
Die besten Bildannotations-Tools für Computer Vision
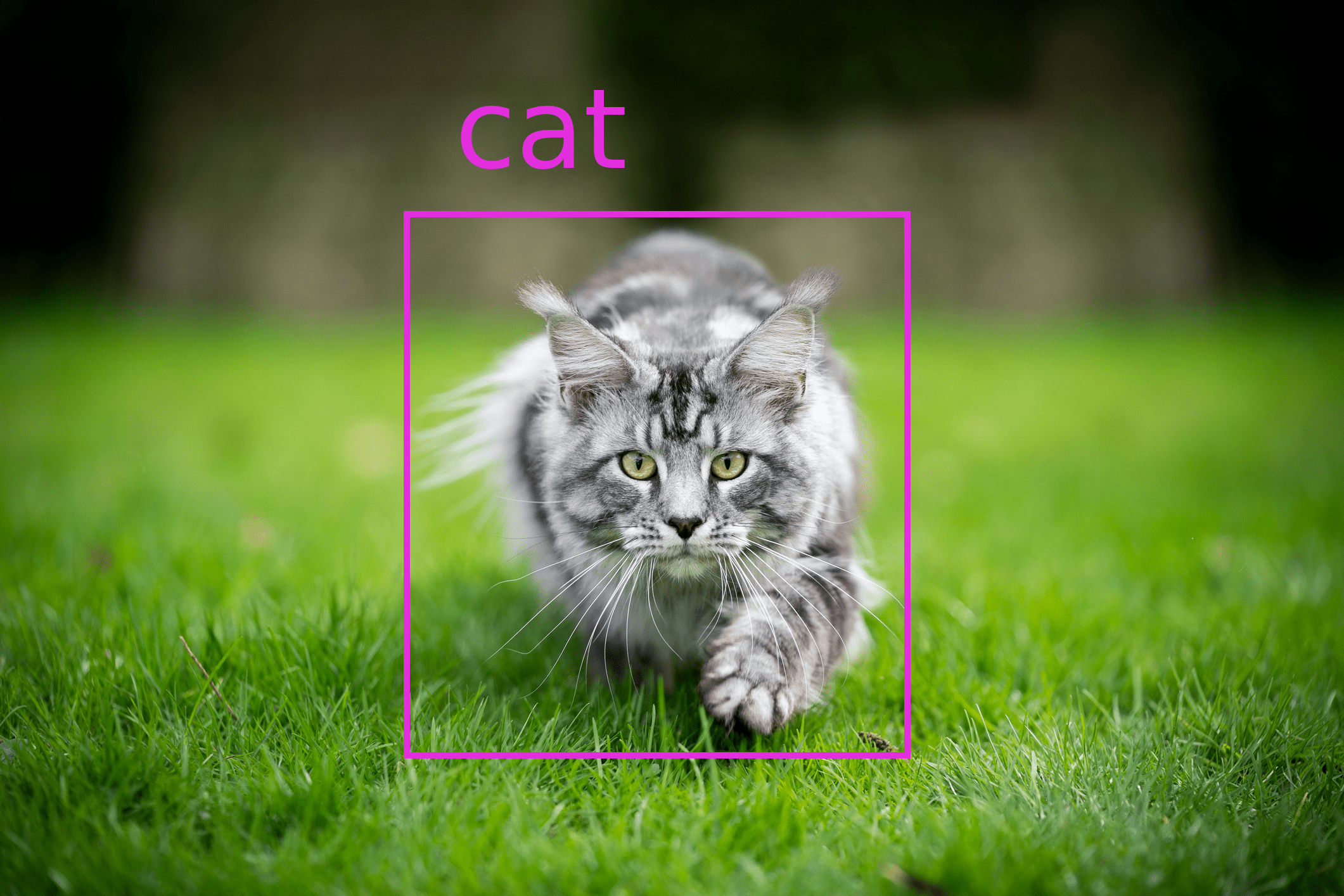
Die Erstellung eines qualitativ hochwertigen Datensatzes ist ein entscheidender Teil einer jeden Machine-Learning-Lösung. In der Praxis dauert dies oft länger als das eigentliche Training und die Optimierung der Hyperparameter. Daher ist die Wahl eines geeigneten Tools für das Labeling entscheidend. Hier werden wir uns einige der besten Bildannotations-Tools für Computer-Vision-Aufgaben genauer ansehen:
Wir werden die Werkzeuge installieren und konfigurieren und ihre Fähigkeiten veranschaulichen, indem wir sie auf die Annotation echter Bilder für eine Objekterkennungsaufgabe anwenden. Wir werden uns jedes der oben genannten Tools einzeln ansehen.
Unser Sammlung von Computer Vision Inhalten zeigt ebenfalls deutlich, wie zentral die Nutzung solcher Labelingtools für uns als Machine-Learning-Spezialisten ist.
Der Datensatz
Wir werden Bilder aus dem COCO-Datensatz labeln. Common Objects in Context (COCO) ist ein bekannter Datensatz zur Verbesserung des Verständnisses komplexer Alltagsszenen, die gewöhnliche Objekte (z. B. Stuhl, Flasche oder Schüssel) enthalten. Der Datensatz wurde entwickelt, um die Computer-Vision-Forschung auf dem Gebiet der Objekterkennung, Segmentierung und Annotation zu stimulieren. Der COCO-Datensatz besteht aus 330K Bildern und 80 Objektklassen.
Wir werden jedoch nur 26 Bilder mit 2 Klassen (Katze und Hund) verwenden, die für unsere Studie ausreichend wären, da wir uns heute nicht auf das Training von Modellen konzentrieren und unser Ziel darin besteht, die Annotations-Tools zu testen.
labelme
Was Sie damit machen können
labelme ist ein auf Python basierendes Open-Source-Werkzeug zur polygonalen Annotation von Bildern, das für die manuelle Annotation von Bildern zur Objekterkennung, Segmentierung und Klassifizierung verwendet werden kann. Es ist ein Offline-Fork des webbasierten LabelMe, das kürzlich die Option zur Registrierung für neue Benutzer abgeschaltet hat. Daher betrachten wir in diesem Beitrag nur labelme (Kleinbuchstaben).

Das Tool ist eine schlanke grafische Anwendung mit einer intuitiven Benutzeroberfläche. Mit labelme können Sie Polygone, Rechtecke, Kreise, Linien, Punkte oder Linienstreifen erstellen.
Generell ist es oft praktisch, die Labels zur weiteren Verwendung in bekannte Formate wie COCO, YOLO oder PASCAL VOL exportieren zu können. In labelme können die Labels jedoch nur als JSON-Dateien direkt aus der App heraus gespeichert werden. Wenn Sie andere Formate verwenden möchten, können Sie ein Python-Skript aus dem labelme-Repository verwenden, um die Annotationen in PASCAL VOL zu konvertieren.
Nichtsdestotrotz ist es eine recht zuverlässige App mit einer einfachen Funktionalität für die manuelle Bildannotation und für eine breite Palette von Computer-Vision-Aufgaben.
Installation und Konfiguration
labelme ist eine plattformübergreifende Anwendung, die auf mehreren Systemen, wie Windows, Ubuntu oder macOS, funktionieren kann. Die Installation selbst ist ziemlich einfach und hier gut beschrieben. Auf macOS müssen Sie zum Beispiel die folgenden Befehle im Terminal ausführen:
Abhängigkeiten installieren:
brew install pyqtlabelme installieren:
pip install labelmelabelme ausführen:
labelme
Nutzung
Die allgemeine Vorgehensweise:
Wählen Sie das Verzeichnis
Open Dirmit Ihren Bildern.Gehen Sie zu
File->Change Output Dirund wählen Sie den Ausgabeordner.(Optional) Aktivieren Sie das automatische Speichern, damit Sie es nicht nach dem Annotieren jedes Bildes manuell machen müssen:
File->Save Automatically.Gehen Sie zu
Editund wählen Sie die entsprechende Option (z. B.Create Rectangle).Benennen Sie ein Objekt.
Gehen Sie zu
Bearbeitenund wählen SieEdit Polygons.
Tastenkombinationen:
Rechteck erzeugen: ⌘ + E
Polygone bearbeiten: ⌘ + J
Nächstes Bild: D
Vorheriges Bild: A
labelImg
Was Sie damit machen können
labelImg ist ein weit verbreitetes Open-Source-Werkzeug für grafische Annotationen. Es ist nur für die Lokalisierung oder Erkennung von Objekten geeignet und kann nur rechteckige Boxen um die betrachteten Objekte erstellen.

Trotz dieser Einschränkung möchten wir dieses Tool vorstellen, da die Anwendung nur auf die Erstellung von Bounding Boxes ausgerichtet ist, was das Tool so weit wie möglich vereinfacht. Für diese Aufgabe verfügt labelImg über alle notwendigen Funktionen und komfortable Tastaturkürzel.
Ein weiterer Vorteil ist, dass Sie Annotationen in 3 gängigen Annotationsformaten speichern/laden können: PASCAL VOC, YOLO und CreateML.
Installation und Konfiguration
Die Installation ist hier gut beschrieben. Beachten Sie auch, dass labelImg eine plattformübergreifende Anwendung ist. Für MacOS sind z. B. die folgenden Aktionen auf der Kommandozeile erforderlich:
Installieren Sie die Abhängigkeiten: Zuerst
brew install qt, dannbrew install libxml2Wählen Sie den Speicherort des zu installierenden Ordners.
Wenn Sie in dem Ordner sind, führen Sie Folgendes aus:
git clone https://github.com/tzutalin/labelImg.git,cd labelImgund dann makeqt5py3Führen Sie labelImg aus:
python3 labelImg.py
Die Entwickler empfehlen dringend, Python 3 oder höher und PyQt5 zu verwenden.
Nutzung
Die allgemeine Vorgehensweise:
Definieren Sie die Liste der Klassen, die verwendet werden sollen, in
data/predefined_classes.txt.Wählen Sie das Verzeichnis
Open Dirmit Ihren Bildern.Wählen Sie den Ausgabeordner
Change Save Dir.Wählen Sie das Anmerkungsformat.
Abkürzungen:
Rechteck erstellen: W
Nächstes Bild: D
Vorheriges Bild: A
CVAT
Was Sie damit machen können
CVAT ist ein Open-Source-Annotationstool für Bilder und Videos für Aufgaben wie Objekterkennung, Segmentierung und Klassifizierung.

Um dieses Tool zu verwenden, müssen Sie die Anwendung nicht auf Ihrem Computer installieren. Es ist möglich, die Web-Version dieses Tools online zu nutzen. Sie können gemeinsam als Team an der Annotation von Bildern arbeiten und die Arbeit zwischen den Benutzern aufteilen.
Es gibt auch eine großartige Option, die es Ihnen ermöglicht, vortrainierte Modelle zu verwenden, um Ihre Daten automatisch zu labeln. Dies vereinfacht den Prozess für die gängigsten Klassen (z. B. die in COCO enthaltenen), wenn Sie vorhandene verfügbare Modelle im CVAT-Dashboard verwenden. Alternativ können Sie auch Ihre eigenen vortrainierten Modelle nutzen.
CVAT hat von den bisher betrachteten Tools den größten Funktionsumfang. Insbesondere erlaubt es Ihnen, Labels in etwa 15 verschiedenen Formaten zu speichern. Die vollständige Liste der Formate finden Sie hier.
Installation und Konfiguration
Eine umfassende Anleitung, wie Sie Ihr System einrichten, Docker-Container ausführen und mit dem Programm arbeiten können, finden Sie hier.
Wir werden die Anleitung nicht neu schreiben, aber beachten Sie, dass Sie die Online-Version zum Testen von CVAT verwenden können. Wir werden diese Version verwenden, um zu demonstrieren, wie das Labeling für die Aufgabe der Objekterkennung funktioniert.
Nutzung
Im Video haben wir gezeigt, wie man ein Faster R-CNN für die Aufgabe der Objekterkennung verwendet, um die Annotation zu automatisieren. Aber der allgemeine Ansatz ist wie folgt:
Um CVAT zu verwenden, müssen Sie sich registrieren und anmelden.
Navigieren Sie zur Registerkarte
Tasksund legen Sie eine neue Aufgabe an.Füllen Sie das Formular für diese Aufgabe aus, fügen Sie Labels und Bilder hinzu und senden Sie es ab.
Öffnen Sie die soeben erstellte Aufgabe.
Beginnen Sie mit dem Labeln, indem Sie die Rechteckform und die Objektklasse auswählen und dies für alle Objekte im Bild wiederholen.
Speichern Sie den Fortschritt, nachdem Sie mit dem ersten Bild fertig sind, und navigieren Sie zum nächsten Bild.
Wenn Sie mit allen Bildern fertig sind, navigieren Sie zurück zur Registerkarte
Tasksund geben die Annotationen im gewünschten Format aus.
Abkürzungen:
Rechteck erstellen: Umschalt + N, N
Speichern des Verlaufs: Strg + S
Nächstes Bild: F
Vorheriges Bild: D
hasty.ai

Was Sie damit machen können
Im Gegensatz zu allen oben genannten Tools ist hasty.ai kein kostenloser Open-Source-Dienst, aber aufgrund der sogenannten KI-Assistenten für die Objekterkennung und Segmentierung sehr komfortabel für das Labeling von Daten. Mit den automatischen Assistenten können Sie den Annotationsprozess deutlich beschleunigen, da während der Annotation ein Assistentenmodell trainiert wird. Mit anderen Worten: Je mehr Bilder gelabelt werden, desto genauer arbeitet der Assistent. Ein Beispiel, wie das funktioniert, sehen wir uns weiter unten an.
Eine kürzlich hinzugefügte Funktion ist das Atom-Tool, bei dem Sie einfach in die Mitte eines Objekts klicken und der KI-Assistent es automatisch annotiert. Es gibt auch eine Beta-Version des Model Playground, mit dem Sie verschiedene Architekturen und Parameter ausprobieren können, um die Leistung des KI-Assistentenmodells zu verbessern.
Sie können diesen Dienst auch kostenlos ausprobieren. Die Testversion bietet 3000 Credits, was ausreicht, um automatisch vorgeschlagene Labels von etwa 3000 Objekten für eine Objekterkennungsaufgabe zu generieren.
hasty.ai erlaubt es Ihnen, Daten in den Formaten COCO oder Pascal VOC zu exportieren. Sie können auch als Team an einem Projekt arbeiten und in den Projekteinstellungen Rollen zuweisen.
Wenn Ihr Guthaben aufgebraucht ist, können Sie hasty.ai weiterhin kostenlos nutzen, aber die Annotation erfolgt dann komplett manuell. In diesem Fall ist es besser, die oben beschriebenen kostenlosen Tools in Betracht zu ziehen.
Konfiguration
Um das Tool zu verwenden, müssen Sie sich auf hasty.ai registrieren.
Melden Sie sich bei Ihrem Konto an.
Klicken Sie auf
create a new project.Füllen Sie das Formular mit dem Namen und der Beschreibung aus und navigieren Sie zu den Projekteinstellungen, wo Sie die in Frage kommenden Klassen definieren und Daten für dieses Projekt hinzufügen können.
Außerdem können Sie andere Benutzer hinzufügen, um gemeinsam an dem Projekt zu arbeiten. Die Credits werden vom Konto des Benutzers verwendet, der das Projekt freigegeben hat.
Nutzung
Sie können das Tool direkt nach der Konfiguration in einem manuellen Modus verwenden. Um jedoch die Vorteile des KI-Assistenten zu nutzen, müssen Sie 10 Bilder manuell labeln und ihren Status von new auf review oder done ändern. Danach kann der Assistent genutzt werden.
Nach Abschluss des Labelingvorgangs können Sie die Anmerkungen in verschiedenen Formaten exportieren, z. B. COCO oder Pascal VOC.
Tastaturkürzel:
Rechteck erstellen: R
Rechteck bearbeiten: M
Assistent für Objekterkennung verwenden: J
Atom Tool: C
Labelbox
Was Sie damit machen können
Labelbox ist ein leistungsfähiges Tool zur Annotation von Bildern für die Objekterkennung, Segmentierung und Klassifizierung. Außerdem können Textdaten für Aufgaben der natürlichen Sprachverarbeitung annotiert werden.

Das Tool ist in der Regel kostenpflichtig, aber mit der kostenlosen Testversion können Sie in einem kleinen Team von maximal fünf Personen 10.000 Annotationen vornehmen.
Labelbox ist webbasiert und verfügt über eine übersichtlich gestaltete Projektübersichtsseite mit hilfreichen Statistiken, z. B. über die durchschnittlich pro Label aufgewendete Zeit. Auch die Annotationsseite ist sehr intuitiv und einfach zu bedienen.
Anmerkungen können nur im Webbrowser als JSON-Dateien exportiert werden. Darüber hinaus hat Labelbox ein Python-SDK für den Zugriff auf die API entwickelt, mit dem Sie die Labels direkt über ein Python-Skript exportieren können.
Konfiguration
Der allgemeine Ansatz:
Um Labelbox zu nutzen, müssen Sie sich registrieren und anmelden.
Auf der Projektseite klicken Sie auf "Neues Projekt".
Geben Sie Ihren Projektnamen und optional eine Beschreibung ein.
Nun können Sie Daten zu Ihrem Projekt hinzufügen. Entweder Sie wählen einen bestehenden Datensatz aus oder Sie erstellen einen neuen. Sie können ein Dataset auch über das Python SDK erstellen.
Anschließend müssen Sie den Editor konfigurieren. Sie können mehrere Objekte für Segmentierungsaufgaben definieren und festlegen, wie Sie diese markieren (z. B. mit einem Polygon, einer Polylinie oder einer Bounding Box) oder Klassifizierungen für globale Auswertungen der Daten.
Im letzten Schritt können Sie einige Einstellungen zur Qualitätssicherung vornehmen.
Fazit
Wir haben uns mit fünf verschiedenen Annotationstools beschäftigt und die Vor- und Nachteile der einzelnen Tools betrachtet:
labelme kann für verschiedene Computer-Vision-Aufgaben verwendet werden, allerdings handelt es sich um eine rein manuelle Annotation. Das Tool kann jedoch sehr schnell installiert und konfiguriert werden. Das Tool eignet sich möglicherweise für diejenigen, die einen kleinen Datensatz annotieren wollen.
labelImg eignet sich für Aufgaben, bei denen nur ein Benutzer mit der Annotation für eine Objekterkennungsaufgabe beschäftigt sein wird. Es ist auch sehr schnell zu installieren und zu benutzen. Außerdem unterstützt es verschiedene bekannte Annotationsformate.
CVAT ist für diejenigen geeignet, die in einem Team arbeiten und ihr Modell zur Automatisierung des Labelingprozesses nutzen wollen.
hasty.ai ist kein kostenloses Tool, hat aber den Vorteil, dass es über eingebaute Assistenten verfügt, die es ermöglichen, nach der manuellen Annotation von 10 Bildern im Datensatz vorgeschlagene Labels zu erzeugen, was das Labeling einfacher und schneller macht.
Labelbox ist zwar auch nicht kostenlos, aber einfach zu bedienen, vielseitig und mit nützlichen Zusatzfunktionen ausgestattet.
Nachdem Sie nun eine Übersicht über Bildannotationstools erhalten haben, empfehlen wir Ihnen sich weiterführend unsere Case-Studies zu Computer-Vision-Projekten durchzulesen, um Einblicke in die Entwicklung solcher Projekte zu erhalten.
Sollten Sie Interesse an einem ersten, unverbindlichen Gespräch mit einem Projekt Manager oder Machine-Learning-Scientist haben, schauen Sie sich gerne unsere kostenlose Angebote für Machine-Learning-Gespräche an.
Kontakt
Wenn Sie mit uns über dieses Thema sprechen möchten, kontaktieren Sie uns gerne und wir melden uns im Anschluss für ein unverbindliches Erstgespräch.