
OpenAI Codex: Warum die Revolution noch ausbleibt
In diesem Blogbeitrag erkläre ich, wie Codex von OpenAI funktioniert, und insbesondere, wie es sich von GPT-3 unterscheidet. Ich werde begründen, warum ich denke, dass Codex mit Vorsicht verwendet werden sollte und noch nicht bereit ist, den Softwareentwicklungsprozess zu revolutionieren.
Einleitung
Wenn Sie schon einige Zeit mit dem Schreiben von Code verbracht haben, haben Sie vielleicht die Erfahrung gemacht, dass selbst komplexe Software in kleinere Einheiten (z. B. Funktionen) zerlegt werden kann (und sollte), die generische Aufgaben erfüllen. Das Schreiben dieser kleineren Teile kann ziemlich lästig sein: Auch wenn es oft weder besonders herausfordernd noch interessant ist, ist es zeitaufwändig und hält Sie davon ab, sich auf die heikleren Teile des Softwareentwicklungsprozesses zu konzentrieren.
An dieser Stelle kommt OpenAIs Codex zur Rettung: Codex verspricht, einfache Funktionen auf der Grundlage natürlichsprachlicher Beschreibungen ihrer Funktionalität zu schreiben. Als Entwickler müssten Sie nur die Funktionssignatur und den Dokumentationsstring schreiben und Codex würde sich um die Implementierung kümmern.
Was Codex macht, ist nicht wirklich neu: Es ist nur ein Sprachmodell, das auf das Schreiben von Code spezialisiert ist. Tatsächlich ist es ein direkter Ableger von GPT-3. Wenn Sie noch nie von GPT-3 gehört haben oder sich nicht sicher sind, worum es sich dabei handelt, empfehle ich Ihnen, diesen einführenden Blogbeitrag zu lesen, bevor Sie fortfahren.
Codex vs. GPT-3
Codex ist eine finegetunte Version des voll trainierten GPT-3. Daher sollten wir einen Blick darauf werfen
welche Daten für das Finetuning von Codex verwendet wurden,
wie sich die Leistung zwischen den beiden unterscheidet.
Finetuning-Datensätze
Zum Finetuning von Codex sammelte OpenAI einen Datensatz aus öffentlichen GitHub-Repositories, der insgesamt 159 GB umfasste. Diese Codebasis wurde dann als "Text"-Korpus verwendet, um Codex auf die Sprachmodellierungsaufgabe "Vorhersage des nächsten Worts" zu trainieren.
Darüber hinaus wurde ein Datensatz sorgfältig ausgewählter Trainingsprobleme erstellt, die die Evaluationsaufgabe (siehe unten) besser widerspiegeln als der auf GitHub gefundene Code, und für das weitere Finetuning verwendet.
Codex Performance
Um herauszufinden, wie gut Codex Python-Funktionen eigenständig schreiben kann, hat OpenAI einen Datensatz mit 164 Programmieraufgaben namens HumanEval erstellt. Jedes Problem besteht aus einer Funktion (immer mit einem Dokumentationsstring) und einem umfassenden Satz von Unit-Tests.
Codex erhält einen Prompt, der nur die Funktionssignatur und den Dokumentationsstring enthält, und seine Aufgabe ist es dann, die Funktion so zu vervollständigen, dass sie alle Unit-Tests besteht (das Bestehen aller Unit-Tests gilt als Erfolg, das Nichtbestehen mindestens eines Tests als Misserfolg).

Um die Leistung zu messen, wird eine pass@k-Metrik verwendet, wobei k eine ganze Zahl ist: Für jedes Problem im HumanEval-Datensatz lassen wir Codex k verschiedene Ausgaben erzeugen (z.B. k=1, k=10 oder k=100). Das Problem gilt als gelöst, wenn mindestens einer der Outputs alle Unit-Tests besteht. Der pass@k-Wert ist dann der Anteil der Probleme, die gelöst wurden.
Falls Sie sich fragen, wie wir für ein und dieselbe Eingabeaufforderung k verschiedene Komplettierungen erhalten können und nicht k Mal dieselbe Komplettierung: Die Komplettierungen werden probabilistisch generiert, insbesondere wählen wir bei jedem Schritt (d.h. der Generierung des nächsten Wortes) nicht einfach das wahrscheinlichste nächste Wort, sondern ziehen eine Stichprobe aus der Wahrscheinlichkeitsverteilung von Codex für das nächste Wort (d.h. das wahrscheinlichste nächste Wort hat nur die höchste Chance, als nächstes Wort gewählt zu werden). Dies sorgt für Zufälligkeit.
Die pass@k-Bewertung scheint jedoch nicht sehr geeignet, um die Nützlichkeit von Codex in einer realen Situation zu beurteilen: Angenommen, wir berechnen die pass@k-Metrik für ein k>>1, sagen wir k=100. Selbst wenn die resultierende Punktzahl hoch ist, ist das Einzige, was man über die Leistung weiß, dass Codex ab und zu die richtige Antwort liefert, möglicherweise nach vielen erfolglosen Versuchen. Aber kann man sich in der Praxis darauf verlassen?
Zunächst einmal sollten Sie sich wahrscheinlich nicht blind auf Code verlassen, der von einem Blackbox-Algorithmus wie Codex erzeugt wurde, selbst wenn die gemeldeten Messwerte hervorragend sind. Dies gilt auch für den Code, den Sie selbst schreiben, weshalb häufig die Verwendung von Unit-Tests empfohlen wird. Aber Unit-Tests werden noch nützlicher, wenn Sie sich von Codex unterstützen lassen: Lassen Sie Codex einfach eine Vielzahl von Komplettierungen generieren, und filtern Sie dann alle heraus, die die Unit-Tests nicht bestehen. Wenn Sie genügend Unit-Tests geschrieben haben, bleiben nach dem Filtern nur die Funktionen übrig, die die gewünschte Aufgabe erfüllen. Für praktische Zwecke könnte es also ausreichen, dass Codex "hin und wieder" korrekt ist.
Hier ist die Leistung von Codex im Vergleich zum besten aller getesteten GPT-Modelle.
pass@1 |
pass@100 |
|
Codex-S 12B |
37.7% |
77.5% |
GPT-J 6B |
11.62% |
27.74% |
Arbeiten mit Codex
Derzeit gibt es zwei Möglichkeiten, Codex zu nutzen: entweder über die API von OpenAI (mit einer praktischen Benutzeroberfläche namens "Playground"), die ich zum Glück ausprobieren konnte, oder über GitHub Copilot, eine IDE-Erweiterung, die kontinuierlich Komplettierungen vorschlägt. Für beide gibt es derzeit Wartelisten.
Wenn Sie ein Gefühl dafür bekommen wollen, was Codex alles kann, dann empfehle ich Ihnen, sich die OpenAI Codex Live-Demo anzusehen:
Ich stimme zu, dass der Codex erstaunlich ist. Allerdings möchte ich mich hier eher auf die Grenzen von Codex und seinen tatsächlichen praktischen Wert konzentrieren.
Einschränkungen
In der Veröffentlichung, in der Codex vorgestellt wird, weist OpenAI auf zwei wichtige Einschränkungen hin:
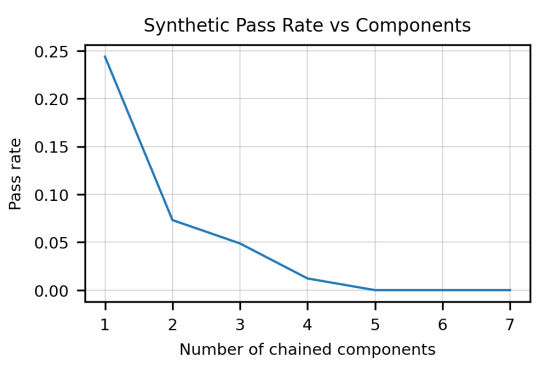
Es besteht eine negative Korrelation zwischen der Komplexität des Doc-Strings und der Erfolgsquote. Die Komplexität des Doc-Strings wird als Anzahl der darin enthaltenen "verketteten Komponenten" quantifiziert, wobei eine einzelne Komponente eine Anweisung wie "convert the string to lowercase" ist. Mit anderen Worten: Codex ist nur gut darin, einfache Funktionen zu schreiben (siehe Bild unten).
Codex ist nicht darauf trainiert, qualitativ hochwertigen Code zu erzeugen, sondern den "durchschnittlichen" Code, der auf GitHub zu finden ist, nachzubilden. Das bedeutet, dass Codex weit verbreitete schlechte Programmiergewohnheiten übernimmt und aufrechterhält. (Dieses Problem ist vergleichbar mit Sprachmodellen, die in ihren Trainingsdaten vorhandene Stereotypen erlernen ).
Diese beiden Einschränkungen haben Auswirkungen darauf, wie Codex in der Praxis eingesetzt werden sollte: Erstens ist es notwendig, die gewünschte Funktionalität in einfache Funktionen zu zerlegen, deren Docstrings Codex verarbeiten kann.
Dies ist immer noch ein ziemlicher Aufwand und oft nicht trivial - sicherlich werden menschliche Softwareentwickler in naher Zukunft nicht überflüssig werden.
Zweitens: Selbst wenn Codex es schafft, Funktionen zu generieren, die alle Unit-Tests bestehen - wenn Sie nicht nur an funktionierendem, sondern auch an prägnantem, effizientem und sicherem Code interessiert sind, dann sollten Sie doppelt überprüfen, was Codex ausgibt. In manchen Fällen kann dies mehr Zeit in Anspruch nehmen, als den Code selbst zu schreiben (oder ihn von StackOverflow zu kopieren).
Ankereffekt und Automatisierungsbias
In einem Codex gewidmeten Blog-Beitrag weist Jeremy Howard auf eine andere Art von Problem hin: Ankereffekt und Automatisierungsbias. Als Menschen neigen wir sowohl dazu, uns zu sehr auf die erste Information zu verlassen, auf die wir stoßen (Ankereffekt), als auch auf automatisierte Vorschläge (Automatisierungsbias) - selbst wenn wir uns der Gefahren bewusst sind und versuchen, skeptisch zu sein. Beide Vorurteile gelten für den von Codex vorgeschlagenen Code. Daher neigen wir dazu, uns zu sehr auf Codex-Vorschläge verlassen - selbst wenn wir wissen, dass sie oft falsch sind.
Ein Beispielfall
Betrachten Sie die folgende Funktion:
def count_right_numeric(cell_indices: Tuple[int, int],
df: pd.DataFrame) -> int:
"""Counts how many cells containing numbers are to the right of a given \
cell.
Args:
cell_indices (Tuple[int, int]): Indices of a cell.
df (pd.DataFrame): DataFrame containing the cell.
Returns:
int: Number of numeric cells.
"""
row, col = cell_indices
numeric_count = 0
for i in range(col + 1, len(df.columns)):
if df.iloc[row, i] is not None:
if isinstance(df.iloc[row, i], str) \
and df.iloc[row, i].isnumeric():
numeric_count += 1
elif isinstance(df.iloc[row, i], float) \
or isinstance(df.iloc[row, i], int):
numeric_count += 1
return numeric_countDie Signatur und der Doc-String sind einer Funktion entnommen, die wir in einem echten Projekt verwendet haben (allerdings leicht umformuliert). Gegeben ein Pandas DataFrame und eine Zelle darin, spezifiziert durch ihre Indizes, wollen wir die Anzahl der Zellen in der gleichen Zeile, aber rechts von der gegebenen Zelle wissen, die nur Zahlen enthalten.
Der Körper der obigen Funktion wurde tatsächlich von Codex generiert ("best of 20" mit Temperatur 0,5, erster Versuch) - und tut genau das, was er soll. (Zugegeben, es gibt einige Unklarheiten in der Doc-String-Anweisung - was bedeutet es genau, "Zahlen zu enthalten"? Codex entscheidet sich für "enthält nur Zahlen" - was auch beabsichtigt war.)
Jetzt können wir mit dem zufrieden sein, was Codex uns gibt, und weitermachen. Oder wir können uns fragen, ob die Implementierung von Codex wirklich die beste Lösung für das Problem ist. Die folgenden zwei Codezeilen erfüllen die Aufgabe ebenfalls, allerdings ohne die umständliche for-Schleife und Fallunterscheidungen:
right_of_cell = df.iloc[cell_indices[0], cell_indices[1] + 1:]
return pd.to_numeric(right_of_cell, errors="coerce").notnull().sum()Aufgrund der Auswirkungen von Ankereffekt und Automatisierungsbias könnten wir geneigt sein, uns an die Vorschläge von Codex zu halten, auch wenn es bessere Alternativen gibt. Dies würde zu schlechterem Code führen. (Welcher der beiden obigen Funktionskörper zu bevorzugen ist, hängt natürlich vom Kontext und auch vom Geschmack ab.)
Generell scheint es mir, dass die Komplettierungen von Codex oft zu lang sind und praktische eingebaute Funktionen wie to_numeric nicht nutzen.
Fazit
Codex ist ein faszinierendes Tool, das den aktuellen Stand von Deep Learning veranschaulicht. Für praktische Zwecke sollte es jedoch mit Vorsicht verwendet werden, da die Verwendung von Codex dazu führen kann, dass Sie schlechteren Code schreiben.