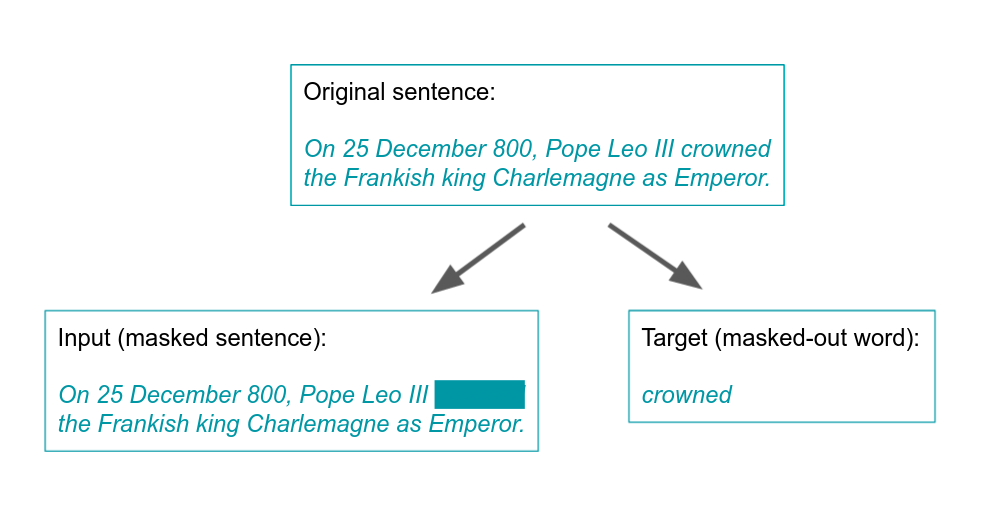
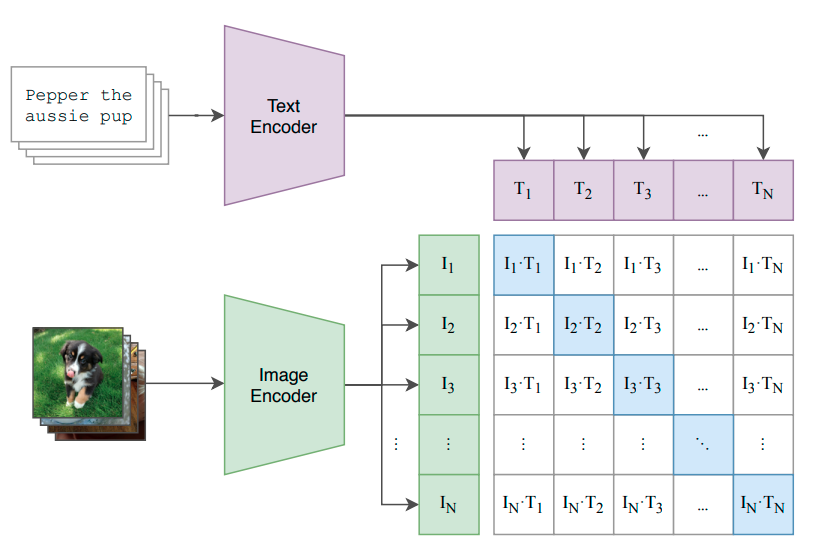
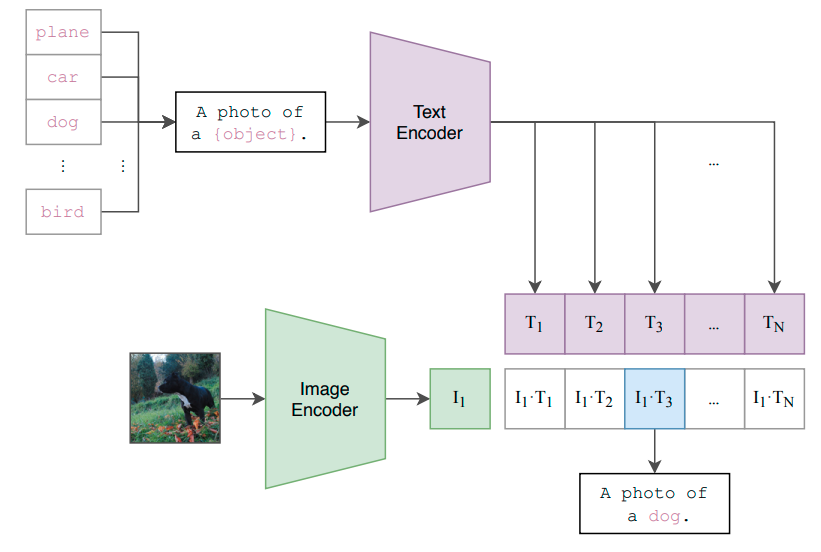
Trotz der enormen Fortschritte, die im letzten Jahrzehnt auf dem Gebiet des maschinellen und tiefen Lernens erzielt wurden, bleibt ein Kritikpunkt bestehen: Selbst die leistungsstärksten State-of-the-Art-Modelle lernen immer noch außerordentlich ineffizient.
Nehmen wir das maschinelle Sehen, insbesondere die Bildklassifikation: Wo ein Mensch ein Beispielbild oder vielleicht eine Handvoll braucht, um ein visuelles Konzept zu lernen und es in neuen Instanzen zu erkennen, brauchen ML-Modelle oft Tausende, um eine dem Menschen ähnliche Leistung zu erreichen.
Das Problem ist nicht, dass es nicht genügend Daten gäbe, mit denen man die ML-Modelle füttern könnte, sondern dass wir sie für die meisten Trainingsaufgaben erst labeln müssen - und das ist in der Regel sehr aufwändig.
Aber selbst wenn sich eine Menge manueller Labeler die Mühe macht, einen riesigen annotierten Datensatz wie ImageNet (14 Millionen gelabelte Bilder) zu erstellen, und wir unsere besten Modelle darauf trainieren und tatsächlich eine Genauigkeit auf menschlichem Niveau erreichen oder sie sogar übertreffen - dann hat sich gezeigt, dass die Modelle immer noch sehr schlecht auf Datensätzen abschneiden, die aus leicht unterschiedlichen Verteilungen stammen (z. B. erkennen Bildklassifizierungsmodelle, die auf Fotos trainiert wurden, oft keine Skizzen von Objekten) und können leicht durch "adversarial examples" getäuscht werden.

.jpg)