
A practical introduction to the Model-Context-Protocol (MCP)
.png)
As LLMs and AI agents grow increasingly powerful, they face a critical limitation: accessing up-to-date information and specialized tools in a consistent, standardized way. The Model-Context-Protocol (MCP), developed by Anthropic, addresses this challenge by creating a unified interface between AI models and external resources. This standardization eliminates the fragmentation of custom integrations, allowing developers to build tools once and connect them to any MCP-compatible AI system.
In this blog post, we'll explore MCP's technical foundations and demonstrate it by building a custom Wikipedia server that gives LLM agents access to Wikipedia as a knowledge source.
Technical overview
The Model-Context-Protocol (MCP) is a standardized communication interface designed to enhance interoperability between AI language models and external servers. It establishes a structured way for language models to interact with resources, tools, and capabilities provided by external systems.
MCP operates on a client-server model where:
Clients: Typically AI models or applications embedding them
Servers: External systems providing additional capabilities to the models
MCP servers can offer three primary types of capabilities to clients:
Resources: Provide context and data that can be accessed by either the user or the AI model
Prompts: Deliver templated messages and structured workflows for suggested user interactions
Tools: Expose functions that AI models can call to perform specific tasks
Clients can optionally offer to fulfill LLM Sampling requests from the server. This allows the server to leverage LLM capabilities and agentic workflows without having a direct LLM dependency.
MCP servers are usually deployed in one of two ways:
Local: Here, the client is responsible for starting the server and communicates with it through Stdio. This the usual setup for desktop apps like Claude Desktop or Cursor.
Remote: The server is hosted separately and the client communicates with it over the network. The newest version of the spec prescribes Streamable HTTP as the transport. An older version of the spec prescribed SSE (Server-sent-events) as transport instead. At the time of writing, most SDKs still use SSE and do not support Streamable HTTP yet.
Building a Wikipedia MCP server
After this dry overview, let's actually implement an MCP server and see what we can do with this.
We will build a server which gives our LLMs access to wikipedia as a knowledge source.
Let's use uv to bootstrap our project and manage its dependencies:
uv init --package example-mcp-server
uv add fastmcp pydantic requests wikipedia-api "smolagents[mcp,openai]"Retrieving data from wikipedia is straightforward thanks to the wikimedia api and the "wikipedia-api" Python package:
# ./src/example_mcp_server/wikipedia_client.py
import wikipediaapi
import requests
from pydantic import BaseModel, Field
class WikipediaPage(BaseModel):
"""Represents a Wikipedia page with its metadata and content."""
title: str = Field(description="The title of the page")
url: str = Field(description="The canonical URL of the page")
summary: str = Field(description="A summary of the page content")
sections: list[tuple[str, str]] = Field(
description="List of section numbers and titles in the page"
)
content: str | None = Field(
default=None,
description="Full text content of the page, if requested"
)
class WikipediaPageSection(BaseModel):
"""Represents a specific section of a Wikipedia page."""
page_title: str = Field(description="The title of the parent page")
url: str = Field(description="The URL of the parent page")
section_title: str = Field(description="The title of the section")
content: str = Field(description="The text content of the section")
class WikipediaSearchResult(BaseModel):
"""Represents a single result from a Wikipedia search query."""
title: str = Field(description="The title of the page")
wordcount: int = Field(description="The word count of the page")
snippet: str = Field(description="Snippet showing the match context")
# User agent should respect Wikimedia policy:
# https://foundation.wikimedia.org/wiki/Policy:Wikimedia_Foundation_User-Agent_Policy
USER_AGENT = "Wikipedia MCP server example (https://dida.do/)"
class WikipediaClient:
"""Client for interacting with Wikipedia API."""
def __init__(self) -> None:
self._client = wikipediaapi.Wikipedia(
user_agent=USER_AGENT,
language="en",
extract_format=wikipediaapi.ExtractFormat.WIKI,
)
self._api_url = "https://en.wikipedia.org/w/api.php"
def get_page(
self, page_title: str, include_full_text: bool = False
) -> WikipediaPage | None:
"""Retrieve a Wikipedia page by its title.
Args:
page_title: The title of the Wikipedia page to retrieve
include_full_text: Whether to include full page content in result
Returns:
WikipediaPage object if the page exists, None otherwise
"""
page_data = self._client.page(page_title)
if not page_data.exists():
return None
sections = [
(l, section.title)
for l, section in _get_subsections(page_data.sections)
]
return WikipediaPage(
title=page_data.title,
summary=page_data.summary,
url=page_data.canonicalurl,
sections=sections,
content=page_data.text if include_full_text else None,
)
def get_page_section(
self, page_title: str, section_title: str
) -> WikipediaPageSection | None:
"""Retrieve a specific section from a Wikipedia page.
Args:
page_title: The title of the Wikipedia page
section_title: The title of the section to retrieve
Returns:
WikipediaPageSection if the page and section exist, None otherwise
"""
page_data = self._client.page(page_title)
if not page_data.exists():
return None
sections = page_data.sections_by_title(section_title)
if not sections:
return None
section = sections[0]
return WikipediaPageSection(
page_title=page_title,
url=page_data.canonicalurl,
section_title=section.title,
content=section.text,
)
def search(
self, query: str, num_results: int = 20, offset: int = 0
) -> list[WikipediaSearchResult]:
"""Search Wikipedia for pages matching the given query.
Args:
query: The search query string
num_results: Maximum number of results to return
offset: Number of results to skip for pagination
Returns:
List of WikipediaSearchResult objects representing search matches
"""
response = requests.get(
self._api_url,
params={ # type: ignore[arg-type]
"action": "query",
"format": "json",
"list": "search",
"utf8": 1,
"srsearch": query,
"srlimit": num_results,
"sroffset": offset,
},
)
response.raise_for_status()
results = response.json()["query"]["search"]
return [WikipediaSearchResult(**result) for result in results]
def _get_subsections(
sections: list[wikipediaapi.WikipediaPageSection],
) -> list[tuple[str, wikipediaapi.WikipediaPageSection]]:
result = []
for n, section in enumerate(sections, start=1):
result += [(str(n), section)]
subsections = _get_subsections(section.sections)
result += [
(f"{n}.{i}", subsection) for i, subsection in subsections
]
return result
Now let's wrap this in an MCP server. By now, there are many MCP SDKs for various languages. For python, we could use the reference SDK from Anthropic or the more featureful FastMCP package which builds on top of it. We choose the latter due to its native support for pydantic models.
Defining the server essentially boils down to wrapping our tools in an appropriate decorator:
# ./src/example_mcp_server/server.py
from example_mcp_server.wikipedia_client import (
WikipediaClient,
WikipediaPage,
WikipediaPageSection,
WikipediaSearchResult,
)
from fastmcp import FastMCP
from pydantic import Field
mcp: FastMCP = FastMCP("Wikipedia MCP")
wikipedia_client = WikipediaClient()
@mcp.tool()
def get_wikipedia_page(
page_title: str = Field(
description="The title of the Wikipedia page to retrieve"
),
include_full_text: bool = Field(
default=False,
description="Whether to include the full text content of the page",
),
) -> WikipediaPage:
"""Retrieve a Wikipedia page by its title.
Raises ValueError if page is not found.
"""
page_title = page_title.strip()
page = wikipedia_client.get_page(
page_title, include_full_text=include_full_text
)
if page is None:
raise ValueError(f"Page '{page_title}' not found.")
return page
@mcp.tool()
def get_wikipedia_section(
page_title: str = Field(
description="The title of the Wikipedia page containing the section"
),
section_title: str = Field(
description="The title of the section to retrieve"
),
) -> WikipediaPageSection:
"""Retrieve a specific section from a Wikipedia page.
Raises ValueError if page is not found or section is not found in page.
"""
page_title = page_title.strip()
section_title = section_title.strip()
section = wikipedia_client.get_page_section(
page_title=page_title, section_title=section_title
)
if section is None:
raise ValueError(
f"Section '{section_title}' not found for page '{page_title}'."
)
return section
@mcp.tool()
def search_wikipedia(
query: str = Field(description="The search query for Wikipedia"),
num_results: int = Field(
default=20,
description="The maximum number of search results to return",
),
offset: int = Field(
default=0,
description="The offset to start retrieving results from",
),
) -> list[WikipediaSearchResult]:
"""Search Wikipedia for pages matching the query."""
return wikipedia_client.search(
query=query, num_results=num_results, offset=offset
)
if __name__ == "__main__":
mcp.run()
Note the design choices we made when structuring the data returned from the Wikipedia API:
We don't include full content by default to prevent overwhelming the LLM with excessive text
We provide options to retrieve specific sections when only certain information is needed
We implement pagination for search results so clients can request more results incrementally
This fine-grained control over the results makes our MCP server more flexible for clients, allowing them to request the information they need in manageable chunks rather than processing large blocks of text all at once.
Let's also add an example prompt to give some guidance on how to use the server. Suitable MCP clients will present this prompt template with autocomplete as a suggestion to the user.
@mcp.prompt()
def answer_question(question: str = Field(description="The question to answer")) -> str:
"""Answer a question using Wikipedia."""
answer_prompt = f"""
You are a helpful AI assistant that answers questions based on Wikipedia information.
Question: {question}
Use the available Wikipedia tools to search for relevant information
and provide a comprehensive answer.
Follow these steps:
1. Search Wikipedia for relevant pages using search_wikipedia()
2. Retrieve full page content or specific sections using
get_wikipedia_page() or get_wikipedia_section()
3. Analyze the information and compose a clear, accurate answer
4. If the information is not available or unclear, acknowledge the limitations
5. Cite your Wikipedia sources in the answer
Your answer should be informative, well-structured, and directly address the question.
"""
return answer_prompt
We can now start our mcp server:
# For stdio transport
uv run --with-editable . mcp run --transport stdio src/example_mcp_server/server.py
# For sse transport
# uv run --with-editable . mcp run --transport sse src/example_mcp_server/server.py
To check that everything works correctly, the mcp sdk also ships with a debugging frontend called "MCP Inspector". We can start it as follows:
mcp dev -e . src/example_mcp_server/server.py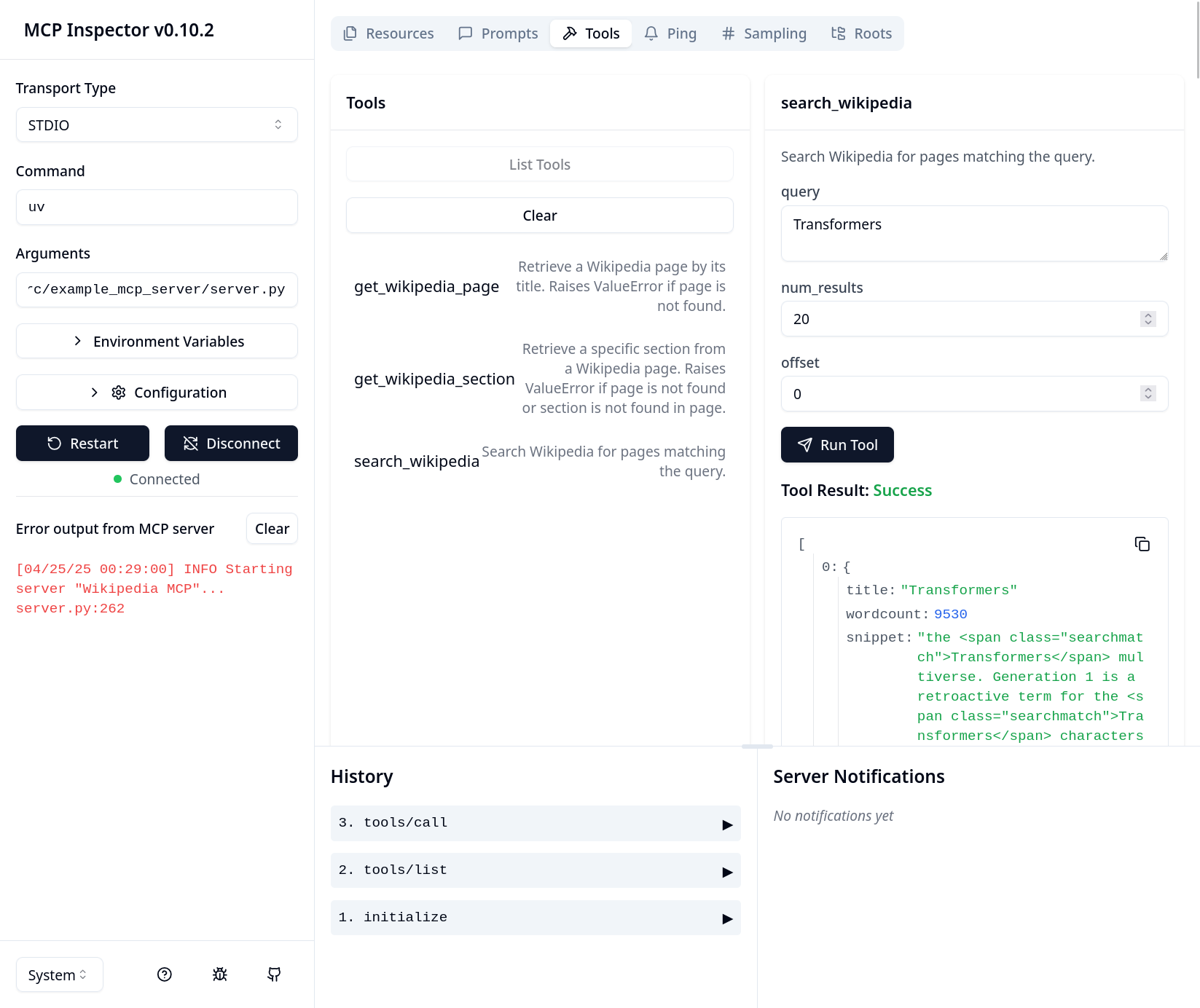
Using our MCP server with an agent
Let's integrate our newly built MCP server into an actual agentic workflow. We will use the smolagents library from Huggingface for this.
# ./src/example_mcp_server/agent.py
import os
import sys
from pathlib import Path
from mcp import StdioServerParameters
from smolagents import OpenAIServerModel, ToolCollection, ToolCallingAgent
PROMP_TEMPLATE = """
You are a helpful AI assistant that answers questions based on Wikipedia information.
Always cite the source of the information you provide. Add a reference section at the end of your answer.
{question}
"""
def _build_server_args() -> StdioServerParameters:
server_path = (
Path(__file__).parents[2]
/ "src"
/ "example_mcp_server"
/ "server.py"
)
server_parameters = StdioServerParameters(
command="mcp", args=["run", str(server_path.absolute())]
)
return server_parameters
def _ask_agent(model: OpenAIServerModel, question: str) -> None:
server_parameters = _build_server_args()
with ToolCollection.from_mcp(
server_parameters=server_parameters, trust_remote_code=True
) as tool_collection:
agent = ToolCallingAgent(tools=[*tool_collection.tools], model=model)
agent.run(PROMP_TEMPLATE.format(question=question))
if __name__ == "__main__":
openai_api_key = os.environ.get("OPENAI_API_KEY")
if not openai_api_key:
print("Error: OPENAI_API_KEY environment variable is required")
sys.exit(1)
model = OpenAIServerModel(model_id="gpt-4o")
print("Wikipedia Assistant")
print("Type 'exit', 'quit', or 'q' to end the program")
while True:
print("\n" + "-" * 50)
question = input("Enter your question: ").strip()
if question.lower() in ["exit", "quit", "q"]:
print("Exiting program...")
break
if not question:
print("Please enter a valid question.")
continue
print("-" * 50)
_ask_agent(model, question)
print("-" * 50)
Let's see how well it works:
> python src/example_mcp_server/agent.py
Wikipedia Assistant
Type 'exit', 'quit', or 'q' to end the program
--------------------------------------------------
Enter your question: What are the causes of the french revolution?
INFO Starting server "Wikipedia MCP"...
New run
You are a helpful AI assistant that answers questions based on Wikipedia information. Always cite the source of the information you provide. Add a reference section at the end of your answer. What are the causes of the french revolution?
OpenAIServerModel - gpt-4o
Step 1
Calling tool: 'get_wikipedia_section' with arguments:
{'page_title': 'Causes of the French Revolution', 'section_title': 'Main causes'}
Observations: Error executing tool get_wikipedia_section: Section 'Main causes' not found for page 'Causes of the French Revolution'.
[Step 1: Duration 1.27 seconds| Input tokens: 1,441 | Output tokens: 29]
Step 2
Calling tool: 'search_wikipedia' with arguments: {'query': 'Causes of the French Revolution'}
Observations: <long tool call output omitted>
[Step 2: Duration 1.27 seconds| Input tokens: 3,019 | Output tokens: 50]
Step 3
Calling tool: 'get_wikipedia_page' with arguments: {'page_title': 'Causes of the French Revolution', 'include_full_text': True}
Observations: <long tool call output omitted>
[Step 3: Duration 1.33 seconds| Input tokens: 7,446 | Output tokens: 79]
Step 4
Calling tool: 'final_answer' with arguments: {'answer': <final answer>}
Final answer: The causes of the French Revolution involve a complex combination of social, cultural, political, and economic factors:
1. Social Structure: French society was divided into three estates: the clergy (First Estate), the nobility (Second Estate), and the commoners (Third Estate). The third estate, which constituted 98% of the population, carried the burden of taxes and had little political power, leading to widespread discontent.
2. Financial Crisis: France's involvement in costly wars, such as the American War of Independence, deeply plunged the nation into debt. Inefficient taxation and financial systems compounded the issue, and attempts to reform taxes were blocked by the nobility-dominated parlements, creating a fiscal crisis.
3. Enlightenment Ideas: Ideas of liberty, equality, and fraternity, influenced by Enlightenment thinkers like Rousseau and Voltaire, fueled demands for political and social reform.
4. Economic Hardship: Poor harvests and subsequent increases in bread prices and cost of living placed greater strain on the already oppressed third estate. This economic hardship was felt acutely in urban centers, contributing to the mobilization of the sans-culottes and other groups.
5. Weak Monarchy: The diminishing power of the French monarchy under Louis XVI, coupled with ineffective financial management and a lack of reform, weakened the state's capacity to govern effectively. The monarchy's inability to manage or avert financial and social crises eventually led to widespread disillusionment and calls for change.
6. Cultural Change: The dissemination of Enlightenment ideas created a shift in societal values, challenging traditional authority and promoting new notions of governance and individual rights.
These factors, combined with specific events, served as catalysts for the revolution, resulting in a profound transformation of French society and government.
References:
Causes of the French Revolution - Wikipedia
[Step 4: Duration 8.16 seconds| Input tokens: 15,891 | Output tokens: 505]
Note that our agent prompt did not directly specify which tools to use when. The agent only got the list of tools with their description and devised a successful strategy on its own. Alas there was a small hiccup in the beginning: It tried to look up a non-existent section first. But it switched to using the search tool afterwards, nicely showing how resilient to errors modern agent toolkits are.
Conclusion
In this blog post, we have seen how the Model-Context-Protocol and its implementation offers a convenient way to provide LLM agents with relevant context information and functional abilities.
Underlying this design is a rather simple but powerful idea: Splitting off tool definitions from an agentic system makes them available across multiple agents. This simplifies and enhances agentic designs tremendously: SaaS providers or internal teams wishing to improve the integration of their products with LLM agents can now expose them via MCP servers and leverage a rich ecosystem of MCP clients. Developers of agentic system in turn can choose from a wide variety of MCP implementation to suit their needs. This is the primary reason why MCP servers have exploded in recent months (see e.g. this collection of MCP servers)
While MCP provides powerful capabilities for tool integration, it's worth noting that the security landscape around these servers is evolving quickly. As with any technology that exposes functionality to AI systems, security considerations are paramount. Anthropic recently added a recommended authentication workflow to the specification, addressing some concerns about unauthorized access. Meanwhile, security researchers continue to investigate potential vulnerabilities such as tool poisoning through prompt injection attacks. These security aspects merit deeper exploration, which we plan to address in a future blog post.