
Mit ConvNets Wolken auf Satellitenbildern erkennen

In diesem Post werde ich erklären, wie wir das Problem der Erkennung konvektiver Wolken anhand von Satellitendaten angegangen sind. Ich werde erklären, was genau wir suchen (und warum!) und näher auf den Machine Learning-Ansatz eingehen, den wir verwendet haben.
Dieser Beitrag wird aus vier Teilen bestehen:
Zuerst werden wir konvektive Wolken vorstellen und einen kurzen Überblick über das Problem geben.
In Abschnitt 2 werden wir die Satellitendaten erläutern, mit denen wir arbeiten.
In Abschnitt 3 besprechen wir, wie wir mit dem manuellen Labelling der Daten umgehen, was eine besonders schwierige Aufgabe ist, welche die Verwendung einiger externer Daten erfordert.
Schließlich geben wir in Abschnitt 4 einen kurzen Überblick über die von uns verwendete neuronale Netzwerkarchitektur, das U-Net, und wie wir es trainieren.
Was sind Konvektionswolken?
Konvektionswolken, sind, wie der Name schon sagt, Wolken, die einen physikalischen Prozess namens Konvektion enthalten:
Warme Luft in Bodennähe ist leichter als die Umgebungsluft, so dass sie nach oben steigt.
Wenn die Luft aufsteigt, kühlt sie sich ab, ab einem bestimmten Punkt wird sie schwerer als die Luft um sie herum und beginnt wieder zu fallen.
Die Luft beginnt sich wieder zu erwärmen und der Zyklus beginnt neu.
Die Konvektion ist ein sehr allgemeiner Prozess, der überall stattfindet, vom Kochtopf bis zur Sonnenoberfläche, also konzentrieren wir uns darauf, wie das in den Wolken konkret aussieht.
Erstens bildet die Feuchtigkeit, die von der Land- oder Meeresoberfläche verdunstet, eine so genannte Cumuluswolke. Wenn die Wolke im Vergleich zur Umgebungsluft warm genug ist, steigt sie weiter an und wird zu einer hoch aufragenden Cumuluswolke ("towering cumulus", TCU). An diesem Punkt beginnt die Konvektion innerhalb der Wolke.

Wenn die Wolke weiter steigen kann, wird sie schließlich eine so genannte Inversion erreichen. Dies ist ein Punkt, an dem die Luft anfängt, wärmer statt kälter zu werden, wenn sie aufsteigt. Die Wolke kann nicht weiter als hier ansteigen, also beginnt sie sich zu verflachen. Dann wird sie zu einer Cumulonimbus (CB). Diese sind ganz leicht an ihrer markanten Ambossform zu erkennen.

CBs können extrem starke Auf- und Abwärtsbewegungen erzeugen, die für Flugzeuge potentiell gefährlich sind, daher ist es wichtig zu wissen, wo sich diese Wolken befinden. Es gibt mehrere verschiedene Methoden zur Erkennung konvektiver Wolken mit Wetterradars oder Blitzeinschlägen, aber in dieser Serie werden wir über die Verwendung von Satellitenbildern diskutieren. Ziel ist es, ein Satellitenbild von EUMETSAT zu nehmen und es in drei Bereiche zu unterteilen, CB, TCU und keine konvektiven Wolken.
"Meteosat Second Generation"-Daten und wie sie zu nutzen sind
Die von uns verwendeten Daten stammen von zwei Satelliten: Meteosat 10 und 11. Diese befinden sich im geostationären Orbit über Afrika (d.h. sie brauchen volle 24 Stunden, um die Erde entlang des Äquators zu umkreisen, so dass sie über der gleichen Position auf der Erdoberfläche bleiben). Meteosat 11 macht alle 15 Minuten ein Bild der gesamten Erdscheibe und Meteosat 10 alle 5 Minuten ein Bild der nördlichen Hemisphäre. Der Grund dafür ist, dass der Satellit nicht wie eine normale Kamera funktioniert, die alle Pixel gleichzeitig aufzeichnet, sondern sich dreht und jeweils ein Pixel aufnimmt, bevor er in der nächsten Zeile beginnt. Das bedeutet natürlich, dass die Abbildung einer kleineren Teilmenge der Scheibe schneller ist als der gesamten Scheibe. Wir beschneiden und resamplen das Bild so, dass es nur Deutschland abdeckt, so dass wir beide Satellitenbilder austauschbar verwenden können.
Diejenigen unter Ihnen, die sich besonders für die technischen Aspekte der von uns verwendeten Daten interessieren, finden das Meteosat Second Generation Level 1.5 Image Data Format in diesem Dokument ausführlich beschrieben.
Ein normales Bild besteht aus drei Werten oder Kanälen: für jedes Pixel rot, grün und blau. Die relativen Werte beschreiben die Farbe des Pixels. Wenn das Hauptziel der Bildgebung jedoch nicht die menschliche Betrachtung, sondern die Extraktion quantitativer Informationen ist, dann gibt es keinen Grund, sich auf diese drei Kanäle zu beschränken. Diese Satellitendaten haben 12 Kanäle, die in der folgenden Tabelle beschrieben sind:
Kanal |
Beschreibung |
VIS0.6 |
Der erste visuelle Kanal. Er detektiert Licht im orangen Bereich. |
HRV |
Der hochauflösende visuelle Kanal. Er detektiert rotes Licht dreimal höherer Auflösung als andere Kanäle. |
VIS0.8 |
Dieser detektiert sehr rotes Licht, am Rande der Sichtbarkeit. |
IR1.6 |
Nahinfrarot. Dieses Licht ist für das menschliche Auge unsichtbar und nur am Tag vorhanden. |
IR3.9 |
Dies ist ein Kanal zwischen den obigen "Solarkanälen" (die nur tagsüber verfügbar sind) und den Wärmekanälen unten, die ständig erscheinen. Tagsüber erfasst es reflektiertes Sonnenlicht und nachts durch Wärme abgestrahltes Licht. |
WV6.2 and WV7.3 |
Wasserdampfkanäle. Diese erfassen die Infrarotstrahlung von Wasserdampf in der Atmosphäre. |
IR8.7 |
Einer der IR-Fensterkanäle. Diese erkennt Infrarotstrahlung, die nicht von der Atmosphäre absorbiert oder emittiert wird, also entweder vom Boden oder von Wolken kommt. |
IR9.7 |
Diese erkennt IR-Strahlung, die vom Ozon in der Atmosphäre abgegeben wird. |
IR10.8 and IR12.0 |
Weitere IR-Fensterkanäle, die Wolken auf der Oberfläche zeigen. |
IR13.4 |
Dieser Kanal erfasst die vom CO2 emittierte Strahlung. |
Also haben wir hier viele Informationen! Wir werden all dies unserem Modell zur Verfügung stellen, um Vorhersagen zu treffen.
Labeling
Wir brauchen auch einige Labels, um ein Modell zu trainieren. Leider bedeutet das manuelles Labeln! Dazu müssen wir die Daten in einem Format präsentieren, das die konvektiven Wolken hervorhebt. Der naheliegende Ausgangspunkt ist die Anzeige des HRV-Kanals.

Dies ist ein guter Anfang, aber es gibt noch nicht genügend Informationen, um eine Entscheidung zu treffen. Eine der nützlichsten Messgrößen ist die Temperatur der Wolken, da sie ein guter Indikator für die Höhe der Wolkendecke ist. Dazu legen wir die Temperaturinformationen als Farbe übereinander.

Schließlich können wir dem Labeler auch ein Radarbild zur Verfügung stellen. Es gibt eine Reihe von Radarstationen in ganz Deutschland. Funkwellen werden von Wassertropfen, d.h. Regen, reflektiert. Dies ist sehr hilfreich, da Cumulonimbus-Wolken normalerweise viel Regen produzieren. Sie sind im Radarbild sehr gut an der hohen Intensität und dem hohen Gradienten des Regens im Vergleich zu anderen regenerzeugenden Wolken wie z.B. schichtförmigen Wolken zu erkennen.

Das Radar wird hauptsächlich vom Regen reflektiert, so dass wir die charakteristischen kleinen, aber intensiven Regenfälle der konvektiven Wolken erkennen können, im Gegensatz zu den breiteren Gebieten mit geringeren Gradienten, die mit dem Frontalsystem verbunden sind.
Nun, da wir wissen, wie man die CBs labelt, lassen Sie uns überlegen, wie wir die TCUs labeln können. Cumuluswolken (ob hoch aufragend oder nicht) sind eigentlich recht leicht zu erkennen. Sie erscheinen normalerweise als große Felder kleiner heller Wolken.
Dann haben wir zwei Schwierigkeiten: erstens, dass es unpraktisch wäre, jede Wolke einzeln zu kennzeichnen, und zweitens, die hoch auftürmenden Cumuluswolken von den übrigen zu unterscheiden. Glücklicherweise können wir hier ein wenig meteorologisches Wissen einsetzen. Hoch aufragende Cumuluswolken sind höher und bestehen meist aus Eiskristallen und nicht aus Wassertropfen, daher haben sie ein höheres Albedo (d.h. sie reflektieren einen größeren Teil des Lichts, das sie erhalten). Da der Satellit die Anzahl der empfangenen Photonen misst, müssen wir zur Berechnung des Albedos nur die einfallende Strahlung schätzen. Glücklicherweise ist die Sonnenleistung ziemlich konstant, so dass wir nur den solaren Zenitwinkel benötigen, den wir leicht aus der Tages- und Jahreszeit berechnen können. Dann müssen wir nur noch von Hand einen guten Schwellenwert finden, um sicherzustellen, dass wir die Wolken richtig trennen.

Man sieht, dass die CB-Wolken eher kompakte Regionen mit hoher IR-Reflektivität und die TCU eher kleinere verstreute Wolken sind.
Nachdem wir gelernt haben, wie man gelabelte Daten erhält, können wir nun diskutieren, wie wir ein Modell bauen werden, um unsere Vorhersagen zu treffen.
Bildsegmentierung mit U-Nets
Im Kern ist dies ein semantisches Segmentierungsproblem, d.h. wir müssen jeden Pixel im Bild in drei Klassen einteilen: CB, TCU und keine konvektive Wolke. Eine Reihe von verschiedenen Algorithmen wurden für diese Klasse von Problemen vorgeschlagen, aber der aktuelle Stand der Technik ist eine neuronale Netzwerkarchitektur namens U-Net.
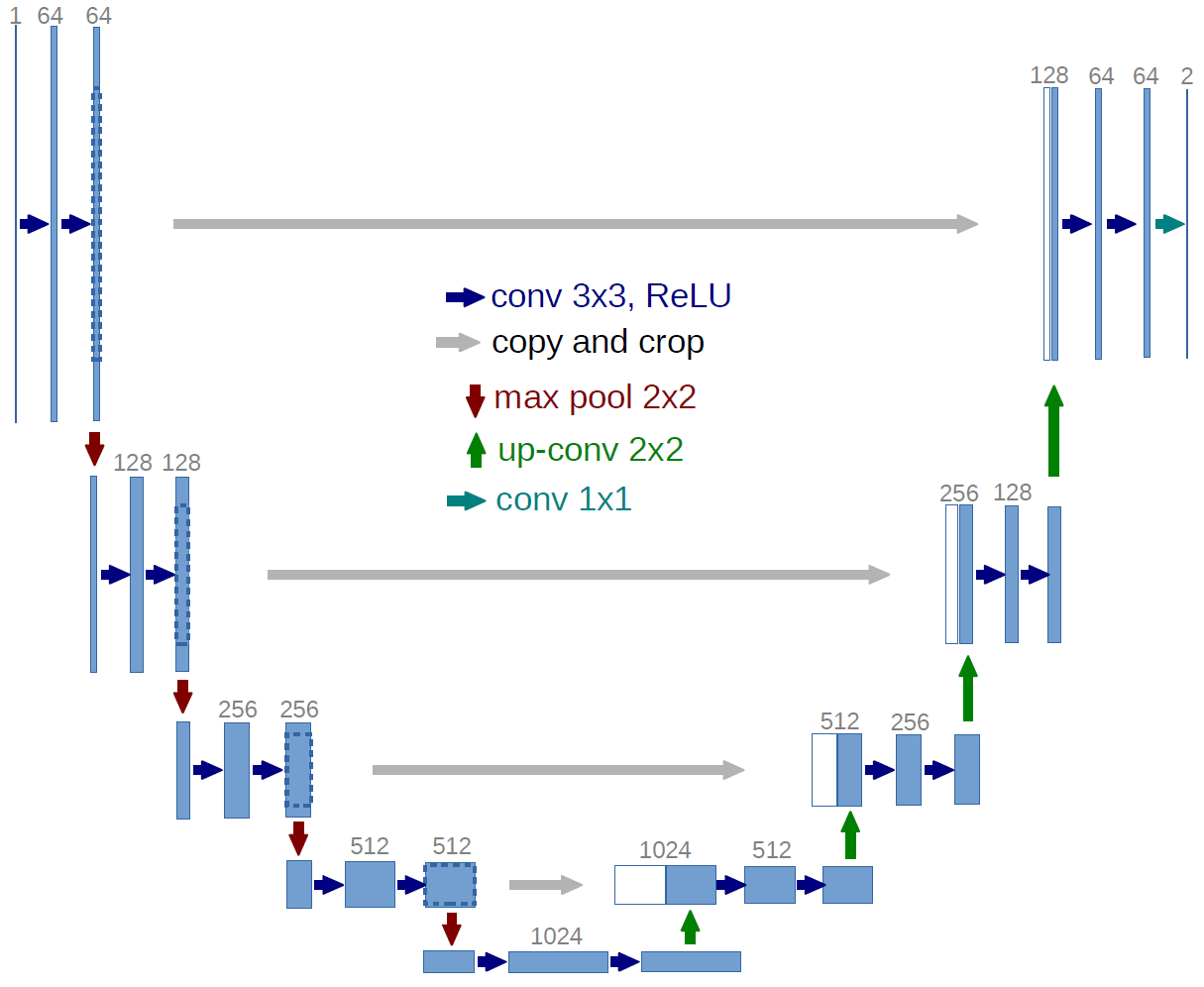
Das U-Net besteht aus einer Reihe von Downsampling-Blöcken, gefolgt von der gleichen Anzahl von Up-Sampling-Blöcken. Wir haben Skip-Verbindungen, die Punkte entlang des Downsamplings mit Punkten im Up-Sampling-Bereich verbinden. Die Idee dabei ist, dass die späteren Layer sowohl auf höherstufigere Features aus dem downgesampleten Pfad als auch auf niedrigstufigere Features aus der Skip-Verbindung zugreifen können, die mehr lokale räumliche Informationen erhalten.
Das ursprüngliche Netzwerk prognostizierte zwei Klassen aus einem Graustufenbild, so dass es einen Eingangskanal und zwei Ausgangskanäle verwendete. Wir werden wieder zwei Klassen vorhersagen, aber wir werden das zwölfkanalige Meteosat-Bild verwenden, also werden wir mit zwölf Kanälen beginnen und nicht mit dem einen Kanal, den das ursprüngliche U-Net verwendet hat.
Wir haben auch eine Reihe anderer kleinerer Änderungen vorgenommen, um unserem Problem besser gerecht zu werden. Wir haben die Anzahl der Rekursionen von 4 auf 5 erhöht und die Up-Convolution durch einen Pixelshuffle ersetzt.
Putting it all together
Wir haben jetzt unsere gelabelten Daten und ein Modell. Wir müssen es jetzt trainieren.
Die Rohdaten kommen in 1024 x 1024 Bildern, was ziemlich groß ist, ja sogar so groß, dass wir auf sehr kleine Batchgrößen beschränkt wären, wenn wir auf die gesamten Bilder trainieren würden. Wenn wir die Bilder downgesamplet hätten, würden wir die im HRV-Kanal enthaltenen Informationen verlieren, so dass wir stattdessen das Bild (und die Labels) in 16 kleinere Bilder der Größe 256 x 256 aufteilen. Dies ermöglicht es uns, ziemlich große Batchgrößen von ~64 Bildern zu verwenden, so dass wir Techniken wie Batchnorm wirklich nutzen und sehr hohe Lernraten verwenden können, um Modelle schnell zu trainieren.
Wir verwenden ein paar Tricks, um das Beste aus unseren Daten herauszuholen:
Erstens Datenaugmentierung. Normalerweise können wir beim Training eines ConvNets auf Satellitenbildern jede beliebige Ausrichtung der Bilder verwenden, aber hier haben wir einen Nachteil, da sich der Satellit in einer festen Position relativ zur Erdoberfläche befindet. Das bedeutet zum Beispiel, dass Wolkenschatten immer leicht südlich der Wolke erscheinen. Wir können daher nur eine begrenzte Anzahl von Techniken zur Datenvermehrung einsetzen. Wir verwendeten zufällige horizontale Spiegelungen und Drehungen von bis zu 10 Grad.
One cycle learning rate annealing. Wir beginnen mit einer sehr niedrigen Lernrate und erhöhen sie linear auf einen Maximalwert (0,01 schien gut zu funktionieren) im Laufe des Trainings, bevor wir sie linear wieder verringern. Dies gibt uns den Vorteil des langsamen "Aufwärmens", einer hohen Lernrate zur Beschleunigung des Trainings und einem Schwanz mit einer niedrigen Lernrate zur Feinabstimmung am Ende.
Mixed precision training. Dies ist bei älteren GPUs nicht möglich, erlaubt es uns aber, Speicher zu sparen und somit größere Batchgrößen zu verwenden, ohne die Genauigkeit zu beeinträchtigen.
Schließlich können wir aus dem Modell eine reale Vorhersage erstellen und visualisieren:

Hier haben wir CBs in blau und TCUs in grün markiert. Sie sehen, dass wir die großen runden CB-Wolken richtig klassifiziert haben, ohne zu viel des Frontalsystems falsch zu beschriften (dies ist ein häufiger Fehlermodus bestehender Nicht-Deep Learning-Ansätze. Wir haben auch die kleinen TCU-Wolken korrekt markiert.
FYI: Wir haben auch ein Projekt durchgeführt, bei dem wir die Erkennung konvektiver Wolken für den Deutschen Wetterdienst (DWD) automatisiert haben.
Kontakt
Wenn Sie mit uns über dieses Thema sprechen möchten, kontaktieren Sie uns gerne und wir melden uns im Anschluss für ein unverbindliches Erstgespräch.