
Planet-Scope Labels auf Sentinel-2-Bilder übertragen

In diesem Blog-Artikel möchte ich kurz den Prozess der Migration von Labels von Planet Scope auf Sentinel-2-Bilder beschreiben. Ich werde den Prozess Schritt für Schritt erklären und die notwendigen Codezeilen bereitstellen.
Der Code kann leicht angepasst werden, um Labels zwischen anderen Satelliten als in unserem Beispielfall zu migrieren.
Einführung
Eine der klassischen Anwendungen von maschinellem Lernen war schon immer die Fernerkundung. Die schiere Menge der zu analysierenden Daten macht es zu einer Notwendigkeit, den Prozess so weit wie möglich zu automatisieren. Zur Veranschaulichung: Ein 100 km² großes Sentinel-2-Bild besteht aus ~100 Megapixeln, für deren Durchsicht auf einem Full-HD-Bildschirm 5 Stunden und für eine Sektoranalyse 6 Minuten benötigt würden. Stellen Sie sich vor, Sie wollen den Urbanisierungsprozess in einem Land verfolgen und suchen daher nach Veränderungen der Gebäudegrundrisse auf den Satellitenbildern. Anstatt das Bildmaterial manuell durchzugehen, um Veränderungen zu entdecken, könnten Sie einen Trainingsdatensatz erstellen, der aus Satellitenbildern und entsprechenden Beschriftungen besteht, um ein neuronales Netzwerk (NN) zu trainieren, das für Sie Gebäude in der Szenerie erkennt. Oder vielleicht haben Sie online einen Trainingsdatensatz entdeckt, der Ihren Anwendungsfall bereits abdeckt.
Ein Problem, dem Sie begegnen könnten, ist, dass das Labeling auf einer Datenquelle durchgeführt wurde, die sich von den Ihnen zur Verfügung stehenden Satellitendaten oder einer Datenquelle, die Sie verwenden möchten, unterscheidet. Daher muss die Bild <> Labeling-Kombination migriert oder an den von Ihnen gewählten Sensor angepasst werden. Einige Gründe, warum Sie das tun müssen, könnten sein:
Der aktuell verwendete Satellit wird außer Betrieb genommen (z.B. Landsat 7 sollte bis 2004 in Betrieb sein und funktioniert immer noch, könnte aber irgendwann plötzlich abgeschaltet werden)
Höhere Genauigkeiten werden benötigt, also wird eine Quelle mit höherer Auflösung verwendet (z. B. Wechsel von 10m Sentinel-2 zu <1m WorldView-1)
Umstieg auf eine andere Beobachtungstechnologie (z. B. Wechsel von optischem Sentinel-2 zu Radar (SAR) Sentinel 1)
Umstellung von kommerziellen auf freie Quellen (z.B. Planet Scope auf Sentinel-2)
Es gibt sicherlich noch mehr Gründe, den Sensor zu wechseln, aber unabhängig von der Motivation ist allein die Zunahme der Möglichkeiten, dies zu tun, beeindruckend. Dieser Fachartikel veranschaulicht diese Tatsache sehr schön, da wir seit dem Start des ersten Erdbeobachtungssatelliten (EO) Landsat 1 im Jahr 1972 ein exponentielles Wachstum an operativen Satelliten beobachten können.
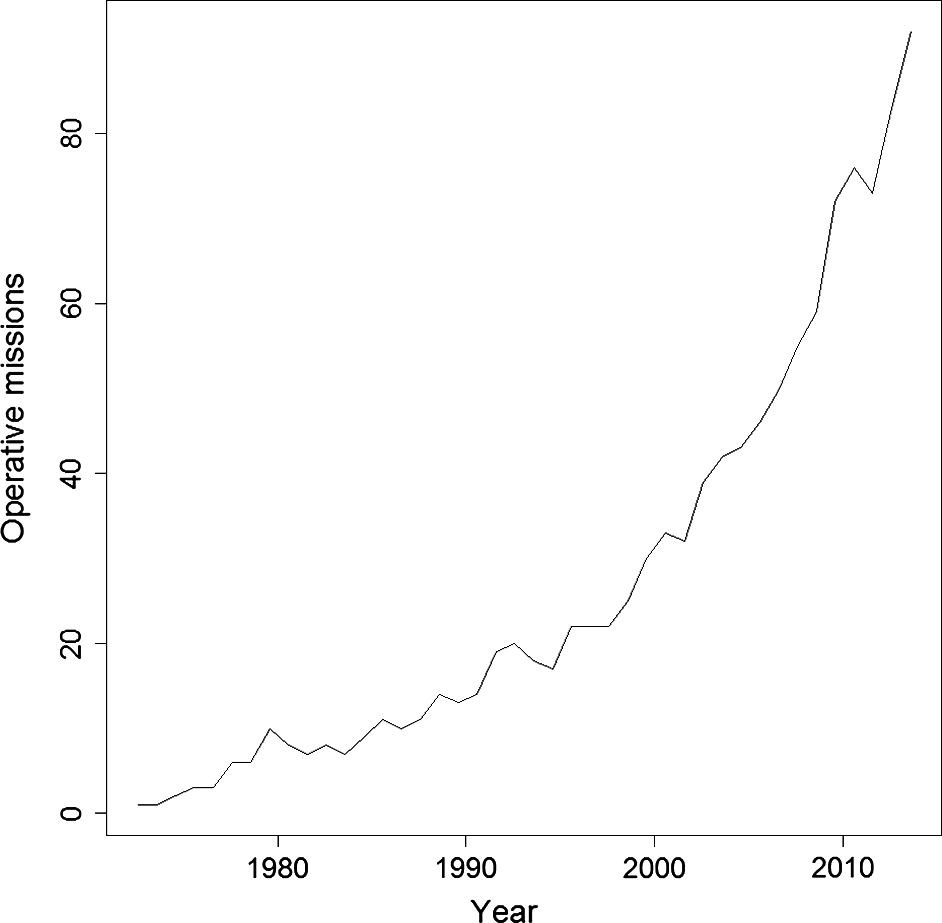
Heute (2021) sind mehr als 900 solcher Satelliten im Einsatz, daher scheint sich der Trend sogar zu beschleunigen. Der letzte Punkt, der zur Wiederverwendung von Labels motiviert, ist die Tatsache, dass die Erstellung solcher Labels ein arbeitsintensiver und teurer Prozess ist. Deshalb: nicht umlabeln, sondern migrieren!

Los geht's
In diesem Blog-Artikel möchte ich kurz den Prozess der Migration von Labeling mit Referenzen zu unserem ASMSpotter beschreiben, um Sentinel-2 anstelle von Planet Scope Bildern zu verwenden. In diesem Projekt versuchen wir, informelle Bergbaustandorte auf Regenwald-Satellitenbildern zu erkennen. Hier sehen Sie ein Beispiel für eine Minenmaske (gelb), die im Trainingsprozess verwendet wurde:

Unsere Überlegung: Obwohl wir während des Entwicklungsprozesses Zugang zu kommerziellen Satellitendaten hatten, könnte es möglich sein, ähnliche Ergebnisse mit frei verfügbaren Sentinel-2-Bildern zu erzielen. Wir hatten die Hypothese, dass in unserem Fall die zusätzlichen Spektralbänder die geringere räumliche Auflösung kompensieren könnten. Die Idee ist einfach: Satellitenbilder der neuen Quelle suchen, herunterladen und zuschneiden, um die Bilder der alten Quelle im Trainingsset zu ersetzen. Für diese Methode mussten die Satelliten natürlich zur gleichen Zeit in Betrieb sein.
Dabei ist zu beachten, dass dieses Transfer-Lernen nur für mehr oder weniger statische Objekte funktioniert, die von einem Satellitenbild zum anderen unverändert bleiben. Abhängig von den Revisit-Zeiten der beiden Quellen kann dies Stunden bis Tage oder sogar Wochen betragen. Dinge wie Gebäude, Straßen oder Vegetationsdecke würden sich also anbieten, während Fahrzeuge, Wolken und andere Wetterphänomene höchstwahrscheinlich nicht funktionieren werden. In unserem Fall detektieren wir kleine Tagebaue, die sich in der Größenordnung von Monaten verändern. Außerdem hat die neue Quelle idealerweise eine kurze Revisit-Zeit, um den zeitlichen Versatz gering zu halten.
Planet Scope |
Sentinel-2 |
|
Räumliche Auflösung |
3m |
10m |
Spektrale Auflösung |
4 Bänder |
13 Bänder |
Revisit-Zeit |
1 Tag |
5 Tage |
Das Wichtigste, was Sie jedoch prüfen sollten, bevor Sie über die Migration von Labels nachdenken, ist die Verfügbarkeit von geografischen und zeitlichen Informationen zur Aufnahme. Ein Problem vieler frei verfügbarer Datensätze ist, dass sie die Bilder und Labeling nur als fertige reine Bildkacheln (z.B. 256 x 256 jpegs) bereitstellen und nicht als geocodierte und zeitreferenzierte Satellitenbilder (wie das GeoTIFF-Format). Diese Kacheln sind für uns nicht wirklich nützlich, da wir kaum eine Chance haben, die passende Beobachtung für die neue Quelle zu erhalten. Wenn Sie also online nach Datensätzen suchen, suchen Sie nach .tif-Dateien. Auch wenn detaillierte Zeitinformationen fehlen, ist dieser Inria-Datensatz ein gutes Beispiel im gewünschten Format.
Migration, Schritt für Schritt
Nun werde ich demonstrieren, wie man ein Labeling aus einem Datensatz zu Sentinel-2 (S2) migriert. Da die Planet Scope-Bilder in unserem ASMSpotter-Projekt proprietär sind, werde ich stattdessen Daten aus dem erwähnten Inria-Datensatz verwenden. Wenn Sie also der Ausführung des Codes folgen wollen, laden Sie zuerst den Datensatz herunter. Die Schritte, die wir für die Migration durchführen müssen, sind wie folgt:
geokodierte Masken erstellen, falls nicht vorhanden (Labeling wird in der Bildsegmentierung als Maske bezeichnet)
neue Bilder beschaffen
bestimmen, welche Bilder für Masken benötigt werden
S2-Bilder herunterladen
S2-Bilder nach GeoTIFF konvertieren
S2-Bilder entsprechend dem Original beschneiden
Nachfolgend finden Sie kurze Codeschnipsel für jeden Schritt, den wir ausführen. Wir beginnen mit den Importen unserer benötigten Module:
from sentinelsat import SentinelAPI # to download the new images
import rasterio as rio # for all the GeoTIFF operations
from rasterio.features import dataset_features # to load the mask
from rasterio import mask # to crop the downloaded image
import imageio # to read png masks
from cv2 import resize # to resize the mask file
import geopandas as gpd # to handle geographic information in GeoTIFFs
import pandas as pd # to create dataframe with an image <> mask match
import os # for file operations
from zipfile import ZipFile # to unzip an archive
import numpy as np # basic array operations
from datetime import datetime # to extract recording date
from datetime import timedelta # to create a time difference for the searchDas sieht nach einer ziemlich langen Liste aus. Aber eigentlich ist es nur die API-Bibliothek zum Herunterladen der Bilder, einige Pakete zum Manipulieren der Bilder und einige Hilfsfunktionen.
Schritt 1: Geokodierte Masken erstellen
Nun zu Schritt 1: Der Beispieldatensatz enthält bereits geokodierte Labels, so dass wir diesen Schritt überspringen können. Da dies bei Ihrem Datensatz möglicherweise nicht der Fall ist, finden Sie hier ein kurzes Snippet, um sie zu konvertieren:
# 1. create geocoded masks if not available
original_image_tif = 'path'
mask_png = 'path'
with rio.open(original_image_tif, "r") as src:
# the important info is in the profile, so that is copied over
mask_profile = src.profile
# we just have to update some info like bands count
mask_profile.update({"dtype": "uint8", "count": 2, "nodata": 1})
# now we read the png
label = imageio.imread(mask_png)
# in case there is 'no data' info, we have to carry it over
no_data_mask = src.dataset_mask()
# now we just save the tif
with rio.open(mask_png + ".tif", "w", **mask_profile) as dst:
dst.write(label, 1)
dst.write(no_data_mask, 2)Sie fragen sich vielleicht, warum Sie die Geoinformationen überhaupt von den Bildern auf die Labelings übertragen müssen. Reicht es nicht aus, sie auf dem Originalmaterial zu haben und sie von dort aus direkt zu verwenden? Ja, da haben Sie recht. Es ist nicht nötig, die Masken zu geokodieren. Aber in dem Bemühen, den Datensatz leichter migrierbar und gemeinsam nutzbar zu machen, würde ich empfehlen, diesen kleinen zusätzlichen Schritt zu machen. Auf diese Weise ist es viel einfacher, in der Zukunft einen neuen Trainingsdatensatz für eine neue Datenquelle zu erstellen: man braucht nur die Labels, was kompakter und kleiner ist als alle Bild-Label-Paare.
Schritt 2: Neue Bilder beschaffen
Da wir die Geoinformationen bereits in den Beispiel-Labels haben, können wir direkt zu Schritt 2.1 übergehen, um nach unseren neuen Sentinel-2-Bildern zu suchen. Im Code verwende ich nur eine Kachel aus Wien:
# 2.1. determine which images are needed for masks
# Sentinel-2 credentials
USER = 'put_your_user_name_here'
PASSWORD = 'put_your_password_name_here'
# specify the path and name of the mask file
mask_dir = 'data/AerialImageDataset/train/gt/'
mask_name = 'vienna36.tif'
# extract date from filename
# (in our case its not present so we set it manually)
date = datetime.strptime('20210101', "%Y%m%d")
# get the area to look for from the geocoded mask file
with rio.open(mask_dir + mask_name) as src:
features = dataset_features(src, band=False)
bound_gdf = gpd.GeoDataFrame.from_features(features, crs=4326)
area = bound_gdf.geometry[0].simplify(5)
# initialize the Sentinel API
api = SentinelAPI(USER , PASSWORD,
'https://scihub.copernicus.eu/dhus')
# check the availability of products for the mask
products = api.query(str(area),
# specify the time window around the mask date
date=(date - timedelta(days=10),
date + timedelta(days=10)),
# there are different Sentinel 2 image types
producttype="S2MSI1C",
# the smallest possible cloud cover should be used
cloudcoverpercentage="[0 TO 1]")
# keep track of what image belongs to what mask
mask_s2_match = pd.DataFrame(columns=['mask_name', 'S2_name'])
for product_uuid in products:
product = products[product_uuid]
mask_s2_match = mask_s2_match.append({'mask_name': mask_name,
'S2_name': product['title'],
'S2_uuid': product_uuid,
'cloudcover': product['cloudcoverpercentage']},
ignore_index=True)
mask_s2_match.to_csv('mask_S2_match.csv')
Sie benötigen ein Login beim Copernicus Open Access Hub, um die Bilder herunterladen zu können, aber Sie können hier schnell eines erstellen. Zwei wichtige Einstellungen sind das Datumsfenster und der Prozentsatz der Wolkenbedeckung: Sie möchten beide so klein wie möglich halten, um große Unterschiede zwischen dem ursprünglichen und dem neuen Bild zu vermeiden, die die Genauigkeit Ihrer Labelings verringern würden. Am besten wären wolkenfreie und tagesgleiche Bilder, aber wahrscheinlich müssen Sie je nach Datenverfügbarkeit Kompromisse zwischen diesen beiden Werten eingehen. Für unsere Beispielanwendung der Erkennung von Gebäudegrundrissen könnten wir problemlos ein großes Zeitfenster verwenden, da sich bebaute Gebiete nur über Jahre hinweg verändern. Auf diese Weise haben wir gute Chancen, klare und wolkenfreie Bilder zu finden. Wenn die API die verfügbaren Produkte für die Maske prüft, werden die Ergebnisse in einer csv-Datei gespeichert, so dass wir die Beziehungen zwischen Label und Bild im Auge behalten können. Das ist recht praktisch, wenn wir große Trainingsmengen verarbeiten wollen.
Jetzt können wir mit dem Herunterladen der Produkte in Schritt 2.2 fortfahren:
# 2.2 downlaod S2 images
# load the match file and select a product
mask_s2_match = pd.read_csv('mask_S2_match.csv')
product = mask_s2_match.iloc[0]
# download the selected product
response = api.download(product['S2_uuid'], directory_path='data/')Zu beachten ist, dass Bildmaterial, das älter als 1 Jahr ist, in das Langzeitarchiv (LTA) der ESA verschoben wird. Wenn Sie ein solches Bild anfordern, dauert es bis zu 24 Stunden, bis es wieder zum Herunterladen zur Verfügung steht.
Nach dem Herunterladen müssen wir in unserem Schritt 2.3 das Zip-Archiv in ein GeoTIFF umwandeln. Sie müssen nicht tief in diesen Teil des Codes eintauchen, da es sich nur um die Konvertierung des Dateiformats handelt und eine Anpassung nicht notwendig ist:
# 2.3 convert S2 images to geoTIFF
product_name = product['S2_name']
product_path = 'data/' + product_name + '.zip'
# unzip the product
with ZipFile(product_path) as zip_ref:
zip_ref.extractall('')
# initialize
bands = {}
max_width = 0
max_height = 0
granule_dir = product_name + ".SAFE/GRANULE/"
jp2_path = granule_dir + os.listdir(granule_dir)[0] + "/IMG_DATA/"
# every file represents a band and has to be written to our GeoTIFF
for f in os.listdir(jp2_path):
if f[-7:-4] == "TCI": # skip this file as it is not a band
continue
band = rio.open(jp2_path + f, driver="JP2OpenJPEG")
max_width = max(max_width, band.width)
max_height = max(max_height, band.height)
bands[f[-6:-4]] = band
with rio.open(product_name + ".tif", "w",
driver="GTiff",
width=max_width,
height=max_width,
count=len(bands),
crs=bands["02"].crs,
transform=bands["02"].transform,
dtype=bands["02"].dtypes[0]) as dst:
dst.nodata = 0
band_names = ["01", "02", "03", "04", "05", "06", "07",
"08", "8A", "09", "10", "11", "12"]
for i, band_name in enumerate(band_names):
dst.write(bands[band_name].read(1), i + 1)
bands[band_name].close()Schritt 3: S2-Bild entsprechend dem Original beschneiden
Nun können wir endlich unser neues Trainingsbild erstellen, das dem alten Labeling entspricht. Hier ist der Code für Schritt 3:
# 3. crop S2 image corresponding to original
match = pd.read_csv('mask_S2_match.csv').iloc[0]
mask_name, s2_name = match['mask_name'][:-4], match['S2_name']
# open mask and extract the boundary information
with rio.open(mask_dir + mask_name + '.tif') as mask_src:
features = dataset_features(mask_src, band=False)
boundary_gdf = gpd.GeoDataFrame.from_features(features, crs=4326)
# open s2 image
with rio.open(s2_name + '.tif') as s2_src:
s2_crs = s2_src.crs # crs stands for coordinate reference system
# crop S2 image
cropped_s2, tfm = mask.mask(s2_src, boundary_gdf.to_crs(s2_crs).geometry,
crop=True)
# we have to update the new height and width information in the meta data
profile = s2_src.profile
profile.update(width=cropped_s2[0].shape[1], height=cropped_s2[0].shape[0])
# save the cropped s2 image
s2_cropped_path = open(s2_name + '_cropped.tif', 'w+b')
with rio.open(s2_cropped_path, "w", **profile) as dst:
dst.write(cropped_s2)Und das sollte es sein! Schauen wir uns unsere Ergebnisse an:

Wenn wir das linke und das mittlere Bild vergleichen, können wir sehen, dass wir den richtigen Ausschnitt gefunden haben. Auch die Ground Truth in Blau stimmt gut mit den Gebäuden im grauen Sentinel-2-Bild rechts überein. Die schwarzen Bereiche an den Bildrändern sind tatsächlich korrekt ausgeschwärzt. Die rote Linie stellt den Bereich des Originalbildes dar und ist, wie wir sehen können, nicht zu 100% geschwärzt. Das führt dazu, dass das beschnittene Sentinel-Bild einen etwas größeren Bereich abdeckt, als das Label Daten liefert, daher decken wir diese Pixel im Bild ab. Ein kleiner Hinweis an dieser Stelle: der Code fügt nicht mehrere Sentinel-2-Szenen zusammen; falls Ihr Label also mehrere Sentinel-2-Kacheln abdeckt, müssen Sie es anpassen.
Jetzt können Sie den ganzen Code einfach in 'for-Schleifen' verpacken, um alle alten Trainings-Labels zu verarbeiten und schon haben Sie Ihren neuen Trainingsdatensatz.
Fazit
Wir haben unser Ziel erreicht, mit wenig Code und ohne aufwändiges Labeling ein Trainingsset für unseren Sensortyp zu erstellen. Es gibt jedoch einige Dinge zu beachten: Die Qualität des Trainingssets wird höchstwahrscheinlich in gewissem Maße verschlechtert werden. Verdeckungen, die nur entweder im Originalbild oder im neuen Bild vorhanden sind, werden im ersten Fall falsch-negative und im zweiten Fall falsch-positive Ergebnisse liefern. Solche Verdeckungen können z. B. durch Wolken in visuellen Bildern oder Baukräne in SAR (Radar)-Daten erzeugt werden. Daher ist es wichtig, den neuen Datensatz nach der Migration zu inspizieren und den Erfolg des Prozesses zu überprüfen.
Übrigens, als wir im ASMSpotter-Projekt die Trainingsdaten von Planet Scope auf Sentinel-2 umgestellt haben, waren wir zunächst etwas besorgt über einige falsche Labelings, die durch Wolkenverdeckungsunterschiede und Ausdehnung der Minen verursacht wurden. Aber mit einem Zeitfenster von +/- 10 Tagen um das Aufnahmedatum von Planet Scope und einer maximal erlaubten Wolkenbedeckung von 3% für die neuen Bilder fanden wir genügend Daten, um im neuen Trainingsprozess fast den gleichen f1-Score zu erreichen.
Kontakt
Wenn Sie mit uns über dieses Thema sprechen möchten, kontaktieren Sie uns gerne und wir melden uns im Anschluss für ein unverbindliches Erstgespräch.