
Wie ein TensorFlow-Model zu einer JavaScript-Web-App wird

Jeder, der heutzutage ein Machine Learning (ML)-Modell trainieren möchte, hat eine Vielzahl von Python-Frameworks zur Auswahl. Wenn es jedoch darum geht, das trainierte Modell in einer Nicht-Python-Umgebung einzusetzen, sinkt die Anzahl der Optionen schnell.
Glücklicherweise gibt es Tensorflow.js, eine JavaScript (JS)-Untermenge des beliebten Python-Frameworks mit dem gleichen Namen. Durch die Konvertierung eines Modells, so dass es vom JS-Framework geladen werden kann, kann die Inferenz in einem Webbrowser oder einer mobilen Anwendung effektiv durchgeführt werden. Das Ziel dieses Artikels ist es, zu zeigen, wie man ein Modell in Python trainiert und es dann als JS-App bereitstellt, die online vertrieben werden kann.
Einführung
Wir werden eine Handschrift-zu-Text-Funktion für eine Website oder App mit Tensorflow.js (Demo-Link) erstellen. Das bedeutet in der Praxis, dass ein Benutzer einen Buchstaben oder eine Zahl zeichnet (mit dem Touchscreen des Handys oder der Maus eines Computers) und das Bild dann an unser Modell weitergeleitet wird. Das Modell versucht das gemalte Zeichen zu erkennen, direkt im Browser, ohne dass Umwege über den Server gemacht werden müssten.
Obwohl es technisch möglich ist, das Modell auch in JS mit Tensorflow.js zu trainieren, ist dies in der Regel nicht die am besten geeignete Lösung, da der Client (der Browser) die Berechnungen durchführt, der in der Regel auf einem Laptop oder einem Mobiltelefon mit begrenzter Hardware in Bezug auf die Rechenleistung ausgeführt wird. Daher wird das Training zunächst mit der Python-Bibliothek Tensorflow durchgeführt, welche Modelltraining auf einer größeren GPU unterstützt, die über Google Colab für schnellere Trainingseinheiten verfügbar ist. Sobald das Training abgeschlossen ist, exportieren wir das Modell mit Hilfe der Python-Bibliothek tensorflowjs converter, so dass es in einen Webbrowser geladen werden kann, wo die Vorhersagen gemacht werden.
Datensatz
Wir benötigen wir einen ausreichend großen Datensatz, um ein Modell mit einer angemessenen Genauigkeit zu trainieren. Wir haben uns für den Datensatz EMNIST entschieden, eine Erweiterung des beliebten MNIST-Datensatzes. EMNIST enthält nicht nur die Zeichen 0-9 wie sein Cousin MNIST, sondern auch die lateinischen ASCII-Zeichen a-z und A-Z, was es für unser Problem anwendbar macht.
Der EMNIST-Datensatz hat je nach Wahl mehrere verschiedene Kategorien, siehe das Histogramm unten aus dem Originalpaper für einen visuellen Vergleich.
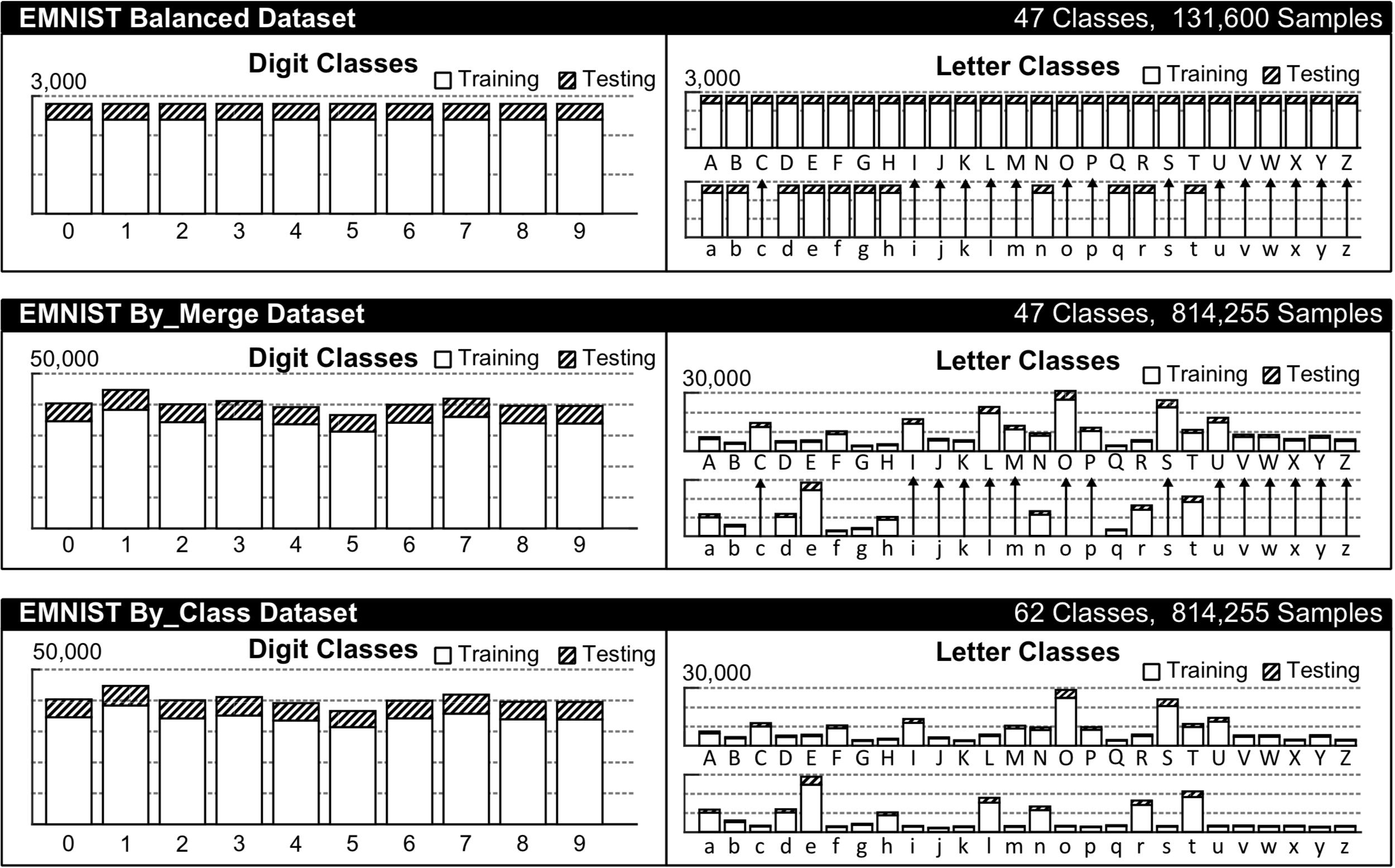
Wir werden für diese Aufgabe die Kategorisierung By_Class wählen, da wir sowohl Groß- und Kleinbuchstaben als auch Ziffern vorhersagen wollen. Obwohl der Datensatz ziemlich groß ist (62 Klassen mit insgesamt 814 255 Stichproben, von denen 697 932 für das Training bestimmt sind), ist er ziemlich unausgewogen, was oft zu unerwünschten Verzerrungen im ML-Modell gegenüber den Mehrheitsklassen führen kann. Für die Zwecke dieses Artikels, der sich eher darauf konzentriert, wie man ein Modell in JS einsetzt, müssen wir jedoch vorerst mit diesen möglichen Verzerrungen leben und zum Training übergehen.
Das Herunterladen und Extrahieren des EMNIST-Datensatzes funktioniert folgendermaßen:
!wget http://www.itl.nist.gov/iaui/vip/cs_links/EMNIST/gzip.zip
!unzip gzip.zip
!rm gzip.zipBeachten Sie, dass die Angabe "!" nur notwendig ist, wenn Sie sie in einer Jupyter-Umgebung ausführen.
Das Laden Ihres Datensatzes in den Speicher zur weiteren Verarbeitung erfolgt einfach mit Hilfe der Python-Bibliothek python-mnist. Um die Installation durchzuführen, führen Sie pip install python-mnistaus. Dann sind wir bereit, die Python-Pakete zu importieren und den Datensatz zu laden:
import numpy as np
from mnist import MNIST
# load the entire EMNIST dataset as numpy arrays (this might take a while)
emnist_data = MNIST(path='gzip', return_type='numpy')
emnist_data.select_emnist('byclass')
x_train, y_train = emnist_data.load_training()
x_test, y_test = emnist_data.load_testing()
# print the shapes
x_train.shape, y_train.shape, x_test.shape, y_test.shape
>>> ((697932, 784), (697932,), (116323, 784), (116323,))Wie Sie sehen können, haben wir 697 932 Trainingssamples und 116 323 Testsamples, welche 784-dimensionale Vektoren sind. Wir wollen diese in 28*28*1 3-dimensionale Tensoren transformieren und normalisieren (was das Training beschleunigen kann).
img_side = 28
# Reshape tensors to [n, y, x, 1] and normalize the pixel values between [0, 1]
x_train = x_train.reshape(-1, img_side, img_side, 1).astype('float32') / 255.0
x_test = x_test.reshape(-1, img_side, img_side, 1).astype('float32') / 255.0
x_train.shape, x_test.shape
>>> ((697932, 28, 28, 1), (116323, 28, 28, 1))Das sieht besser aus. Nun zu den Zielvektoren. Wie Sie oben sehen können, gibt es zwei Listen mit 697 932 und 116 323 Skalaren, welche die verschiedenen Klassen darstellen. Da das von uns erstellte Modell eine Klassifikationsaufgabe mit mehreren Klassen durchführen wird, müssen wir diese Werte one-hot kodieren (auch bekannt als Dummy-Variablen):
num_classes = len(np.unique(y_train))
y_train = tf.keras.utils.to_categorical(y_train, num_classes)
y_test = tf.keras.utils.to_categorical(y_test, num_classes)
y_train.shape, y_test.shape
>>> ((697932, 62), (116323, 62))Training
Für Bildklassifikationsaufgaben wie diese sind Convolutional Neural Networks (CNNs) oft die leistungsstärksten Modelle, daher werden wir hier eines verwenden.
Da das Modell im Web eingesetzt wird, sollte die Datei möglichst klein sein, daher begrenzen wir die Anzahl der Layer im Modell. Diese Art von Modellgröße-vs.-Genauigkeit-Tradeoff muss sorgfältig abgewogen werden. In unseren Tests stellten wir fest, dass die folgenden Einstellungen eine ausreichende Leistung brachten, während das Modell bei der Konvertierung unter 0,5 MB blieb.
import tensorflow as tf
def createmodel():
return tf.keras.models.Sequential([
tf.keras.layers.Convolution2D(16, (3, 3), padding='same', input_shape=input_shape, activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=(2, 2)),
tf.keras.layers.Convolution2D(32, (3, 3), padding='same', activation= 'relu'),
tf.keras.layers.MaxPooling2D(pool_size=(2, 2)),
tf.keras.layers.Convolution2D(64, (3, 3), padding='same', activation= 'relu'),
tf.keras.layers.MaxPooling2D(pool_size =(2,2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(num_classes, activation='softmax'),
])
model = createmodel()
model.compile(loss="categorical_crossentropy",
optimizer="adam",
metrics=["accuracy"])Für einen grafischen Überblick über unser Modell gibt es eine schöne Hilfsmethode (klicken Sie auf das Bild unten, um es zu vergrößern):
python tf.keras.utils.plot_model(model, show_shapes=True)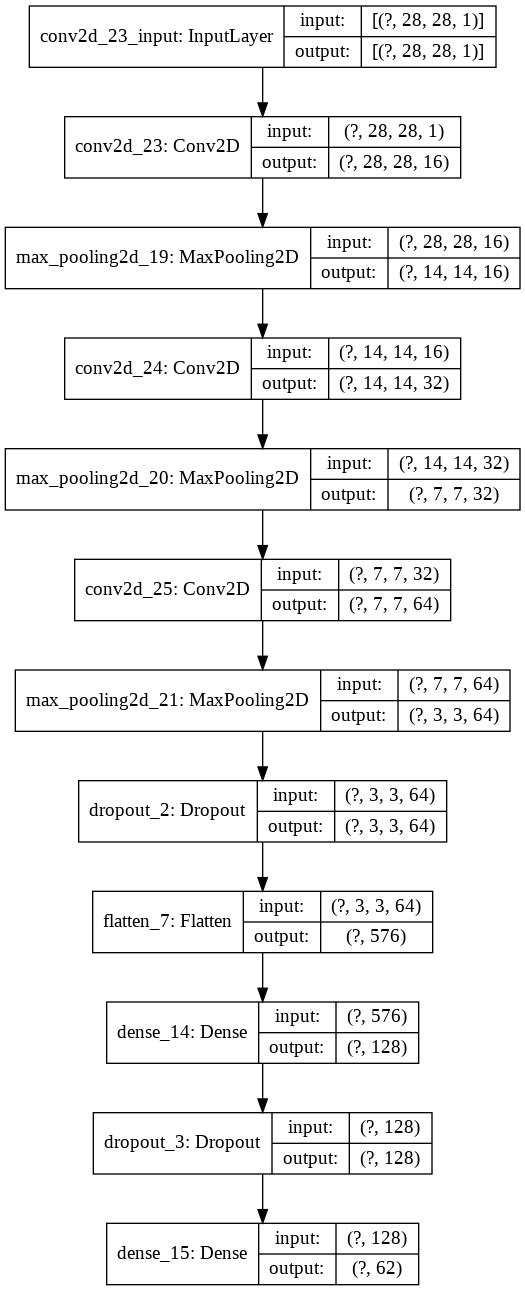
Das Modell ist nun bereit für das Training. Die Funktion tf.keras.callbacks.EarlyStopping ist eine komfortable Möglichkeit, das Modell so lange trainieren zu lassen, bis ein Optimum gefunden ist, d.h. wenn die Validierungsverlustfunktion für etwa 10 Epochen nicht nach unten geht. Die Validierung wird auf dem Testdatensatz durchgeführt.
es = tf.keras.callbacks.EarlyStopping(
monitor='val_loss',
mode='min',
verbose=1,
patience=10,
restore_best_weights=True)
model.fit(x_train, y_train,
batch_size=1000,
epochs=200,
verbose=1,
shuffle=True,
class_weight=class_weights,
validation_data=(x_test, y_test),
callbacks=[es])Modellevaluation und Export
Betrachtet man die Ergebnisse, so zeigt sich, dass die Genauigkeit der Vorhersagen auf dem Testset nach 10 Epochen maximal etwa 86% beträgt. Nicht wirklich ein fantastisches Ergebnis, aber trotzdem akzeptabel.
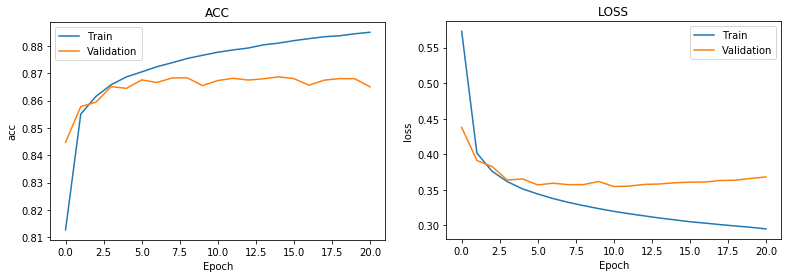
Lassen Sie uns einen besseren Einblick bekommen, wo das Modell die richtigen Werte nicht vorhersagt. Dies ist mit Hilfe einer so genannten Confusion-Matrix gut sichtbar. Wir werten Vorhersagen unseres Testdatensatzes in Bezug auf die wahren Werte aus, was in etwa dem folgenden Bild entspricht.
from sklearn.metrics import confusion_matrix
import seaborn as sns
import string
y_pred = model.predict(x_test)
labels = string.digits+string.ascii_lowercase+string.ascii_uppercase
plt.subplots(figsize=(20,20))
sns.heatmap(confusion_matrix(np.argmax(y_test, axis=1), np.argmax(y_pred, axis=1)), xticklabels=labels, yticklabels=labels)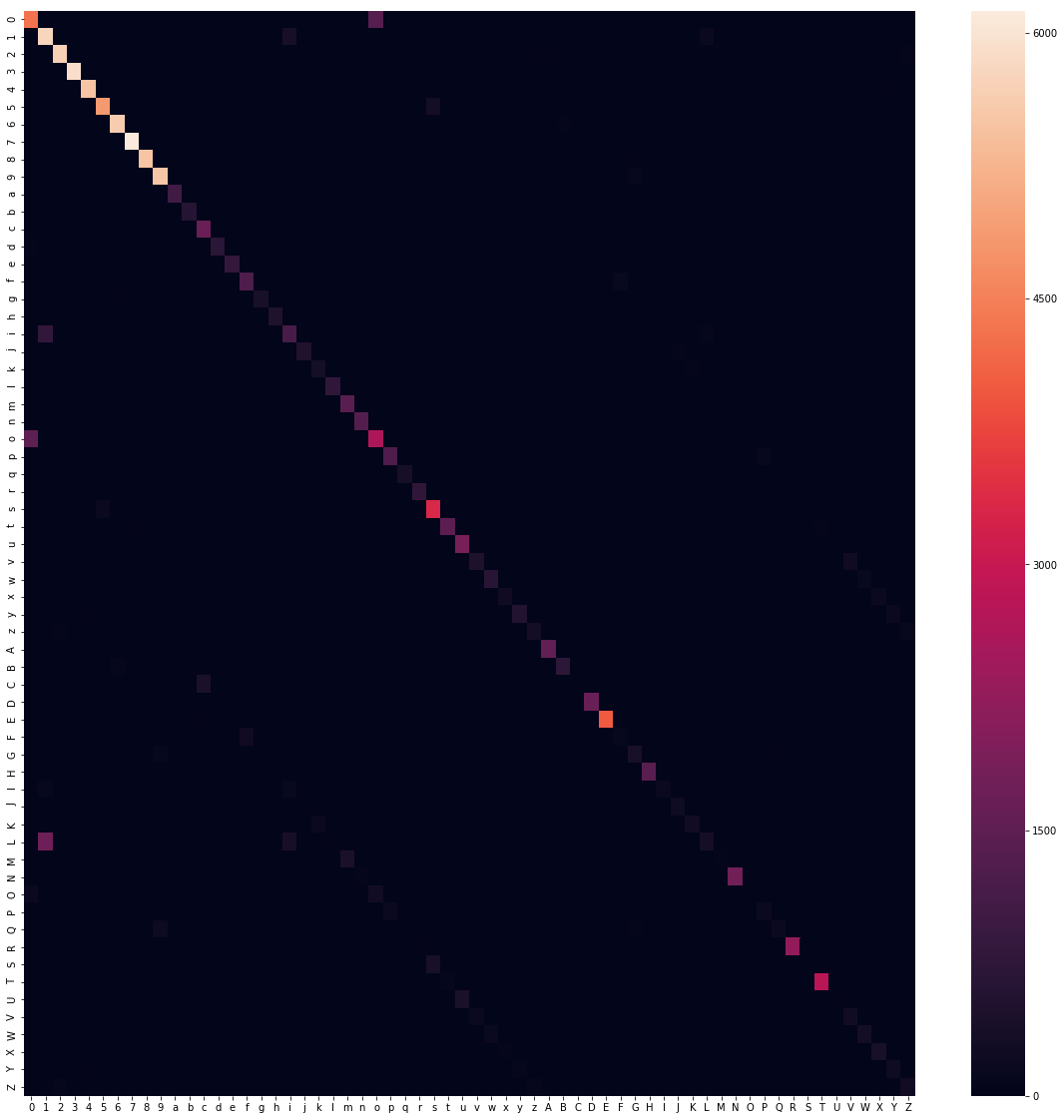
Der Export des Modells wird durch die Python-Bibliothek tensorflowjs vereinfacht. Der Terminalbefehl tensorflowjs_converter erzeugt zwei Dateien: die Datei model.json, die den Aufbau des Modells, die Topologie, die Art der Layer, die Ein- und Ausgänge usw. beschreibt. Die andere .bin-Datei ist eine Binärdatei, die alle trainierten Gewichte enthält. Wir speichern unser Keras-Modell einfach auf der Festplatte und konvertieren es dann in das richtige Format.
model.save("cnn_emnist.h5")
!pip install tensorflowjs
!tensorflowjs_converter --input_format keras "cnn_emnist.h5" ./jsmodelJetzt sind wir bereit, mit der Produktion der Web-App zu beginnen, die dieses Modell für die Handschrifterkennung nutzen wird.
Browser-Frontend-App
Bevor wir mit der Programmierung beginnen, lassen Sie uns kurz die Anforderungen an die Web-Applikation besprechen. Es gibt zwei Hauptkomponenten in dieser App: eine Handzeichnungskomponente und eine Modellvorhersagekomponente. Letzteres wird von tensorflow.js übernommen, wir müssen nur das Bild von der Leinwand vorbereiten, bevor wir es an unser Modell übergeben. Zum Zeichnen gibt es Tonnen von großen JS-Bibliotheken, also lasst uns das Rad hier nicht neu erfinden. Nach einer kurzen Recherche scheint fabric.js über alle Fähigkeiten zu verfügen, die wir brauchen, da es das freie Zeichnen auf Leinwand sowie eine Reihe von Hilfsfunktionen unterstützt, die später nützlich sein werden. Um die Dinge ordentlich zu halten, werden wir zwei Klassen Handwriting und Model erstellen, die alle Methoden und Variablen für jede Aufgabe umschließen.
Lassen Sie uns zunächst einen Blick auf die Zeichenkomponente werfen. Wir hätten gerne eine große Vollbild-Leinwand, auf der der Benutzer zeichnen kann, wo immer er will. Sobald der Benutzer etwas gezeichnet hat, wollen wir nur den Bereich erfassen, in dem etwas gezeichnet wird, anstatt die gesamte Leinwand auf 28281 (die Eingabegröße unseres Modells) zu verkleinern, was die eigentliche Zeichnung wahrscheinlich unkenntlich machen würde.
Zuerst richten wir unser html-Dokument ein und laden die notwendigen JS-Abhängigkeiten.
Handwriting recognition
Alle unsere untenstehenden Codes bezüglich der Handzeichnung werden Handwriting-Klasse hinzugefügt. Als nächstes wird die Leinwand fabric.Canvas eingerichtet, damit wir darauf malen können.
constructor() {
this.canvas = new fabric.Canvas('handwriting', {
backgroundColor: "#fff",
isDrawingMode: true
})
this.canvas.freeDrawingBrush.color = "#000"
}Und voilà, jetzt können wir frei auf der Leinwand malen. Als nächstes möchten wir die vom Benutzer erstellten Pixeldaten extrahieren, aber nichts anderes. Keine unnötige leere Leinwand außerhalb der eigentlichen Zeichnung. Die fabric.Group-Methode gruppiert unsere Sammlung von Strichen auf der Leinwand zu einer Gruppe, die uns bequem Werte wie Gesamtbreite, Höhe, x- und y-Abstand liefert.
captureDrawing() {
let group = new fabric.Group(this.canvas.getObjects()),
{ left, top, width, height } = group,
scale = window.devicePixelRatio,
image = this.canvas.contextContainer.getImageData(left*scale, top*scale, width*scale, height*scale);
return image;
}Beachten Sie, dass wir alle Faktoren durch scale = window.devicePixelRatio skalieren müssen, um hochauflösende Bildschirme zu berücksichtigen, bei denen ein physisches Pixel nicht immer ein virtuelles Pixel darstellt. Später werden wir zeigen, wie und wann man die Methode captureDrawing() aufruft, aber in der minimalsten Form ist das alles, was wir von der Handwriting-Klasse brauchen, also lasst uns zu unserer Model-Klasse übergehen und sehen, wie wir eine Vorhersage darüber bekommen können, was gerade gezeichnet wurde.
In unserem Model-Konstruktor müssen wir zuerst unser exportiertes Tensorflow-Modell und die Gewichte laden und einer Klassenvariablen zuweisen. Dies geschieht wie folgt:
tf.loadLayersModel("jsmodel/model.json").then(model => {
this._model = model;
})Hier gibt tf.loadLayersModel() ein Promise zurück, das nach der Auflösung unser Modellobjekt zurückgibt, das nun bereit ist, Vorhersagen zu machen.
Bevor wir jedoch unsere erste Vorhersage in JS ausprobieren können, müssen wir das Bild ein wenig vorbereiten. Das Bild wird sicherlich nicht die richtigen Abmessungen haben, wenn es von der Handwriting-Klasse übernommen wird. Deshalb erstellen wir eine preprocessImage()-Methode, die sicherstellt, dass sie den Anforderungen des Modells entspricht.
Die Funktion tf.tidy() hilft, alle temporären Tensoren nach der Ausführung zu bereinigen, um Speicherlecks zu vermeiden.
preprocessImage(pixelData) {
const targetDim = 28,
edgeSize = 2,
resizeDim = targetDim-edgeSize*2,
padVertically = pixelData.width > pixelData.height,
padSize = Math.round((Math.max(pixelData.width, pixelData.height) - Math.min(pixelData.width, pixelData.height))/2),
padSquare = padVertically ? [[padSize,padSize], [0,0], [0,0]] : [[0,0], [padSize,padSize], [0,0]];
return tf.tidy(() => {
// convert the pixel data into a tensor with 1 data channel per pixel
// i.e. from [h, w, 4] to [h, w, 1]
let tensor = tf.browser.fromPixels(pixelData, 1)
// pad it until square, such that w = h = max(w, h)
.pad(padSquare, 255.0)
// scale it down to smaller than target
tensor = tf.image.resizeBilinear(tensor, [resizeDim, resizeDim])
// pad it with blank pixels along the edges (to better match the training data)
.pad([[edgeSize,edgeSize], [edgeSize,edgeSize], [0,0]], 255.0)
// invert and normalize to match training data
tensor = tf.scalar(1.0).sub(tensor.toFloat().div(tf.scalar(255.0)))
// Reshape again to fit training model [N, 28, 28, 1]
// where N = 1 in this case
return tensor.expandDims(0)
});
}Ok, Zeit für unsere Vorhersage. Wir erstellen eine Methode, die die Pixeldaten aus der Klasse Handwriting übernimmt, verarbeitet, eine Vorhersage macht und dann das wahrscheinlichste Zeichen abruft.
this.alphabet = "abcdefghijklmnopqrstuvwxyz";
this.characters = "0123456789" + this.alphabet.toUpperCase() + this.alphabet
predict(pixelData) {
let tensor = this.preprocessImage(pixelData),
prediction = this._model.predict(tensor).as1D(),
// get the index of the most probable character
argMax = prediction.argMax().dataSync()[0],
// get the character at that index
character = this.characters[argMax];
return character;
}Beachten Sie, dass Operationen auf den Tensoren in der JS-Laufzeit nicht direkt für uns zugänglich sind. Sie können auf der GPU ausgeführt werden und um unnötigen Datenverkehr zwischen CPU und GPU zu vermeiden, müssen Sie .dataSync() explizit aufrufen, um den Wert abzurufen.
Das war's, jetzt haben wir alles, was wir brauchen, um eine Vorhersage zu machen:
handwriting = new Handwriting;
model = new Model;
// run these commands once you've drawn a "j" for example
model.predict(handwriting.captureDrawing())
// >>> "j" (hopefully)Unsere Arbeit ist hier jedoch nicht wirklich erledigt. Die Web-App ist kaum interaktiv genug, um nützlich zu sein. Wir wollen die Leinwand leeren, sobald das Zeichen erhalten und vorhergesagt wurde, so dass wir für die nächste Vorhersage bereit sind. Deshalb müssen wir einen Timer einstellen, nachdem der Benutzer das Malen gestoppt hat. Dieser Timer wird jedes Mal abgebrochen, wenn der Benutzer die Leinwand wieder berührt, aber sobald wir eine bestimmte Zeit ohne Interaktion registrieren, erfassen wir, was gezeichnet wurde (nach einigen Experimenten scheinen 800 ms auf dem Desktop und 400 ms auf Touchgeräten eine gute Wahl zu sein). Fügen wir den folgenden Code zur Klasse Handwriting hinzu.
bindEvents() {
let hasTimedOut = false,
timerId = null,
isTouchDevice = 'ontouchstart' in window,
timeOutDuration = isTouchDevice ? 400 : 800;
this.canvas.on("mouse:down", (options) => {
// reset the canvas in case something was drawn previously
if(hasTimedOut) this.resetCanvas(false);
hasTimedOut = false;
// clear any timer currently active
if(timerId) {
clearTimeout(timerId);
timerId = null;
}
})
.on("mouse:up", () => {
// set a new timer
timerId = setTimeout(() => {
// once timer is triggered, flag it and run prediction
hasTimedOut = true;
let prediction = this.model.predict(this.captureDrawing());
console.log("prediction", prediction)
}, timeOutDuration);
})
}
resetCanvas(removeText = true) {
this.canvas.clear();
this.canvas.backgroundColor = "#fff";
}Die oben genannten Funktionen sind alles, was Sie benötigen, um eine interaktive Web-App zu erstellen, die handschriftliche Zeichen des Benutzers voraussagt. Allerdings könnten viele zusätzliche Funktionen gewünscht werden, um dies zu einer netten App zu machen, mit der man interagieren kann, wie z.B.: automatische Größenänderung der Leinwand mit dem Browserfenster, Anzeige der Ausgabe des Modells auf der Website, variable Strichbreite, Clear/Submit-Taste, Vorwärmung des Modells zur Verbesserung der Latenzzeit, etc. Leider würde dies bedeuten, dass dieser bereits lange Artikel noch länger wird.
Wenn Sie einen Blick auf den Quellcode des Endergebnisses werfen möchten, besuchen Sie unser Github-Repository, um das Projekt in seiner Gesamtheit herunterzuladen. Für eine Live-Demo schauen Sie sich den Iframe unten an oder klicken Sie hier für eine Vollbildversion der App.
Kontakt
Wenn Sie mit uns über dieses Thema sprechen möchten, kontaktieren Sie uns gerne und wir melden uns im Anschluss für ein unverbindliches Erstgespräch.