
Über 35.000 monatliche Downloads für unseren RAG-Benchmark-Datensatz T²-RAGBench
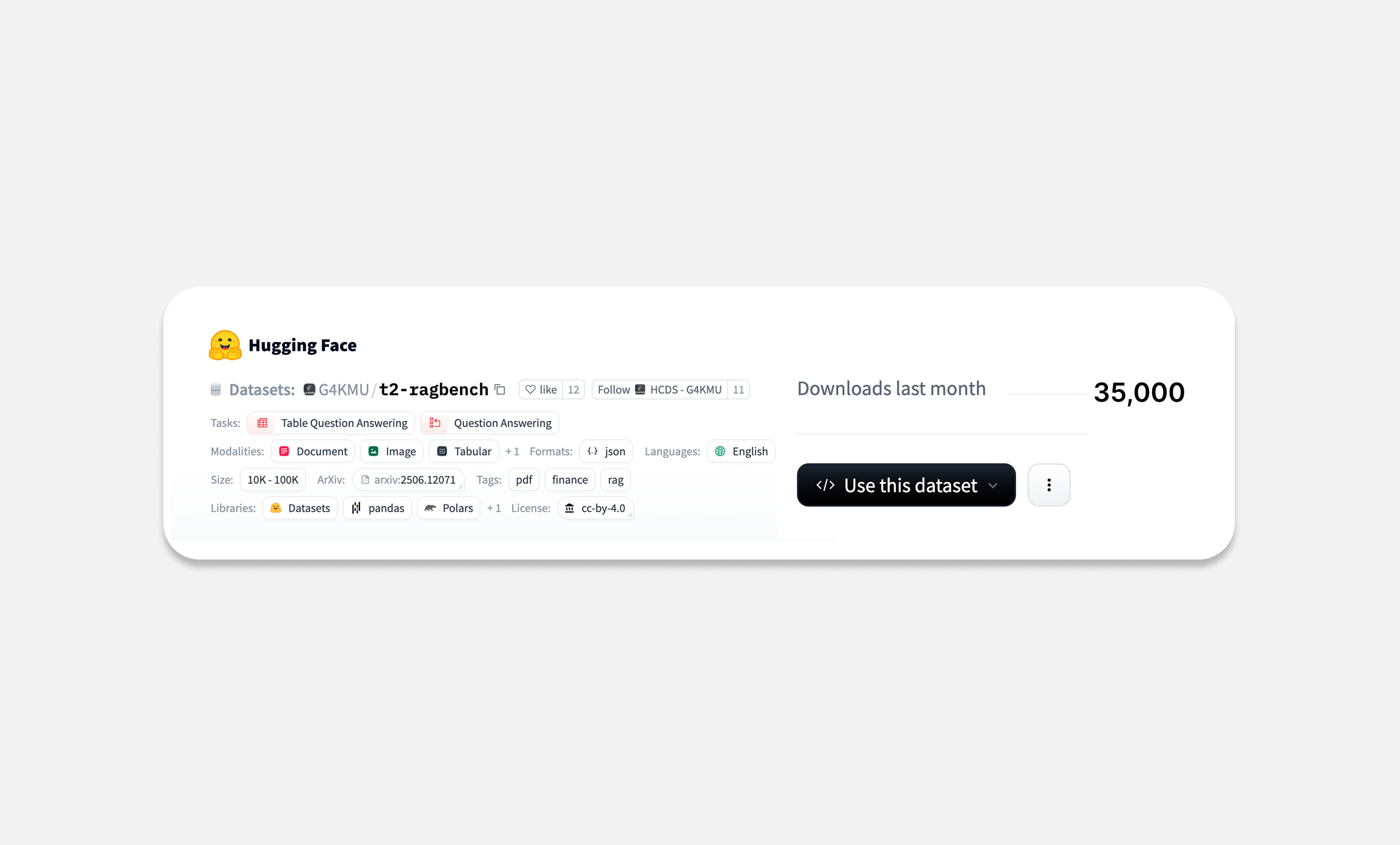
Unser neuer Benchmark-Datensatz für RAG-Systeme, T²-RAGBench, erfreut sich in der Machine-Learning-Community großer Beliebtheit und wird derzeit mehr als 35.000 Mal pro Monat heruntergeladen. Der Datensatz wurde in Zusammenarbeit mit dem Hub of Computing and Data Science (HCDS) der Universität Hamburg entwickelt und schließt eine wichtige Lücke bei der Evaluation von KI-Systemen, die mit der Analyse komplexer Finanzdaten beauftragt sind.
Die Lösung für Ambiguität in Retrieval-Schritten
Standard-Datensätze für Frage-Antwort-Systeme betrachten oft Situationen, in denen die KI im Voraus mit dem richtigen Kontext versorgt wird. In diesen Umgebungen sind vage Abfragen wie „Wie hoch war der Netto-Cashflow?“ funktionsfähig, da der Umfang begrenzt ist. In produktionsreifen RAG-Systemen, die Tausende von Dokumenten verwalten, führt eine solche Ambiguität jedoch zu Störungen bei der Informationsgewinnung. Es können mehrere Dokumente als relevant erscheinen, da sie alle Cashflow-Werte angeben, nicht jedoch vom speziell in dieser Situation interessanten Unternehmen, was es für Entwickler unmöglich macht, die Genauigkeit der Suche zu überprüfen.
T²-RAGBench führt kontextunabhängige Fragen ein, die Entitäten, Daten und Metriken spezifizieren und sicherstellen, dass jede Abfrage genau auf ein Ground-Truth-Dokument verweist.
Merkmale des Datensatzes und Methodik
Der im Rahmen des GENIAL4KMU-Projekts entwickelte Datensatz umfasst mehrere technische Attribute, die für die strenge Prüfung moderner KI entwickelt wurden. Seine Grundlage bildet ein umfangreicher Korpus von 23.088 Frage-Antwort-Paaren, die aus mehr als 7.300 realen Finanzberichten stammen und den für ein statistisch signifikantes Benchmarking erforderlichen Umfang bieten.
Um häufige Fehler bei der Informationsgewinnung zu beheben, behandelte das Team die Daten: Mehrdeutige Benutzeranfragen wurden systematisch in in sich geschlossene, präzise Fragen umformuliert. Dadurch wird sichergestellt, dass die Suche anhand eines einzigen, spezifischen Referenzdokuments überprüft werden kann und nicht anhand einer Reihe von oberflächlich relevanten Ergebnissen.
Darüber hinaus führt der Benchmark multimodale Komplexität ein, indem er von den Modellen anspruchsvolle numerische Schlussfolgerungen verlangt. Im Gegensatz zu Datensätzen, die sich ausschließlich auf Prosa konzentrieren, fordert T²-RAGBench die Systeme heraus, Informationen aus unstrukturierten narrativen Texten und komplexen Markdown-Tabellen zu synthetisieren. Erste grundlegende Erkenntnisse des Forschungsteams unterstreichen die Schwierigkeit dieser Aufgabe und identifizieren Hybrid BM25 – eine Kombination aus Stichwort- und semantischer Suche – als die effektivste Suchstrategie für die Navigation in diesem spezifischen Finanzdatenformat.
Zusammenarbeit
Das Projekt stellt eine erfolgreiche Brücke zwischen Industrie und Wissenschaft dar. Zu den wichtigsten Mitwirkenden der Initiative gehören Jan Strich, Enes Kutay İşgörür, Dr. Maximilian Trescher, Dr. Chris Biemann und Dr. Martin Semmann. Das Forschungsteam hat die Ressourcen öffentlich zugänglich gemacht, um weitere Innovationen im Bereich von LLMs und der Informationsgewinnung zu fördern.
Technische Ressourcen:
- Zugriff auf Datensätze: Verfügbar über Hugging Face
- Leistungsüberwachung: Eine interaktive Rangliste steht Forschern zum Vergleich von Modell-Benchmarks zur Verfügung.