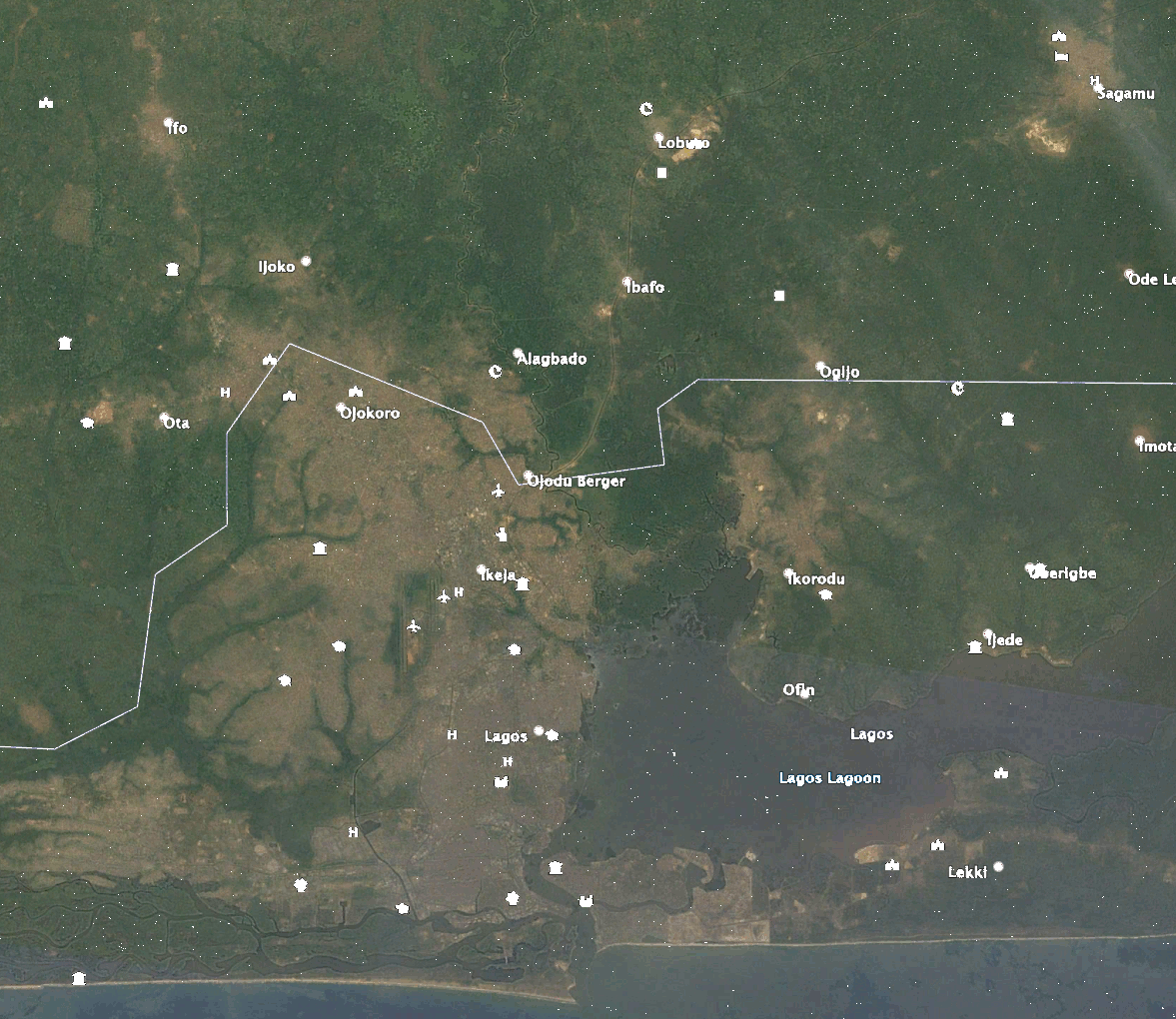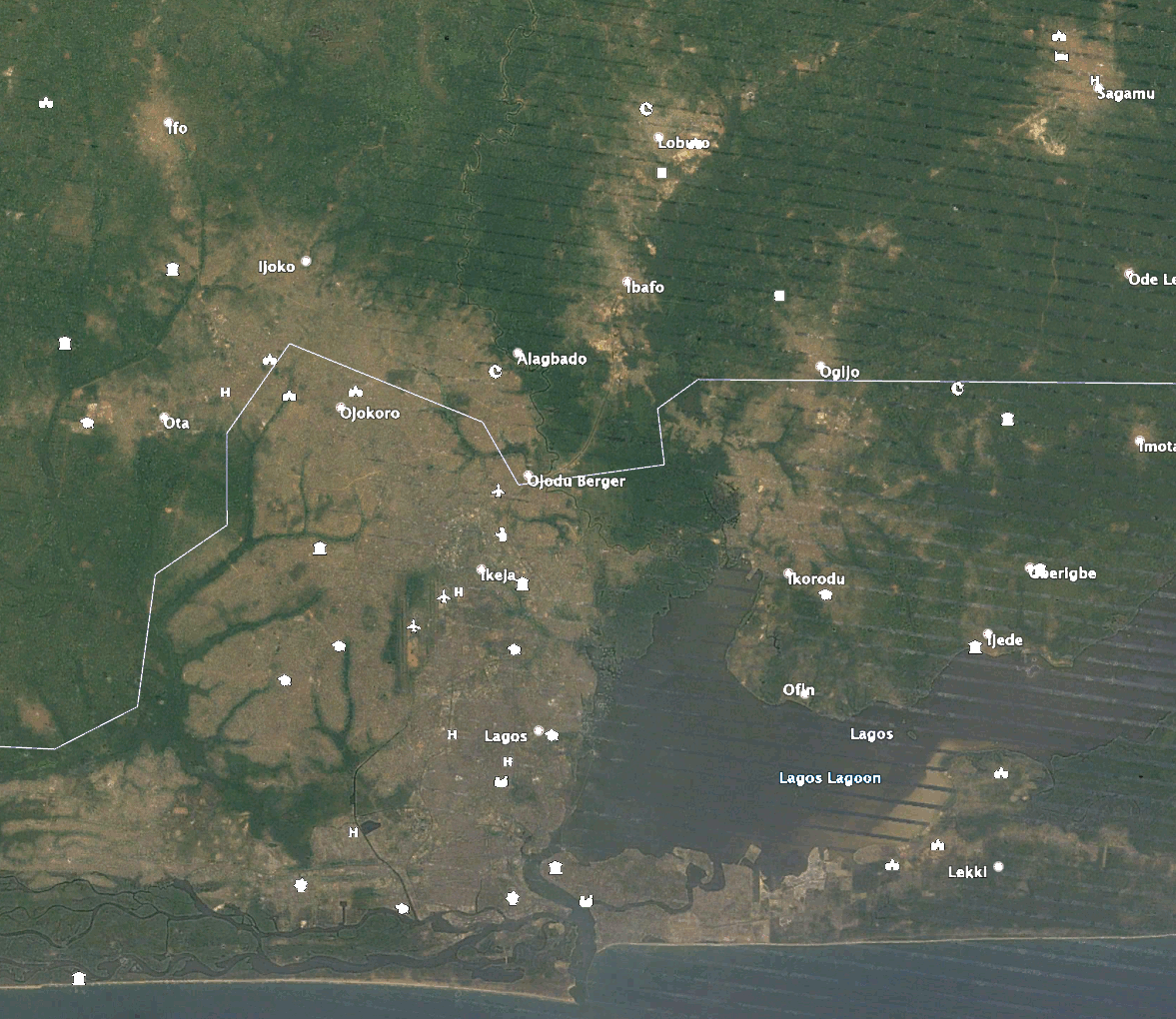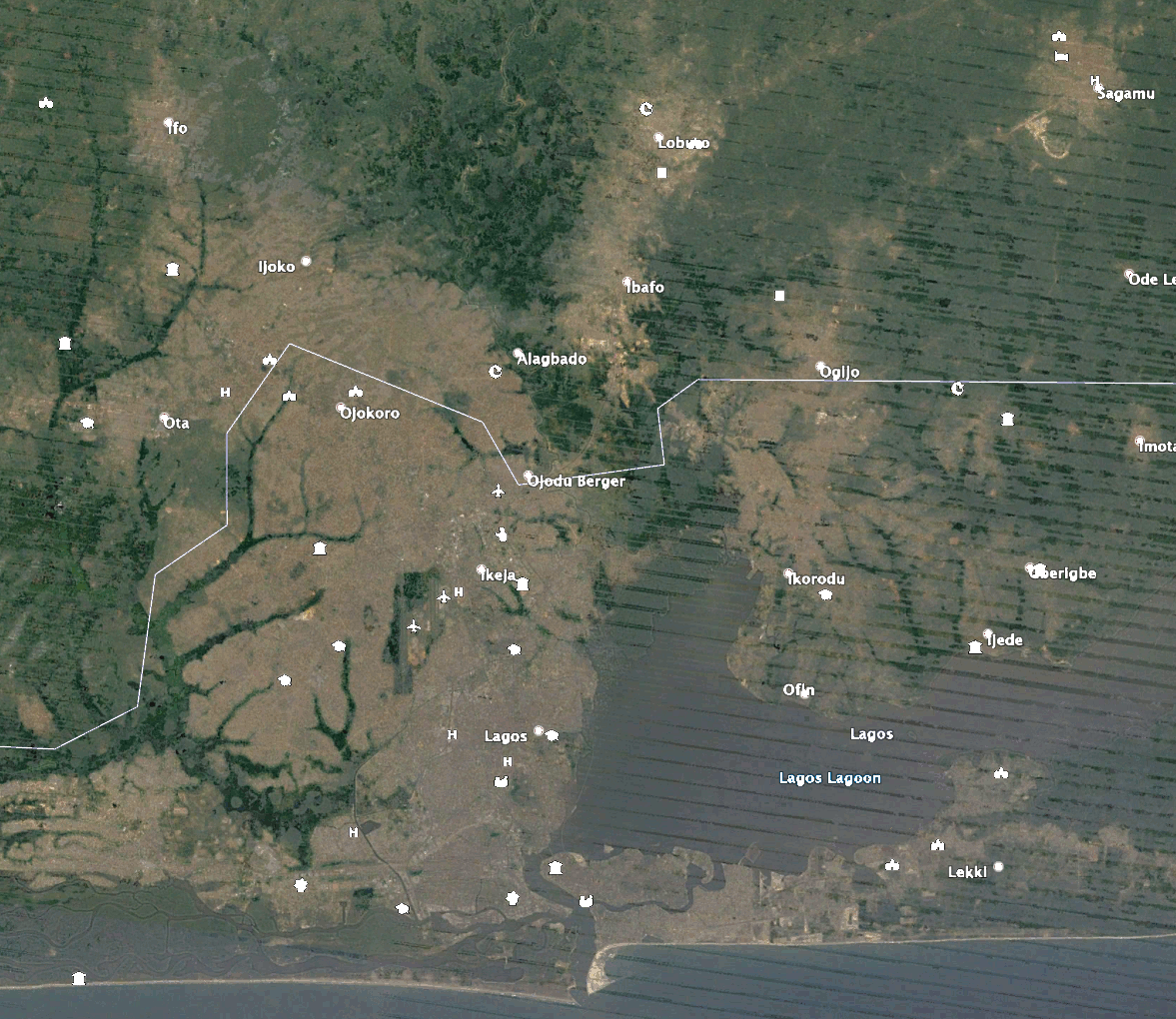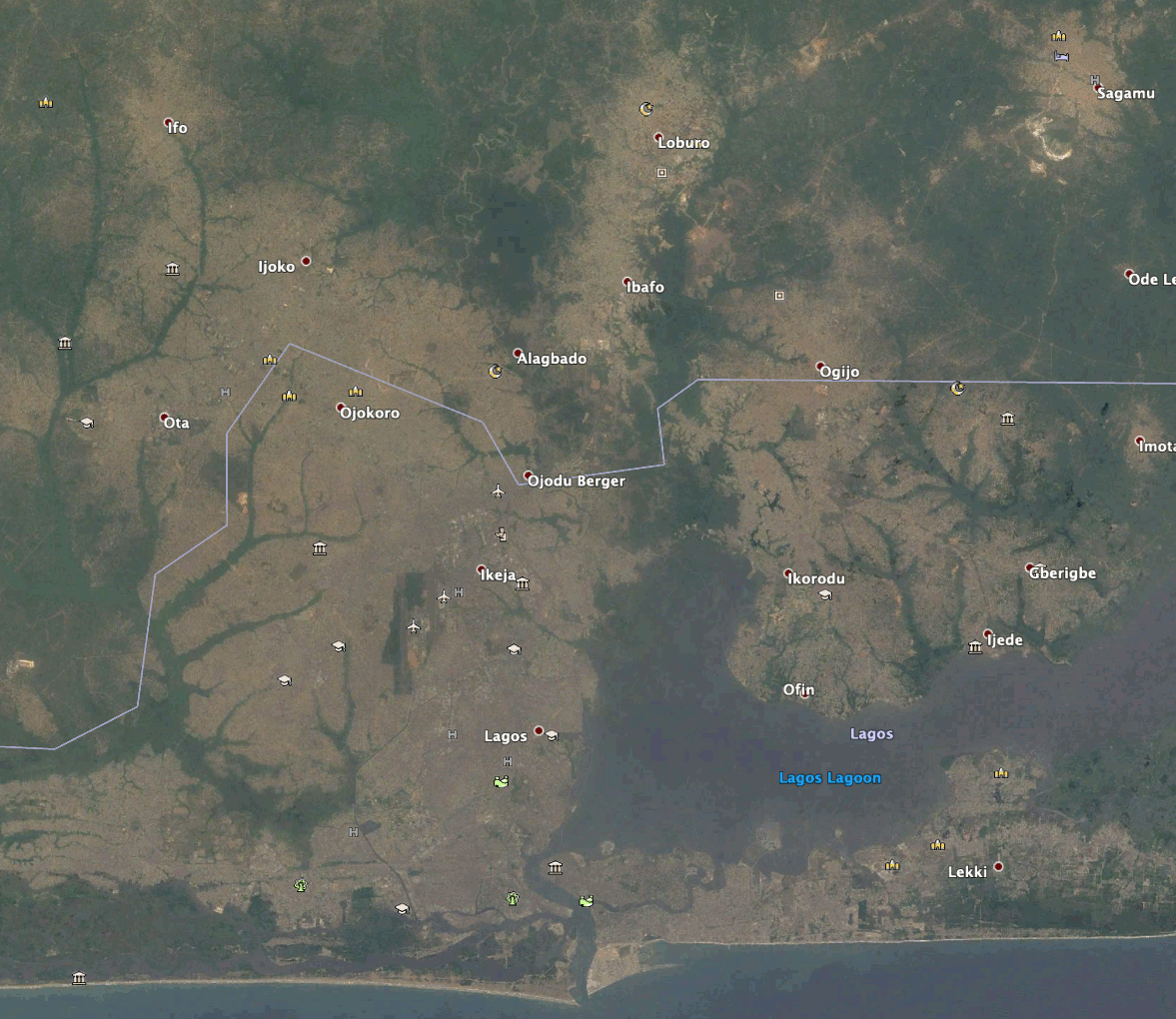
Die Bilder veranschaulichen die Veränderung der städtischen Ausdehnung von Lagos, Nigeria, im Laufe der Zeit. Die Zeitschritte reichen von weiß (2011) bis rot (2019), da immer neuere Vorhersagen gemacht wurden. Die vergrößerten Bilder haben die gleichen Zeitschritte wie in der Legende der Übersicht und heben bestimmte Bereiche der neuen Entwicklungen um Lagos hervor.
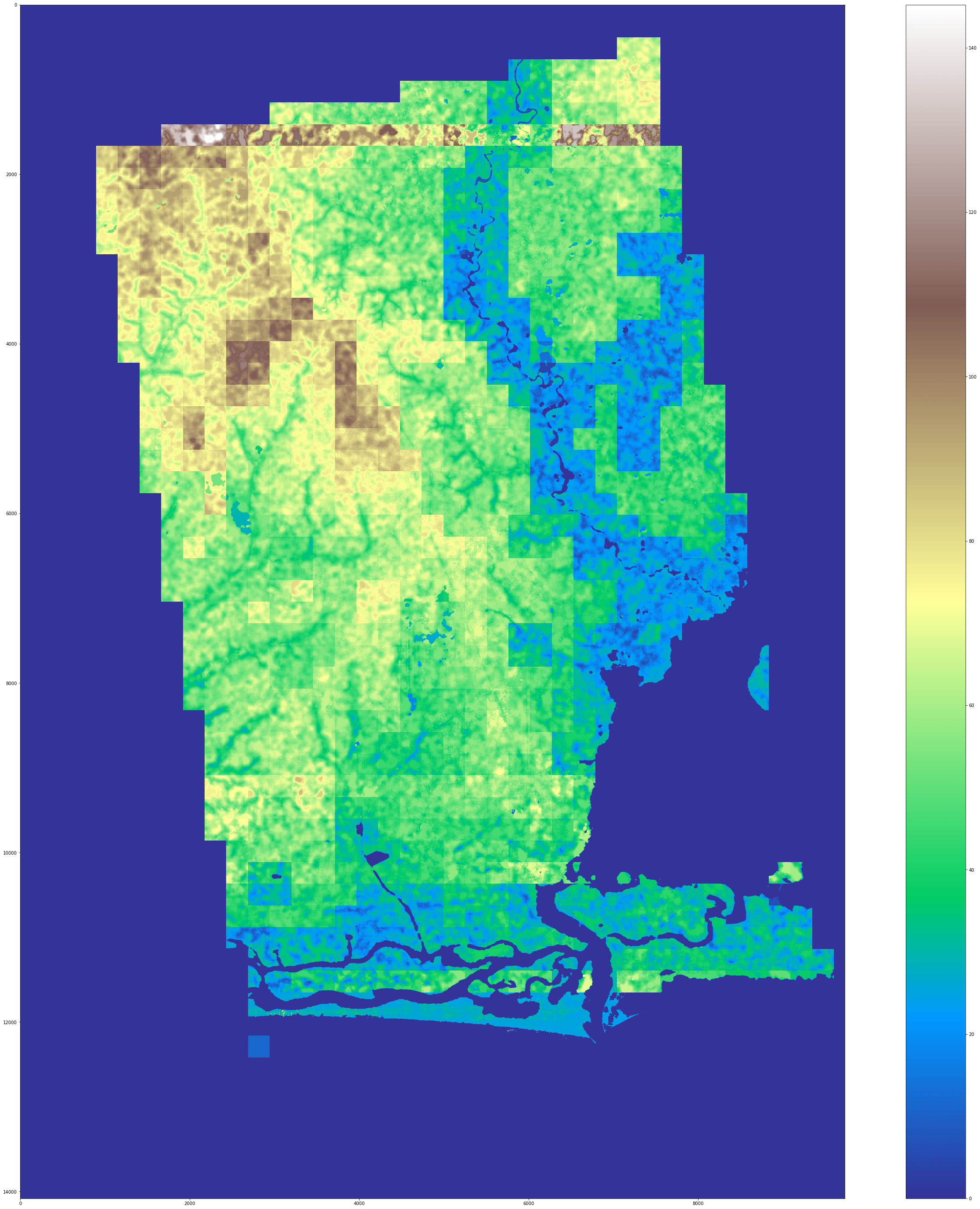
Nachdem wir das Im2Height-Modell in zahlreichen verschiedenen Konfigurationen trainiert haben, ziehen wir aus unseren Ergebnissen eine Reihe von Schlussfolgerungen. Das Training mit dem Structural Similarity Index Measure (SSIM) als Verlustfunktion führt zu den besten Ergebnissen unserer Experimente. Auch wenn das Modell an einigen Stellen sehr große Fehler ausgibt, sind diese mit Hilfe einer einfachen Anomalieerkennung als Nachbearbeitungsschritt oft recht leicht vermeidbar. Die Verwendung des SSIM-Verlusts ergab nicht nur die besten SSIM-Ergebnisse (0,5 auf dem Trainingsset, 0,03 auf dem Testset) im Vergleich zur Verwendung des Verlusts des mittleren quadratischen Fehlers (MAE) (0,01 auf dem Trainingsset und 0,001 auf dem Testset), sondern die Beseitigung der Anomalien verbessert auch die Ergebnisse in einem besseren MAE in unseren Experimenten (Training: ±15m, Test: ±18m vs. ±18m bzw. ±21m).
Diese Fehler sind jedoch immer noch zu groß, um kleinere Veränderungen, die über mehrere Jahre hinweg auftreten, sinnvoll zu erkennen (von denen die meisten deutlich unter dieser Fehlergröße liegen dürften). Da sich diese Ergebnisse von der Originalarbeit unterscheiden, möchten wir einige mögliche Gründe für dieses Ergebnis skizzieren: Die geringe Auflösung der Radardaten ist die wahrscheinlichste Quelle dieses Fehlers (5x5m gegenüber 0,7x0,7m in der Originalarbeit), die in Kombination mit dem Mangel an visuellen Hinweisen wie Schatten usw. die Möglichkeit, aus den Daten zu lernen, drastisch reduziert. Unten in der Galerie finden Sie einige visuelle Ausgaben der von Im2Height erstellten Vorhersagen.