
Wie Google Cloud Machine Learning-Projekte beschleunigt

Da nicht nur die Komplexität der Machine Learning (ML)-Modelle, sondern auch die Größe der Datensätze weiter wächst, steigt auch der Bedarf an Computerleistung. Während die meisten Laptops heute eine erhebliche Arbeitslast bewältigen können, ist die Leistung für unsere Zwecke bei dida oft nicht ausreichend. Im Folgenden führen wir Sie durch einige der häufigsten Engpässe und zeigen, wie Cloud Services helfen die Dinge zu beschleunigen.
Hintergrund
Das Training eines komplexen Modells auf einem ausreichend großen Datensatz kann Tage, manchmal Monate dauern, bis es auf einem normalen Laptop durchgeführt werden kann, was es weder in Bezug auf die Hardware noch auf Zeitvorgaben zu einer praktikablen Option macht. Um diese Probleme zu entschärfen, nutzt dida die Cloud ML-Infrastruktur von Google: Damit können lange Trainings auf angepasster, leistungsstarker und von Bürozeiten unabhängiger Remote-Hardware durchgeführt werden und gleichzeitig bleibt lokale Hardware für unsere Mitarbeiter verfügbar.
Auch wenn die Trainingszeit in einigen Projekten ein Engpass für eine schnelle Iteration sein kann, ist sie bei den meisten ML-Projekten kaum der einzige zeitaufwändige Teil. Obwohl jedes Projekt spezifische Zielen und Herausforderungen aufweist, gibt es bestimmte wiederkehrende Aspekte der meisten Data Science-Probleme, die immer wieder behandelt werden müssen. Die Möglichkeit einige dieser Prozesse zu automatisieren und zu rationalisieren spart uns Zeit, die wir für fruchtbarere Dinge aufwenden können als nur die Konfiguration der Hard- und Software der Maschine.
Die am häufigsten vorkommenden Teile unserer Prozesse lassen sich wie folgt zusammenfassen: Datenerfassung, Analyse und Vorverarbeitung von Daten, Training eines Modells auf den Daten und schließlich Auswertung, Visualisierung und/oder Distribution des trainierten Modells. Im Folgenden wird jeder Prozess mit Hinweisen und Tipps zur Beschleunigung durch Cloud Services näher beschrieben.
Datenerfassung
Die meisten der von uns verwalteten Datensätze sind text- und bildbasiert. Erstere sind in der Regel relativ klein, vor allem in komprimierter Form, was den Datentransfer zu einer eher trivialen Aufgabe macht. Die Bilddatensätze können jedoch enorm sein, manchmal in der Größenordnung von Hunderten von Gigabyte. Da einige von uns remote auf Laptops mit begrenztem Speicherplatz arbeiten, ist das Herunterladen der Datensätze auf einen Computer mit einer externen Bandbreite von 1 Gbit/s eine gute Option.
Zusätzliche Einschränkungen wie Downloadkontingente und Ratenbegrenzung sind keine Seltenheit. Das bedeutet oft, dass wir die Bilder nach dem Download aus der Quelle selbst an Kollegen weiterleiten müssen, um die Grenzen der Datenmenge einzuhalten. Cloud-Laufwerke machen dies einfacher, insbesondere bei persistenten Speicherplatten, die zwischen mehreren Compute-Instanzen im schreibgeschützten Modus gemeinsam genutzt werden können. Sollte der schreibgeschützte Modus für die Aufgabe keine sinnvolle Option sein, besteht immer die Möglichkeit, die Maschinen über die internen IP-Adressen zu verbinden. Dies ergibt Netzwerkgeschwindigkeiten zwischen 2-32 Gbit/s je nach CPU-Konfiguration, was mehr als ausreichend ist, wenn man bedenkt, dass die Lese-/Schreibgeschwindigkeiten auf den Standard-Cloud Filestore SSDs zwischen 0,1-1,2 GBit/s (oder 0,8-9,6 Gbit/s) liegen.
Analyse und Vorverarbeitung von Daten
Daten gibt es in vielen Formen und Größen. Eine Sache, die fast jeder Datenwissenschaftler erlebt hat, ist, dass Rohdaten fast immer in eine oder mehrere der folgenden Kategorien fallen: schlecht formatiert, unvollständig, falsch gekennzeichnet, mit Anomalien, unausgewogen, unstrukturiert, zu klein, etc. Der alte Slogan "Ihre Ergebnisse sind nur so gut wie Ihre Daten" hat definitiv seine Gültigkeit. Daher kann und wird viel Zeit mit der Aufbereitung der Rohdaten verbracht werden, damit ein Modell sinnvoll trainiert werden kann. Klicken Sie auf den obigen Link, wenn Sie mehr über einige der häufigsten Fallstricke erfahren möchten und wie Sie diese vermeiden können.
Ein Werkzeug, das uns nach dem Besuch des Google Machine Learning Bootcamps in Warschau aufgefallen ist, ist das DataPrep-Tool, das die Handhabung von Excel-ähnlichen Daten wesentlich komfortabler macht. Die gängige Art, mit unstrukturierten tabellarischen Daten umzugehen, besteht darin, jede Spalte einzeln durchzugehen, nach Anomalien, falsch geschriebenen Duplikaten, seltsamen inkonsistenten Datumsformaten zu suchen und manuell eine Regel oder Ausnahme für jeden dieser seltsamen Datensätze zu programmieren. Das bläst die Codebasis schnell auf, ist eine mühsame Aufgabe und lässt sich schwer verallgemeinern. DataPrep löst dieses Problem eleganter: Mit einer intuitiven grafischen Übersicht können Sie so genannte "Rezepte" erstellen und auf Ihre Rohdatenquelle anwenden. Diese Rezepte transformieren Ihre Rohdaten Schritt für Schritt und geben eine saubere Datentabelle aus, die Sie dann an Ihr ML-Modell weiterleiten können, bereit für das Training. Wenn Sie neugierig sind, wie das im Detail funktioniert und einige Minuten Zeit haben, empfehlen wir Ihnen, sich das Video Advanced Data Cleanup Techniques using Cloud Dataprep vom Cloud Next '19-Event anzusehen.
Training
Nachdem Sie ein Modell sorgfältig konstruiert haben, ist es an der Zeit, es anhand der verfügbaren Daten zu trainieren. Im besten Fall müsste dies nur einmal geschehen. Wie die meisten Data Scientists jedoch erfahren haben, handelt es sich hierbei um einen sehr iterativen Prozess, bei dem Hyperparameter abgestimmt, das Modell überarbeitet und optimiert, Verlustfunktionen verglichen und verbessert werden, etc.
Betrachten wir zum Beispiel die Abstimmung von Hyperparametern. Für jeden neuen Hyperparameter, der in den Mix eingeführt wird, kann die Zeitkomplexität exponentiell zunehmen. Angenommen, Sie haben drei Hyperparameter, die Sie einstellen müssen, sagen wir: Lernrate, Batchgröße und Kerneltyp. Wenn diese alle vier verschiedene Werte haben, die Sie testen möchten, werden Sie am Ende 43 = 64 verschiedene Kombinationen haben.
Dies ist kein großes Problem, wenn der Datensatz klein ist, eine beliebte Grid-Suchmethode kann oft auf einer Laptop-CPU über eine Reihe von Hyperparameter-Permutationen durchgeführt werden, bis eine optimale Kombination innerhalb eines angemessenen Zeitraums gefunden wurde. Wenn die Modellkomplexität und/oder der Datensatz jedoch wächst, neigen die Dinge dazu, schnell zu eskalieren. Angenommen, eine Trainingseinheit dauert durchschnittlich 24 Stunden, was nicht ungewöhnlich ist: Dann würde die Optimierung der oben genannten Hyperparameter mehr als 2 Monate Trainingszeit erfordern.
Also, was sind dann die Optionen? Da wir möglicherweise nicht in der Lage sind, die Anzahl der Hyperparameter, die wir testen müssen, zu verringern, besteht die verbleibende Option darin die 24-Stunden-Trainingseinheiten zu reduzieren. Hier kommt die vertikale und horizontale Skalierung zur Anwendung, d.h. die Erhöhung von Speicher und Rechenleistung sowie die Parallelisierung der Berechnungen auf mehreren Maschinen. Dies ist möglich, denn wenn wir uns ansehen, welche Art von Berechnungen unter der Haube durchgeführt werden, stellt sich heraus, dass die meisten neuronalen Netzwerkarchitekturen als Matrizen dargestellt werden können. Die Multiplikations- und Additionsoperationen, die auf diesen Matrizen durchgeführt werden, können auf einer GPU durchgeführt werden. Genau dafür ist ein Grafikprozessor optimiert, denn auch beim Rendern von Grafiken sind Matrixmultiplikationen die häufigste Aufgabe.
Heute bieten ASICs wie die TPU, die speziell für diese Art von Operationen entwickelt wurden, eine noch höhere Leistung. Wang, Wei und Brook an der Harvard University führten ein Deep Learning Benchmarking mit den neuesten Hardwarekonfigurationen in der Google Cloud durch, wie in der folgenden Tabelle dargestellt, und das Ergebnis ist eindeutig. GPUs führten über 60 Mal und TPUs über 200 Mal mehr Berechnungen durch als die konkurrierende CPU pro Zeiteinheit. In unserem obigen Beispiel könnte die Dauer der Hyperparametereinstellung von ca. 2 Monaten auf ca. 8 Stunden reduziert werden. Obwohl andere Aufgaben weniger Nutzen aus diesen Hardwareoptionen in Bezug auf die Rechengeschwindigkeit ziehen könnten, ist dieser Leistungsgewinn schwer zu ignorieren.
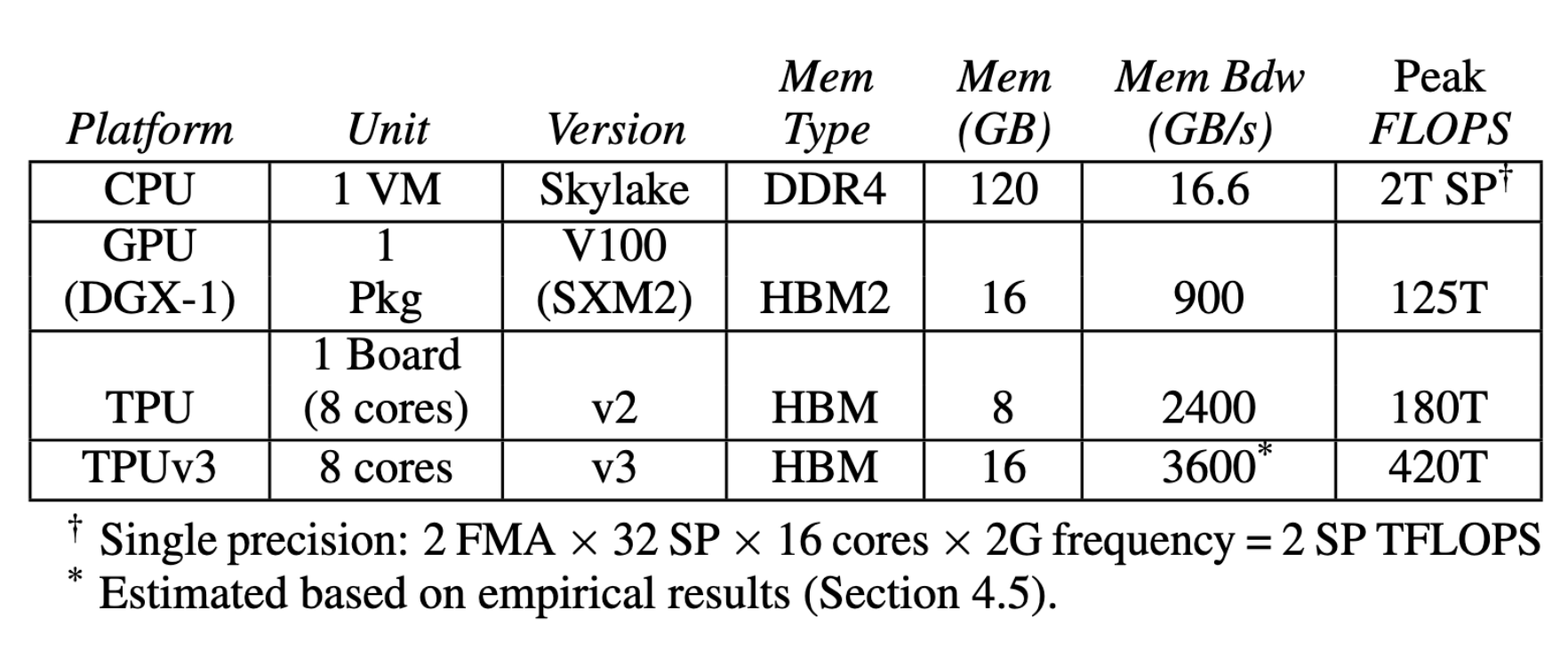
Deshalb setzen wir auf die Google Compute-Infrastruktur, in der jeder Mitarbeiter die Hardware einer Maschine konfigurieren kann, die auf seine spezifischen Bedürfnisse zugeschnitten ist. Die Hardware-Optionen ändern sich ständig, aber wenn Sie an den spezifischen Optionen interessiert sind, die gerade verfügbar sind, werfen Sie einen Blick in die Dokumentation.
Modelldistribution
Sobald das Modell trainiert und bewertet wurde und das Ergebnis zufriedenstellend ist, ist es an der Zeit, es zu veröffentlichen, damit Kollegen, Kunden, Endbenutzer usw. es selbst testen können. Dies kann natürlich auf der eigenen bestehenden Serverinfrastruktur erreicht werden, unabhängig davon, ob diese von Amazon AWS, Microsoft Azure oder einem anderen Cloud-Anbieter oder selbst gehosteten Servern usw. betrieben wird. Die Hosting-Möglichkeiten sind heute reichlich vorhanden und mit Hilfe von Docker und anderen Softwarelösungen haben wir in der Vergangenheit kundenspezifische Projekte auf allen Arten von Plattformen implementiert, um sicherzustellen, dass sie sich gut in die bestehende Produktionsumgebung unserer Kunden integrieren lassen.
Eine praktische Möglichkeit, das Modell zu deployen, besteht darin, eine Webinstanz zu erstellen, die die Ein- und Ausgabe Ihres Modells in eine REST-API umwandelt, die über den Browser, eine mobile App oder andere Server zugänglich ist. Zwei Bibliotheken, die sich für diese Aufgabe bewährt haben, sind Flask und FastAPI, die es uns ermöglichen, eine REST-API in allen Arten von Umgebungen einzusetzen. Aber aus Gründen der Konsistenz zeigen wir Ihnen, wie dies in der Google Cloud geschieht: Zuerst exportieren Sie Ihr Modell, dann deployen sie es und stellen es schließlich über eine REST-API zur Verfügung.
Sobald Ihr Modell einsatzbereit ist, ist es relativ trivial, sicherzustellen, dass es automatisch skaliert wird, um eine große Anzahl von Benutzern zu bedienen. Sie können Workload-Schwellenwerte konfigurieren, bei denen neue Instanzen automatisch gestartet werden. Das System verkleinert sich automatisch wieder, wenn die Anzahl der Benutzer sinkt. Lesen Sie hier mehr über die Node-Zuordnung für die Online-Vorhersage.
Fazit
Oben haben wir einen allgemeinen Überblick über die häufigsten Phasen des maschinellen Lernens bei dida gegeben: Datenerfassung, Analyse und Vorverarbeitung von Daten, Training eines Modells auf den Daten und schließlich Auswertung, Visualisierung und/oder Distribution des trainierten Modells. Auch wenn Ihre Projekte anders aussehen mögen, hoffen wir, dass wir Ihnen bei der Entwicklung Ihrer eigenen Projekte in Zukunft einige nützliche Ideen geliefert haben.
Kontakt
Wenn Sie mit uns über dieses Thema sprechen möchten, kontaktieren Sie uns gerne und wir melden uns im Anschluss für ein unverbindliches Erstgespräch.