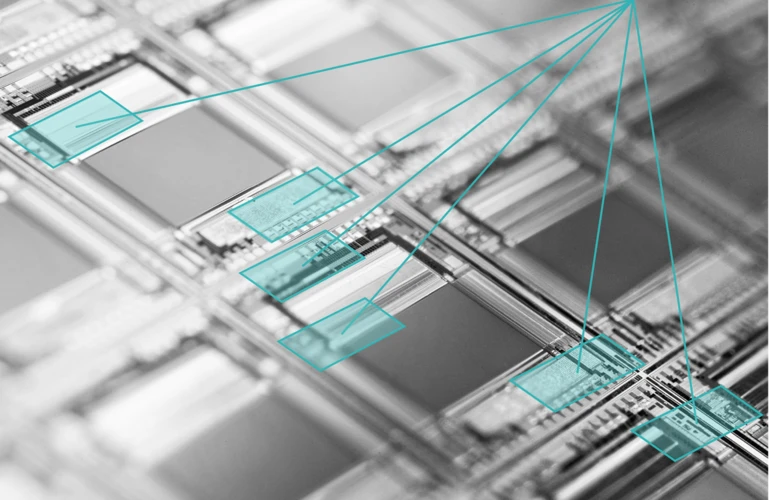
Echtzeit Kennzeichen-Erkennung und -Zuordnung
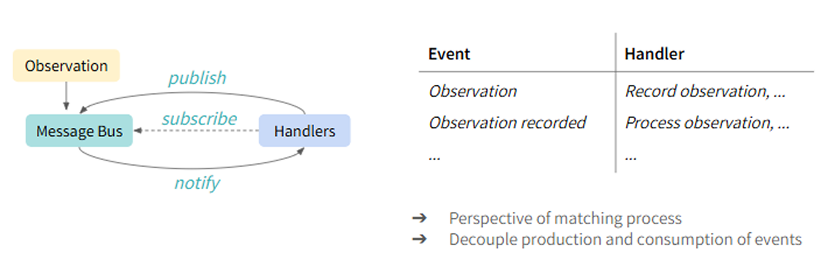
Zuordnung der Ausfahrt eines Fahrzeugs aus einem Parkhaus zur Einfahrt anhand von Kamera-Aufnahmen des Kennzeichens.
Input
Live-Stream von Kennzeichenbildern aus Parkhäusern in ganz Europa
Output
Zugeordnete Besuche (Einfahrt und Ausfahrt), korrigierter Kennzeichen-String und Confidence Score
Ziel
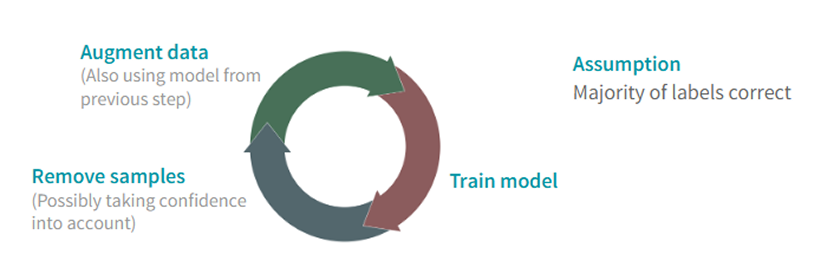
Erhöhung der erkannten Besuche, um die Anzahl abrechenbarer Parkhaus-Sitzungen (Besuche) zu steigern
Motivation
Herausforderung
Lösung