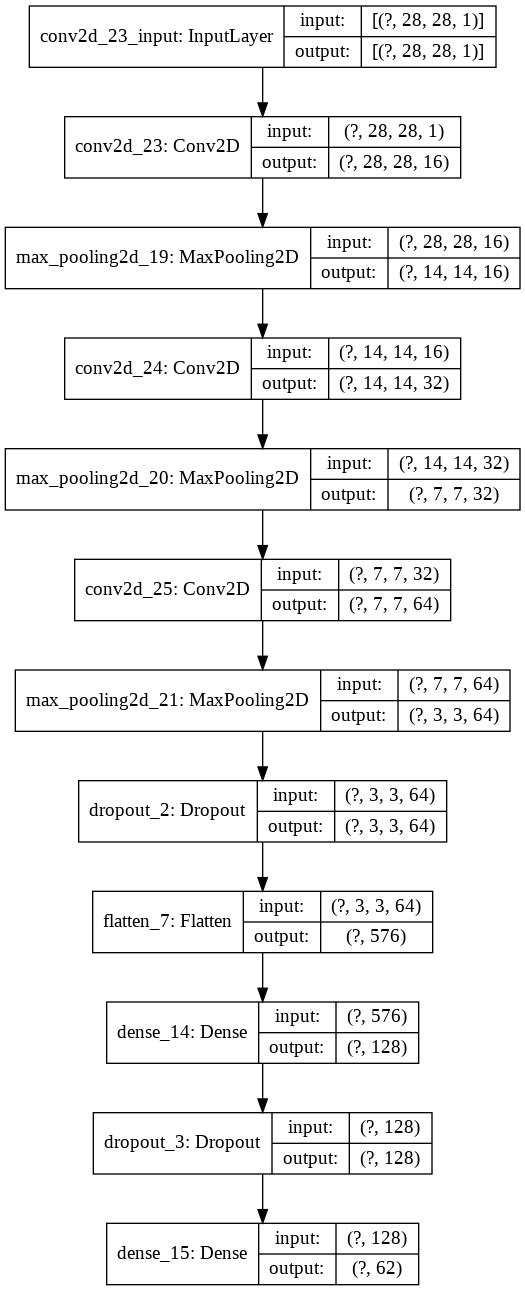
The model is now ready to be trained. The tf.keras.callbacks.EarlyStopping function is a convenient way of letting the model train until an optimum is found, meaning when the validation loss function won't go lower for let's say 10 epochs. The validation is performed on the test data set.
es = tf.keras.callbacks.EarlyStopping(
monitor='val_loss',
mode='min',
verbose=1,
patience=10,
restore_best_weights=True)
model.fit(x_train, y_train,
batch_size=1000,
epochs=200,
verbose=1,
shuffle=True,
class_weight=class_weights,
validation_data=(x_test, y_test),
callbacks=[es])Model evaluation and export
Looking at the results, we see that the accuracy of the predictions on the test set reaches a maximum of about 86% after 10 epochs. Not really a fantastic score, but still acceptable.
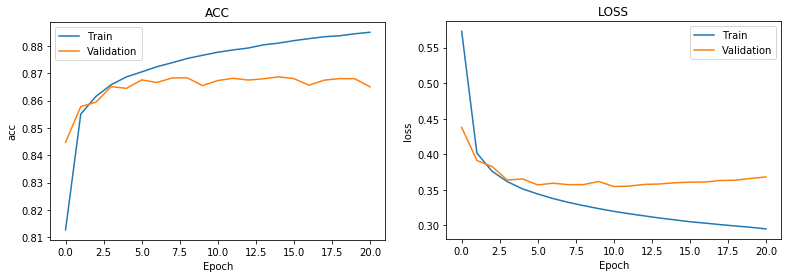
Let's get some better insights into where the model fails to predict the right values. This is easily visible with the help of a so called confusion matrix. We evaluate predictions on our test data set in relation with their true values, which looks something like the image below.
from sklearn.metrics import confusion_matrix
import seaborn as sns
import string
y_pred = model.predict(x_test)
labels = string.digits+string.ascii_lowercase+string.ascii_uppercase
plt.subplots(figsize=(20,20))
sns.heatmap(confusion_matrix(np.argmax(y_test, axis=1), np.argmax(y_pred, axis=1)), xticklabels=labels, yticklabels=labels)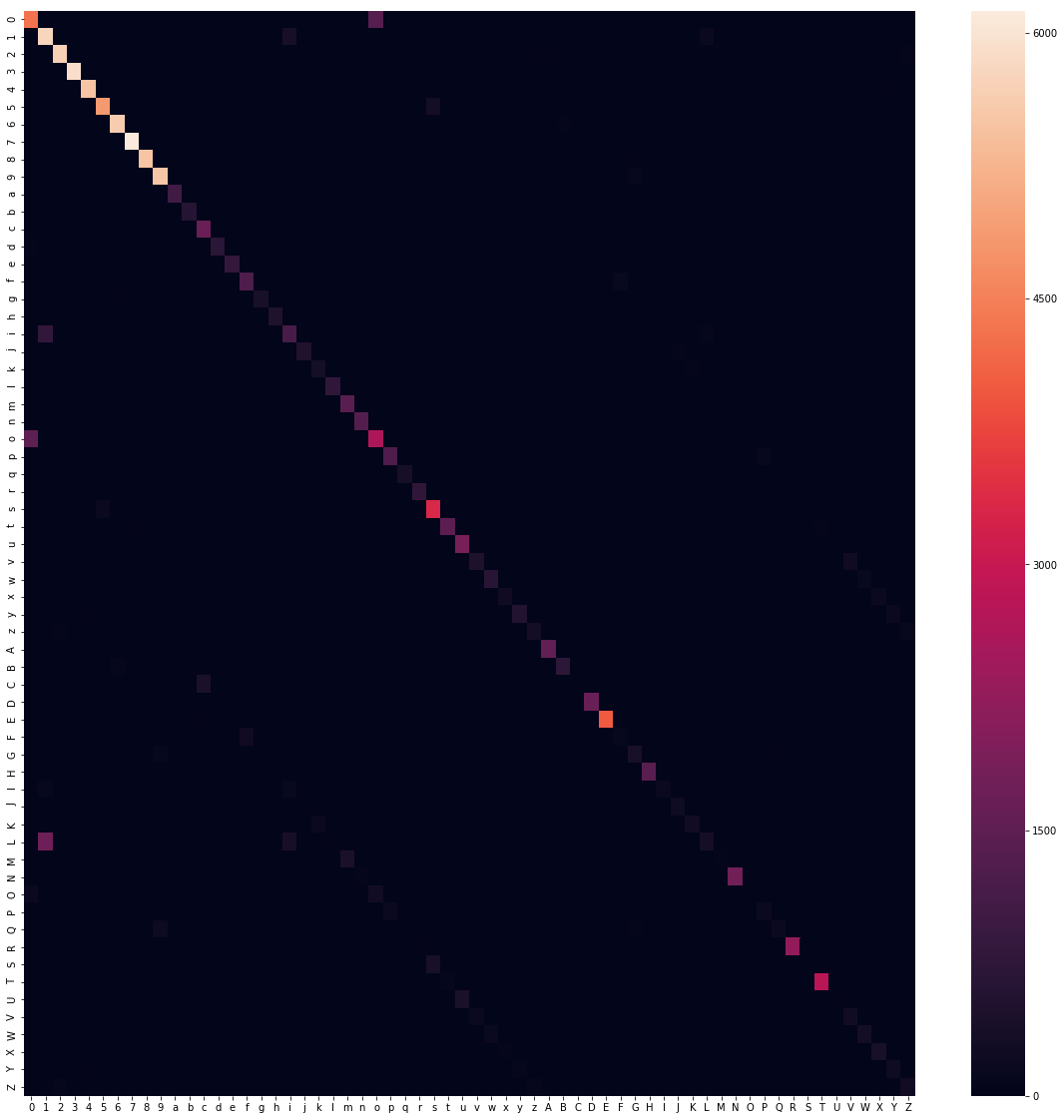
Exporting the model is made easy with the help of the Python library tensorflowjs. The tensorflowjs_converter terminal command produces two files: the model.json file which describes the model's setup, topology, type of layers, inputs and outputs, etc. The other .bin file is a binary file containing all the trained weights. We simply store our keras model to disk, and then convert it into the right format.
model.save("cnn_emnist.h5")
!pip install tensorflowjs
!tensorflowjs_converter --input_format keras "cnn_emnist.h5" ./jsmodelNow, we're ready to start producing the web app that will use this model for handwriting character recognition.
Browser frontend app
Before we begin with coding, let's discuss requirements of the web app for a second. There are two major components in this app: a hand drawing component and model prediction component. The latter is taken care of by tensorflow.js, we just need to prepare the image from the canvas before passing it to our model. For drawing, there are tons of great JS libraries out there, so let's not reinvent the wheel here. Upon some investigation, fabric.js seems to have the all capabilities we need as it supports free hand drawing to canvas as well as a bunch of helper functions that will come in handy later. In order to keep things tidy, we will create two classes Handwriting and Model, which wraps all methods and variables concerning each task respectively.
Let's first look at the drawing component. We would like to have a large full screen canvas, where the user can draw where ever he/she wants. Once the user has drawn something, we want to capture only the area where something is drawn, instead of scaling down the entire canvas to 28281 (our model's input size), which would likely obscure the actual drawing heavily.
First, let's set up our html document and load the necessary JS dependencies.
---
Handwriting recognition
And voilà, now we can paint freely on the canvas. Next we would like to extract the pixel data created by the user, but nothing else. No unnecessary blank canvas outside the actual drawing. The fabric.Group method groups our collection of strokes on the canvas into a group which conveniently gives us values such as total width, height, x- and y-offset.
constructor() {
this.canvas = new fabric.Canvas('handwriting', {
backgroundColor: "#fff",
isDrawingMode: true
})
this.canvas.freeDrawingBrush.color = "#000"
}Note that we have to scale all factors by scale = window.devicePixelRatio to account for high resolution screens where 1 physical pixel doesn't always represent 1 virtual pixel. Later we'll show how to and when to call the method captureDrawing() but in the most minimal form, this is all we need from the Handwriting class, so let's move over to our Model class and see how we can get a prediction on what was just drawn.
In our class Model constructor, we need to first load our exported TensorFlow model and weights and assign it to a class variable. This is done as follows:
tf.loadLayersModel("jsmodel/model.json").then(model => {
this._model = model;
})Here, tf.loadLayersModel() returns a Promise which, once resolved, returns our model object which is ready to do predictions.
However, before we can go ahead and try our first prediction in JS, we need to prepare the the image a little bit. The image will most certainly not have the right dimensions when passed over from the Handwriting class. Therefore we create a preprocessImage() method, which ensures that it matches the requirement of the model.
preprocessImage(pixelData) {
const targetDim = 28,
edgeSize = 2,
resizeDim = targetDim-edgeSize*2,
padVertically = pixelData.width > pixelData.height,
padSize = Math.round((Math.max(pixelData.width, pixelData.height) - Math.min(pixelData.width, pixelData.height))/2),
padSquare = padVertically ? [[padSize,padSize], [0,0], [0,0]] : [[0,0], [padSize,padSize], [0,0]];
return tf.tidy(() => {
// convert the pixel data into a tensor with 1 data channel per pixel
// i.e. from [h, w, 4] to [h, w, 1]
let tensor = tf.browser.fromPixels(pixelData, 1)
// pad it until square, such that w = h = max(w, h)
.pad(padSquare, 255.0)
// scale it down to smaller than target
tensor = tf.image.resizeBilinear(tensor, [resizeDim, resizeDim])
// pad it with blank pixels along the edges (to better match the training data)
.pad([[edgeSize,edgeSize], [edgeSize,edgeSize], [0,0]], 255.0)
// invert and normalize to match training data
tensor = tf.scalar(1.0).sub(tensor.toFloat().div(tf.scalar(255.0)))
// Reshape again to fit training model [N, 28, 28, 1]
// where N = 1 in this case
return tensor.expandDims(0)
});
}Note that the tf.tidy() function helps cleaning up all temporary tensors once executed to avoid memory leaks.
Ok, time for our prediction. We create a method that takes the pixel data from the Handwriting class, preprocesses, makes a prediction, and then retrieves the most probable character.
this.alphabet = "abcdefghijklmnopqrstuvwxyz";
this.characters = "0123456789" + this.alphabet.toUpperCase() + this.alphabet
predict(pixelData) {
let tensor = this.preprocessImage(pixelData),
prediction = this._model.predict(tensor).as1D(),
// get the index of the most probable character
argMax = prediction.argMax().dataSync()[0],
// get the character at that index
character = this.characters[argMax];
return character;
}Note that operations on the tensors aren't directly accessible to us in the JS runtime. They might be run on the GPU and to avoid unnecessary traffic between the CPU and the GPU, you need to call .dataSync() explicitly to retrieve the value.
That's it, now we have everything needed to make a prediction. Simply run:
handwriting = new Handwriting;
model = new Model;
// run these commands once you've drawn a "j" for example
model.predict(handwriting.captureDrawing())
// >>> "j" (hopefully)Our job is not really done here though. The web app is hardly interactive enough to be useful. We want to clear the canvas once the character has been obtained and predicted, so that we're ready for the next prediction. Therefore we need to set a timer after the user has stopped painting. This timer is cancelled each time the user touches the canvas again, but as soon as we register a certain amount of time without any interaction, we capture what's drawn (after some experimentation, 800 ms on desktop and 400 ms on touch devices seem like a decent choice). Let's add the following code to the Handwriting class.
bindEvents() {
let hasTimedOut = false,
timerId = null,
isTouchDevice = 'ontouchstart' in window,
timeOutDuration = isTouchDevice ? 400 : 800;
this.canvas.on("mouse:down", (options) => {
// reset the canvas in case something was drawn previously
if(hasTimedOut) this.resetCanvas(false);
hasTimedOut = false;
// clear any timer currently active
if(timerId) {
clearTimeout(timerId);
timerId = null;
}
})
.on("mouse:up", () => {
// set a new timer
timerId = setTimeout(() => {
// once timer is triggered, flag it and run prediction
hasTimedOut = true;
let prediction = this.model.predict(this.captureDrawing());
console.log("prediction", prediction)
}, timeOutDuration);
})
}
resetCanvas(removeText = true) {
this.canvas.clear();
this.canvas.backgroundColor = "#fff";
}The above mentioned functions are all you need to build an interactive web app that predicts hand written characters from the user. However, a lot of additional features could be wished for in order to make this a nice app to interact with such as: canvas auto-resizing with the browser window, displaying the output of the model on the website, variable stroke width, clear/submit button, pre-warmup of the model to improve latency, etc. Unfortunately this would mean that this already lengthy article would become even longer.
If you want to have a look at the source code of the end result, check out our Github repository to download the project in its entirety. For a live demo look at the iframe below or click here for a full screen version of the app.
Contact
If you would like to speak with us about this topic, please reach out and we will schedule an introductory meeting right away.